Abstract: Language models increasingly settle real resource tradeoffs on behalf of principals yet their economic preferences remain unobserved. We demonstrate their generation rule is isomorphic to the random utility model of discrete choice. This allows internal logit scores to structurally identify preferences. Estimating risk attitudes across twelve models in a portfolio task reveals universal but heterogeneous risk aversion. Although models reject strictly dominated options, their elicited preferences fail invariance tests and violate the independence of irrelevant alternatives across varying experimental prompts. Finally, fine tuning establishes that a principal can explicitly engineer a target risk attitude.
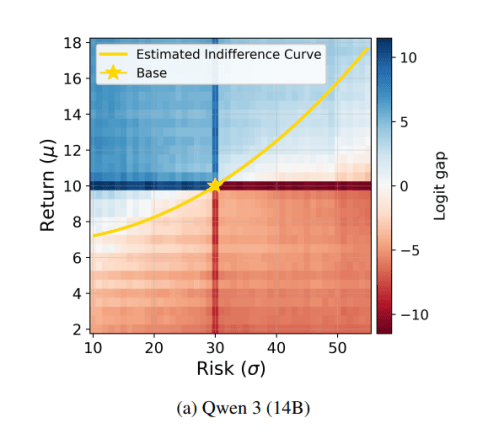
I hope you will refer to the manuscript for details, but I will share one picture here. This is panel (a) of Figure 3: Empirical indifference curves for open-weight models mapped over the portfolio space.
In simple language, what the red/blue picture shows is that the Qwen language model is picking the portfolios that offer more money (in expectation, with a distaste for excessive risk). That’s basically what a rational actor should do. We find that the language models make fairly consistent choices and rarely violate the monotonicity requirement for a well-behaved utility function.
How we describe this figure in the paper: “Starting from a base bundle with expected return µ = 10 and risk σ = 30, we sweep over the dense grid of alternative portfolios from our experimental protocol and record the position-corrected logit gap between each grid portfolio and the base. The yellow dashed line overlays the indifference curve implied by the mean-variance structural estimates, and the heatmap colors encode the sign and magnitude of the logit difference, with blue regions preferred to the base and red regions dispreferred. Several patterns emerge from these plots. All six models produce upward-sloping indifference curves, confirming that higher risk must be compensated by higher expected return.”
We think this basic research on behavior is important, for alignment research and for business applications with delegating work to AI agents. The first question to ask, before testing whether we can impose our preferences on AI agents, is whether those agents have preferences at all in a consistent sense.
Suggested citation: Buchanan, J., & Foster, J. (2026). The innate economic preferences of language models [Preprint]. arXiv. https://doi.org/10.48550/arXiv.2607.26288
There has been a lot of shade thrown at the United Kingdom recently from economists and political scientists. Economic growth has gone down the tubes and there have been six prime ministers over the past decade. As an American, I didn’t really know if that was a lot. The social media says that we’ve had a lot of turnover recently. Is six prime ministers in ten years a lot in the UK’s parliamentary system? I grew up watching Tony Blair on TV for a ten-year stretch. But I had no context for the historical norm or whether there is any precedent. Here I look at the data.
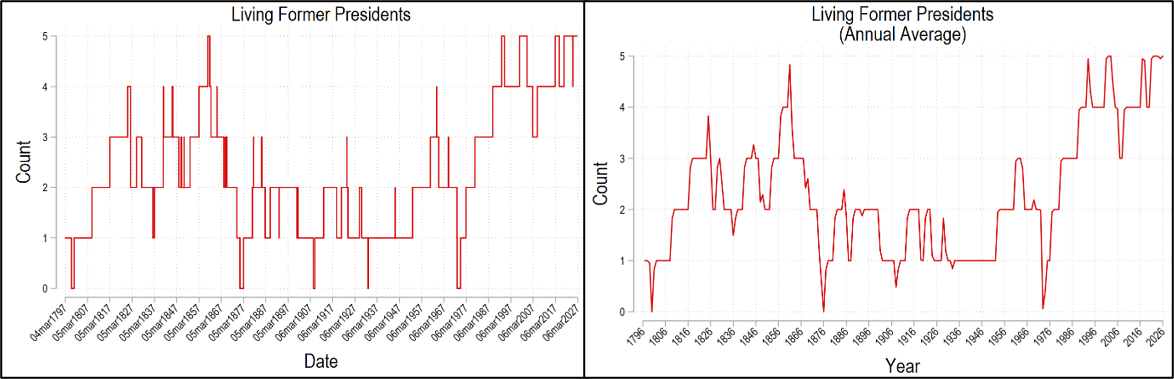
Right now, there are a record number of former prime ministers still living (PM). Prior to the recent spike, the maximum number of living people who had left office was five. Right now in 2026, there that number is nine! And if the current PM, Andy Burnham, follows the recent trend of short stints in office, then they’ll hit ten. As an American, it’s hard for me to imagine having 10 living former presidents. According to the below charts, the British are probably a bit jarred too!
Why So Many?
In last week’s post I noted that we’re tied for the most living former presidents. But truly, the UK’s numbers are what inspired me to look at this topic in the first place. To recap, the number of living ex-executives can be caused by 1) Longer lifespans, 2) Leaving office at a younger age, and 3) More unique executives. In the US, being currently tied for the record is overwhelmingly driven by longer lifespans. What about the UK?
What could be better than creating data so valuable that an institution is happy to host and update it forever, like the Sean Lahman baseball database?
Creating data that sells for $375 million, like the Center for Research in Security Prices. University of Chicago professors assembled this series of finance datasets over decades, starting in 1960 with an effort to track every transaction of every publicly traded security. U Chicago sold CRSP to Morningstar last year for $375 million.
Why could they sell it for so much? It helps to be working in finance, where the willingness to pay is the highest. It also represents 65 years of work from what became a large team that included Nobelists like Eugene Fama. The data was valuable enough to become widely used by key institutions even though CRSP charged for it:
Today, $3 trillion in fund assets are linked to CRSP Market Indexes, including U.S. equity ETFs run by Vanguard, and more than 600 subscribers across 35 countries use CRSP Research Data Products.
Did U Chicago sell CRSP at the right time? On the one hand, I wonder if this was a fire sale driven by federal grant cuts putting pressure on the U Chicago budget. On the other hand, assembling datasets like this is only going to get easier in the age of AI, so perhaps Chicago sold at the top.
For now though there is still an edge in having restricted datasets that AIs haven’t trained on and can’t access. When I ask myself what advantage my human research assistants have over AIs in 2026, the most obvious answer is that they can legally access restricted databases like CRSP or, in my current case, HeinOnline.
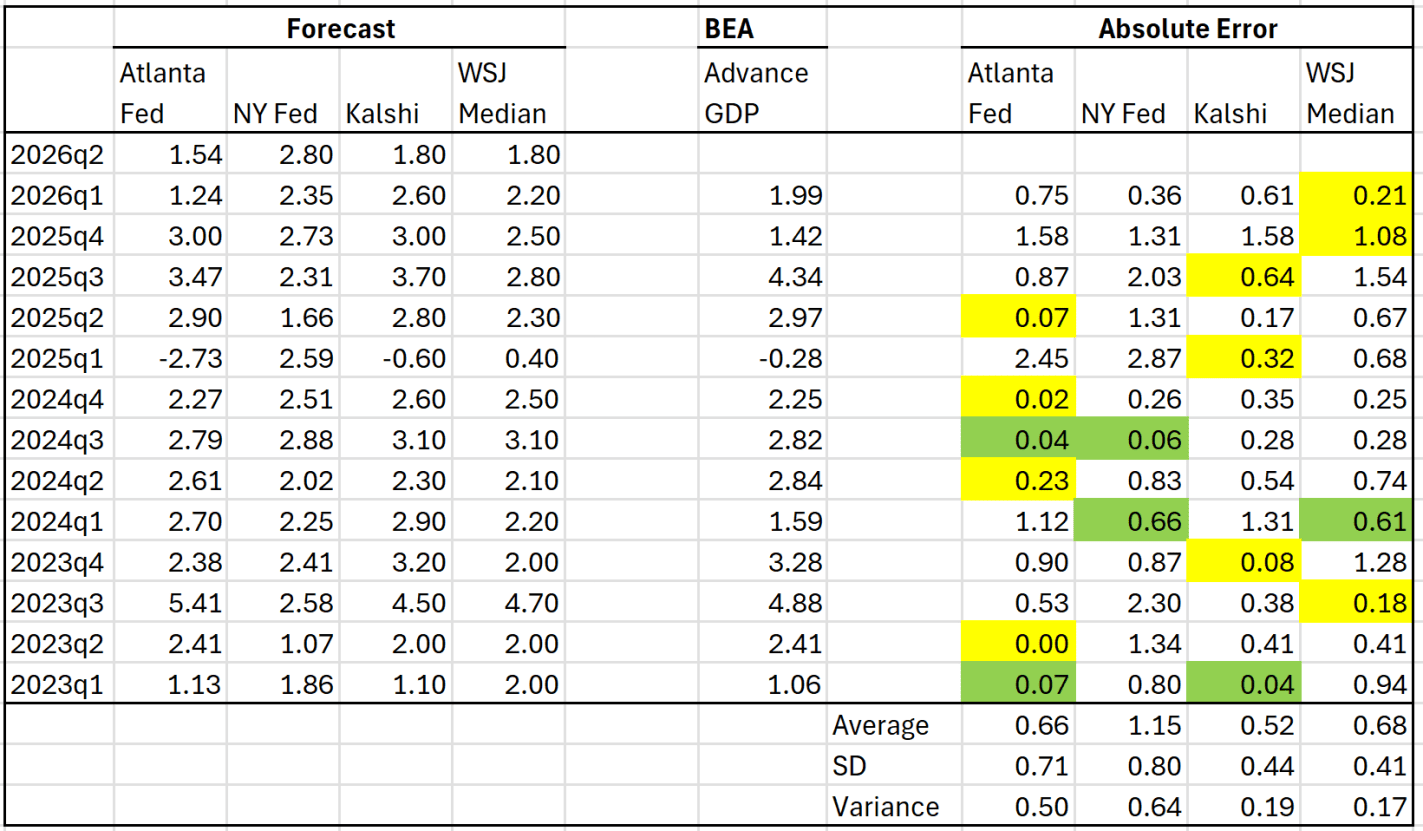
GDP growth data for the second quarter of 2026 comes out tomorrow. As I have been doing for the past several quarters, here is an update on two model forecasts (Atlanta and NY Feds), betting market implied estimates (Kalshi), and an average from a survey of economists (WSJ). Yellow shading indicates which forecast was closest to correct in each quarter (green is if two forecasts were about the same).
In the past two quarters, the WSJ survey has been the best predictor. The Atlanta Fed GDPNow model used to be my favorite, but it has performed pretty poorly in the past 3 quarters. As I have discussed before, an average of the Atlanta Fed and Kalshi was better than any single predictor. I continue to include the NY Fed estimate, even though it seems to be a very terrible predictor, because some people like to talk about it.
The Atlanta Fed, Kalshi, and the WSJ survey are all showing very similar estimates for Q2. If I was a betting man, I would bet on 1.8% for the BEA advance estimate.
I first learned computer programming about 1974, using FORTRAN running on an IBM 360 system that, yes, filled a whole room. And yes, my source code existed in the form of a stack of cards with holes punched in them, which got run through a physical card reader. FORTRAN and similar old-school languages were efficient (b/c computer resources were so constrained) and syntactically simple for solving well-specified problems.
C++ started to become popular in the 1980s, and Java in the 1990s. A big part of their appeal was that they were “object-oriented programming” (OOP) languages. I repeatedly asked my computer-programming professional friends back then to help me understand the difference between OOP and conventional Fortran type programs. They would get misty-eyed and rhapsodize about how their program components were modularized. I guess I just failed to ask the right questions, because I never could understand why what they were talking about was so very much better or different than a good clean FORTRAN program, where most of the work was compartmentalized into well-defined functions and sub routines.
So I had a good talk with Claude about all this, and achieved enlightenment.. The differences seem to come down to a couple of key concepts:
(1) Data Compartmentalization
In FORTRAN, you can modularize the data manipulation steps into subroutines, but the data tends to be more in common. Thus, for a very large programs, it is hard to keep some far-distant subroutine from accidentally altering your data. But with OOP, the data and the manipulation methods are “encapsulated” into one airtight thing, so no outside routine can mess with that data.
(2) More Robust Relations Among Chunks of Code
With OOP, there is also a feature called “inheritance”, where some new method can take advantage of an existing method, in a cleaner way than (in the FORTAN world) having a new subroutine call an existing subroutine, which would involve explicitly passing a bunch of parameters back-and-forth (which is very easy to mess up).
For doing fairly straightforward scientific calculations, even big ones, I think FORTRAN is still easier and more efficient. But for modern financial programs, involving millions of lines, written by huge teams of people that cannot all talk to one another, the win goes to OOP. Besides C++ and Java (still popular), in OOP we now have C# (standard for many Windows and gaming applications), and the crowd favorite, Python.
(That’s about it simply as I could put it, without getting long-winded and technical… If you want more details, you can always ask my buddy Claude)
It is very good. See it in IMAX if you can, though I strongly recommend wearing concert ear plugs (i.e. the kind that let you still hear dialogue clearly). Minor spoilers ahead, if such a thing is even possible with a 2,800 year old epic poem.
The themes of the adaptation/translation are wonderful and poignant. The layers of shame and trauma never, to me, felt forced. As someone who spends a lot of time thinking about the fragility of civiliation as solution to the grand collective action problem, the idea that a single betrayal can unravel an entire society and that the “heroic” cenceiver of that betrayal might feel shame, well, that is not without current relevance.
So yes, the film as story is great. But, sitting here now 4 days after viewing it, what I find myself constantly returning to is the sheer, overwhelming competence of the film. The acting, costuming, set and prop design, lighting, sound design, editing, musical scoring. It all just worked. As a champion of practical effects, the texture of the film was transporting. Yes, there is CGI, but it blends in seemlessly, always complementing the practical elements in a way to never let the imagery fall into the uncanny valley. The final product coordinates a vast array of individual and team efforts that, together, create an experience that always felt purposeful, decisive, and real.
Given the small city that must be erected, populated, struck, and moved to create each element of a film like The Odyssey, it’s a great reminder of what can be accomplished when all of the people involved actually and truly know what they are doing. In an age of carnival barkers and con men, there is nothing more epic than grand demonstrations of competence.
Zachary Bartsch: “A skill can be just plain text written conversationally, it can be a list of rules, mathematical expressions, or even the foundational code that you want your AI to readily modify and apply. Essentially, saying ‘skill’ is the same as saying ‘pre-prompting’ with various degrees of specificity. Rather than writing a prompt each time, you can recycle a set of prompts that you’ve stored in a file. That’s all that a skill is.”
Plus, Zachary provided some useful history of “Explainer text files”
“Not a single one of these foods is an ‘incomplete protein’. Yes, the mass that you’d need to eat differs, but there is not much that is exciting about legumes and grains as a combination.”
Anyone who has gone grocery shopping in 2026 knows this is the year of protein.
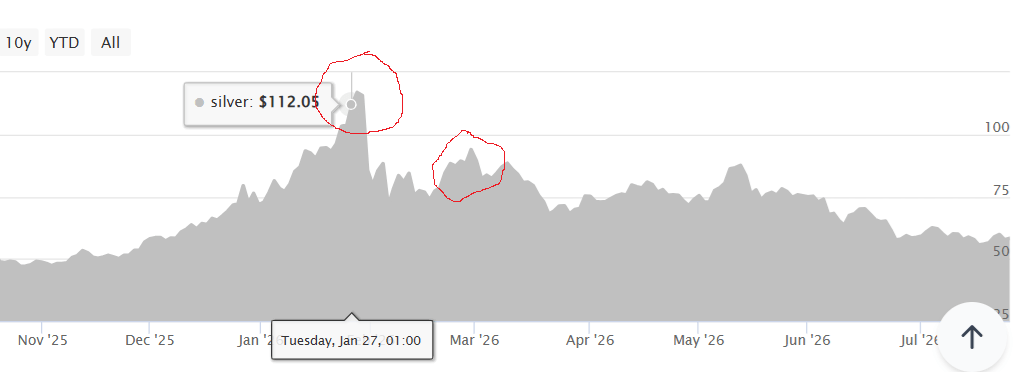
Out of curiosity, I checked the price. Within a week of this post, the price of silver had actually gone up. But after a final peak in late January, the price has declined. As of today, it is down from any of the prices posted in January of 2026.
“Gleeful researchers, competitors, and hackers promptly downloaded zillions of copies. Anthropic issued broad copyright takedown requests, but the damage was done.”
He talks about the referee process, since that is where the main decisions happen, as much as the “writing process.” No one has all the answers, but Mike is doing us all a favor by getting some of this real talk out in the open. Please comment if you have more ideas on where to go from here.
I’ve seen chatter about this topic on Twitter/X, but I’d love to see some more blog posts from tenured folk because it helps with the hidden curriculum problem.
“Would you have guessed that in the “good old days” of the 1950s and 1960s, the average US family was spending 30-40% of their income on food and clothing, something that today we spend barely over 10% on? To understand the challenges we face today, it’s important to have the context of how bad the past was.”
Jeremy has been telling this story for years. Interestingly, world cup tourist discourse seemed to push a few more people over the fence (why hadn’t they just read our blog?). Most Americans are rich.
Since the ChatGPT launch, I have heard conflicting stories on the impact of AI on white collar jobs such as software engineering. There have been layoffs and, for example, ex-Meta employees who struggle rematch in at their old salary. I have also heard claims that the demand for software engineers is actually increasing, perhaps because AI makes them more productive.
The problem echos Makowsky’s post, which ultimately rests on readers and the referee process. I like to say “readers are that which is scarce,” meaning that it’s not difficult to produce writing.
Blogs are not niche anymore. More people than ever, including many researchers at top schools, have decided to start a Substack. Of course, peer-reviewed and prestige-published research still has a primary place in the discourse. Many of the blog posts are ABOUT the primary objects of research.
I saw something called InTheWeights in 2026 that made me think folks at research schools might be strategic in starting to blog now. ChatGPT reads our blog. One reason I think that to be true is that some of our reader traffic comes from ChatGPT.com and Claude. I think our work is getting repackaged as LLM answers to millions of people, some small percentage of those answers provide attribution to us, and then a small sliver of those answers results in users clicking over to us as the primary source for an answer.
It will be a long time before tenure decisions are based on where you are In the Weights. But our crew would do well on that metric. Our work is legible to AI because we have been blogging ungated here for years.
If you count president Trump, the number of living former presidents is at a historic high of five (Clinton, G.W. Bush, Obama, Trump, Biden). The number of living ex-presidents can increase for three reasons. 1) More people becoming president, 2) ex-presidents having longer lifespans, and 3) presidents leaving office earlier in life. Why do we have so many right now?
The historical maximum number of people who both 1) leave office and 2) live simultaneously with others is five. It first happened in 1861 when Abraham Lincoln (16th) was president for just under a year before John Tyler (10th) died in 1862. Since then, the number of living ex-presidents has been mostly below four if not below 3. The figures below graph the number of people living who have been US president. The left graph uses daily data and the right uses the annual average (weighted by day).
In fact, besides Washington, we’ve had four other periods when there were ZERO ex-presidents living. The first was under Grant (18th). This changes my perspective of that period. Living ex-presidents provide a sense of continuity – that something from the past continues today. They give us hope that our country will continue into the future. Grant presided over part of the reconstruction era. For part of this presidency, there was no one else who knew how he felt and no living person who had been in his position. What a tenuous time!*
The other presidents who, at some point, had no living predecessors were Theodore Roosevelt (26th), Herbert Hoover (31st), and Richard Nixon (37th). But since 1981, we’ve had three or more living presidents. So, most of us feel like that’s “normal”. Imagine if there was just Trump, and that’s it. That’d feel jarring.
1) Are More People Becoming President?
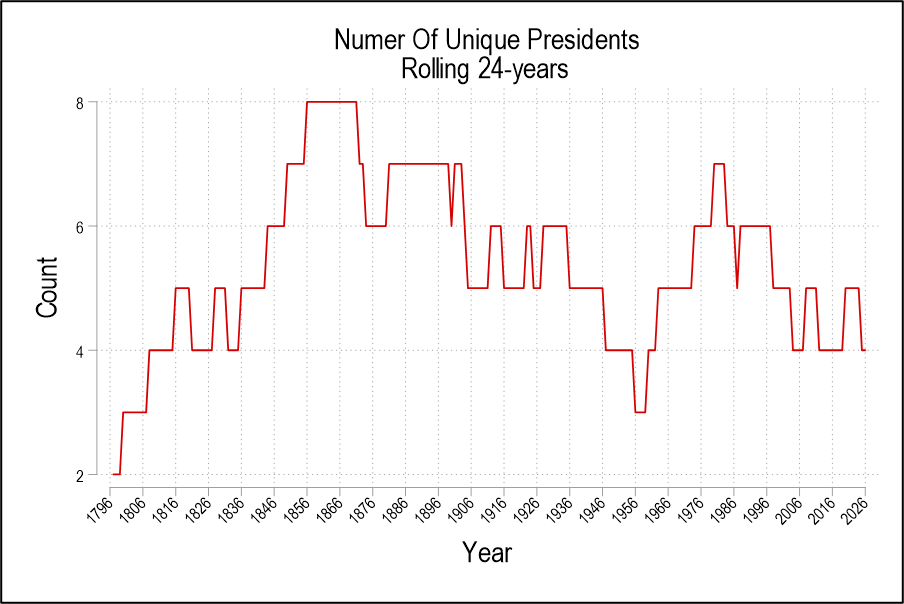
A presidential term is four years and only one president was in office for more than two terms, Franklin Roosevelt (32nd). Let’s take a 24-year trailing average. With 8-year tenures, the least number of presidents is 3. With 4-year tenures, the greatest number of presidents is 6. Assassinations and other deaths of sitting presidents can push the number higher. The graph below is the number of unique people to act as head of state over the prior 24 years (I say ‘unique’ because Cleveland (22nd & 24th) and Trump (45th & 47th) both served two non-consecutive terms).
We can conclude that the number of unique presidents is not exceptionally high at this time. The historical average is about 5.2 unique presidents. We’ve been below that since 1998 owing to a higher proportion of two-term presidents since then. Before Biden (46th), Bush (41st) was the last time that we had a one-term president. So, in terms of executive regimes, the 21st century has been unusually stable. But this stability also places downward pressure on the number of surviving ex-presidents. So, we’ve had many living ex-presidents despite our few regime changes. Reason 1) doesn’t explain why we have so many living ex-presidents now.
The Lahman Baseball Database offers player- and team-level stats all the way back to 1871 as freely downloadable files. It includes over 20,000 players and has been cited by 192 academic papers. That sounds like something that takes an enormous amount of effort to put together, but it seems to have been compiled by just one guy, journalist Sean Lahman.
This looks like yet another example of a lone individual outperforming the huge, well-funded institutions you might expect to compile such datasets- this time not the government but MLB, ESPN, et c.
Sean Lahman has graciously agreed to donate the Lahman Baseball Database, an open source collection of historical baseball statistics, to SABR.
The Lahman Baseball Database — which Lahman created in 1996 and has made freely available online every year since then — contains complete batting and pitching statistics back to 1871, plus fielding statistics, standings, team stats, managerial records, postseason data, and more. While Lahman and others had previously released smaller datasets online, his database allowed researchers to perform complex queries across the entire history of the game for the first time. The Lahman Baseball Database has served as the foundation for many popular baseball research projects and simulation games, including Out of the Park Baseball and Baseball Mogul.
SABR plans to continue to update the database and make it available for free online every year at SABR.org/lahman-database.
I can only hope more of us will compile datasets worth handing off to an institution that will keep updating them.
I have a new essay up at Human Progress today. Here’s a slice of it:
The productivity slowdown is not an immutable law of nature. It is, at least in part, the consequence of policy choices. Human ingenuity remains as powerful as ever. We have more scientists, more capital, and better tools than any previous generation. The challenge is not generating ideas; it is allowing those ideas to spread.
…
An additional one or two percentage points of annual productivity growth may sound insignificant. Yet when compounded over decades, the effects are transformative. Higher productivity means higher incomes, better health outcomes, more abundant energy, and greater opportunities for future generations. The ideas already exist. The question is whether we will allow them to flourish.