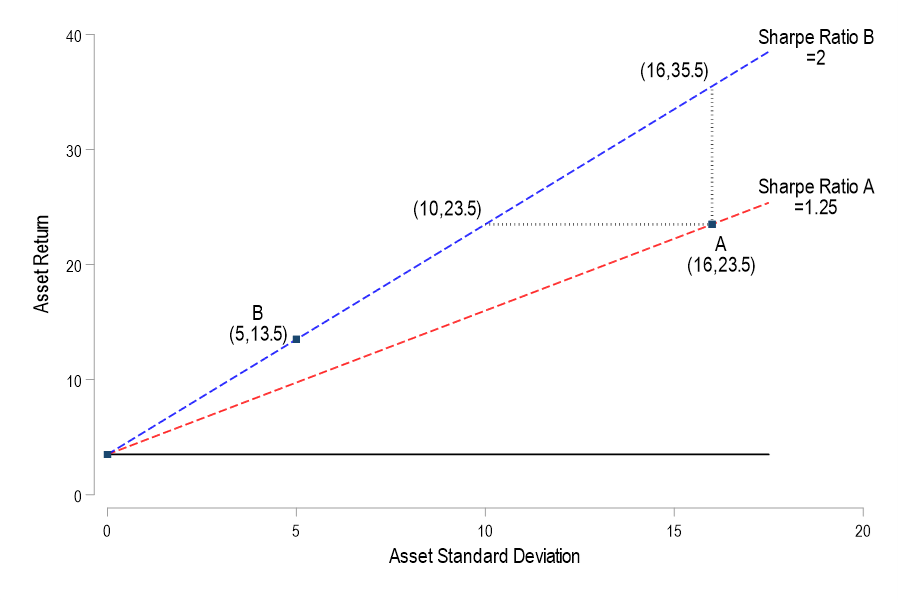
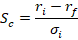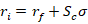Much of what economics has to say about tariffs comes from microeconomic theory. But it’s mostly sectoral in nature. Trade theory has some insights. But the effects on the whole of an economy are either small, specific to undiversified economies, or make representative agent assumptions that avoid much detail. Given that the economics profession has repeatedly said that the Trump tariffs would contribute to inflation, it seems like we should look at the historical evidence.
Lay of the Land
Economists say things like ‘competition drives prices closer to marginal cost’. Whether the competitor lives abroad is irrelevant. More foreign competition means lower prices at home. But that’s a partial equilibrium story. It’s true for a particular type of good or sector. What happens to prices in the larger economy in seemingly unrelated industries? The vanilla thinking that it depends on various elasticities.
I think that the typical economist has a fuzzy idea that the general price level will be higher relative to personal incomes in some sort of real-wages and economic growth mental model. I don’t think that they’re wrong. But that model is a long-run model. As we’ve discovered, people want to know about inflation this month and this year, not the impact on real wages over a five-year period.
Part of the answer is technical. If domestic import prices go up, then we’ll sensibly see lower quantities purchased. The magnitude depends on the availability of substitutes. But what should happen to total import spending? Rarely do we talk about the expenditure elasticity of prices. Rarely do we get a simple ‘price shock’ in a subsector. It’s unclear that total spending on imports, such as on coffee, would rise or fall – not to mention the explicit tax increase. It’s possible that consumers spend more on imports due to higher prices, or less due to newly attractive substitutes. The reason that spending matters is that it drives prices in other parts of the economy.
For example, I argued previously that tariffs reduce dollars sent abroad (regardless of domestic consumer spending inclusive of tariffs) and that fewer dollars will return as asset purchases. I further argued that uncertainty makes our assets less attractive. That puts downward pressure on our asset prices. However, assets don’t show up in the CPI.
According to the above discussion, it’s unclear whether tariffs have a supply or demand impact on the economy. The microeconomics says that it’s a supply-side shock. But the domestic spending implications are a big question mark.
What is a Tariff Shock?
That’s the title of a recent working paper from the Federal Reserve Bank of San Francisco. It’s a fun paper and I won’t review the entirety. They start by summarizing historical documents and interpreting the motivation of tariffs going back to 1870. They argue that tariffs are generally not endogenous to good or bad moments in a business cycle and they’re usually perceived as permanent. The authors create an index to measure tariff rates.
Here’s the fun part. They run an annual VAR of unemployment, inflation, and their measure of tariffs. Unemployment in negatively correlated with output and reflects the real side of the economy. Along with inflation, we have the axes of the Aggregate Supply & Aggregate Demand model. Tariffs provide the shock – but to supply or demand?. Below are the IRF results:
Continue reading