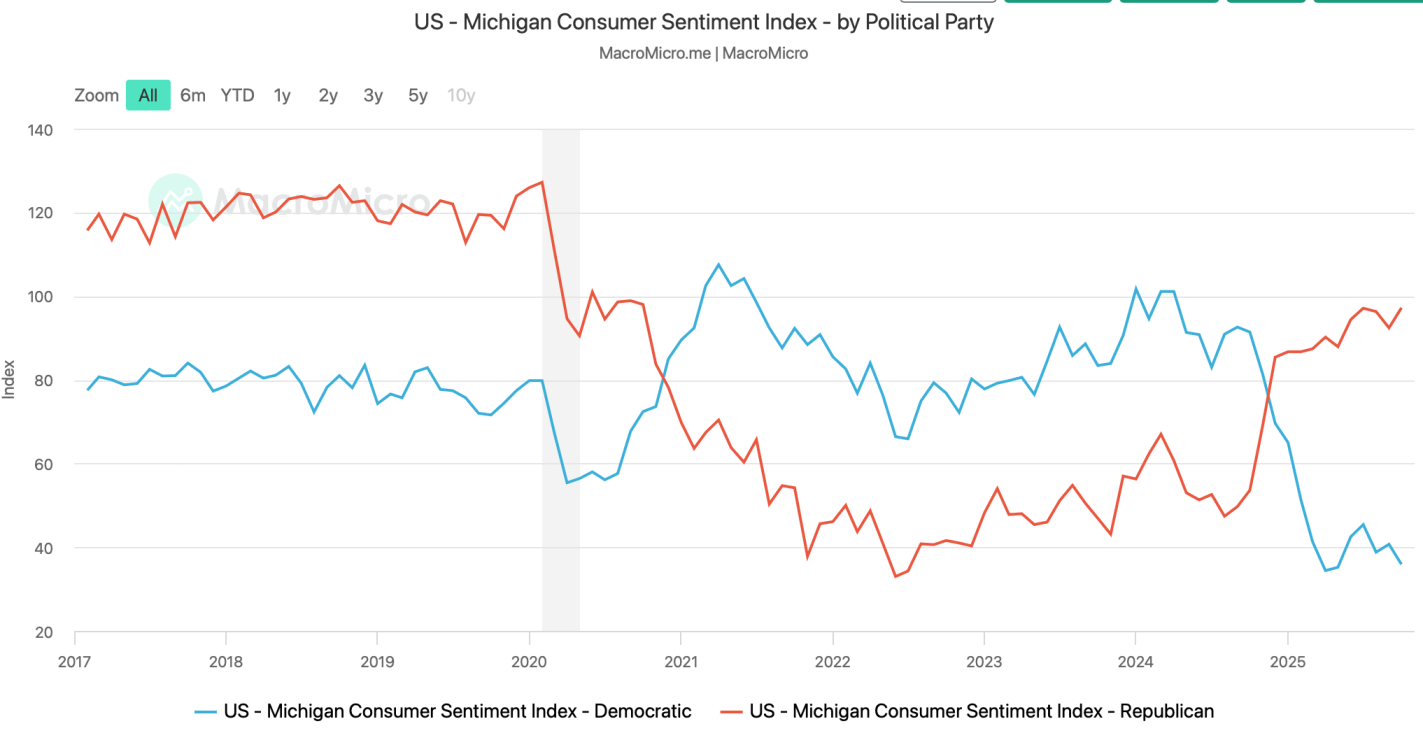
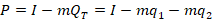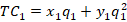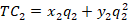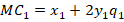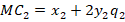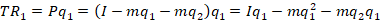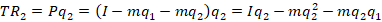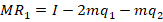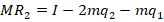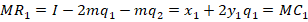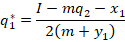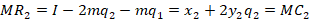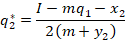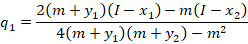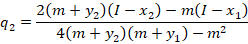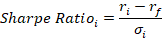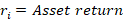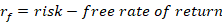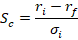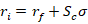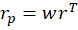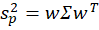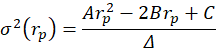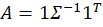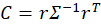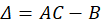Most people have an intuition that uncertainty can harm economic outcomes. Baker, Bloom, & Davis (2016) and Bloom (2009) demonstrated that industrial production and manufacturing decline in the face of policy uncertainty. The typical mechanism that people suggest is that uncertainty about the future causes people to engage in precautionary saving, resulting in fewer sales.
The theory continues that firms consequently decrease production as demand for their output declines. Firms aren’t interested in causing the quantities supplied and demanded to be equal. Rather, they don’t want to produce too many goods that don’t get sold or don’t get sold at an adequate markup. Production is costly. A related theory is that more persistent or longer-run uncertainty can also depress investment, since the riskier future increases the tail risk of losses.
Rather than make a risky investment, one could instead just hold off and wait for some of that uncertainty to get resolved. There’s tradeoffs to this, of course. As future costs and benefits become clearer, they also get priced-in to asset values. So, there is an optimization problem. The possible downside outcome is big and uncertain. If the risk of the investment gets resolved and the downside outcome is still too likely or harmful, then a project manager did the ex-post ‘right thing’ by waiting.
But, if the downside risk disappears or is found to be very small, then waiting to invest in the project incurs an economic cost. Either 1) the profitable project and its associated profits will occur later and less valuably, or 2) other firms also resolve their uncertainty and bid up the price of the project’s inputs. Invest too early, and the downside is large and uncertain. Invest too late, and you may lose the potential upside partially or entirely.
But can uncertainty systematically increase profits?
I have put a working paper on SSRN describing three ways I incorporated AI into my Business Statistics 200-level class for undergraduates at Samford University in Spring 2026. Read the paper at the link.
Abstract Economics education almost always includes a component of statistics. Most undergraduate economics curricula require an upper-division econometrics course, and many economists teach data analysis. These courses help students become conversant with major contributions in economics research, but they can be challenging to teach. On its own, the mathematics of regression, error minimization, and statistical software may not feel exciting to students, especially compared with the intuitive economic reasoning that often draws them into the discipline. At the same time, students are increasingly interested in artificial intelligence and large language models. This note describes three practical teaching exercises designed to connect ordinary least squares, Excel training, and LLMs. The goal is to use students’ curiosity about AI to motivate classic statistical reasoning and practical spreadsheet skills.
The image is from ChatGPT 5.5 Thinking mode and it took over a minute to generate. The fact that their laptop screen is pointing away from them is funny (unrealistic). The portrayal of Tom Holland and Zendaya is good, which is what the audience cares about. So, this seems like a case of AI hallucinating up the thing that people want.
Citation: Buchanan, Joy, “Connecting Classroom Econometrics and Excel Training with Large Language Models” (May 27, 2026). Available at SSRN: https://ssrn.com/abstract=6839039
Note: I have been posting my papers to SSRN for a long time as a way to distribute them faster and more widely. I have heard rumors that SSRN might stop working, for my purposes. If anyone has suggestions for what I should do about the papers I have up there, please let me know! Or, if you are readying this post-summer-2026 and want a copy, send me a message at my Samford email so I can send you a copy.
Robbins emphasizes class size and teaching load against the time of an instructor. An instructor teaching 4 sections with 100 students each is very limited in their ability to monitor and prosecute AI teaching. It’s worse if this instructor is on a temporary contract.
Limited eyes and hands and human attention really are a constraint here, at least for now. Some people see AI tools in the hands of students as the end of education itself.
I have been tweeting my replies to this:
I don’t do remote exams, but I hear about improvements to remote proctoring technology. The arms race is not over.
I don’t do remote exams, but I hear about improvements to remote proctoring technology. The arms race is not over.
Technology goes both ways. The phone students were using to cheat are now being marshalled as a “second camera” for remote test proctoring. Instructors are going to largely win this year if they take current technology seriously, for multiple choice and short answer evaluations.
The commercial Respondus program has just added Word extensions. This technology already exists and can run on the students’ laptops.
Right now, a clever student might still be able to shift their carbon-based eyes to a direction where the answer is displayed illicitly. And the instructor’s eyes can only monitor so many eyes. This is all so 2024. This conversation may be over soon. Human students can be placed under the supervision of machine eyes. Right now, we are still dealing with issues of false positives when machines flag students for cheating, but the machines are improving.
I believe that the roads will eventually be dominated by machine drivers and their unblinking eyes. Humans might drive cars for fun in the hinterlands, but it will no longer be considered a serious thing humans to do for work. Monitoring student cheating will become like truck driving. Human eyes are on the way out. We are going to become more cheat-proof than college has ever been before.
As a college professor, that will have implications for my job, although I can imagine a not-completely-negative future. Maybe I could do more fun work with students because the work of proctoring will be handled automatically. I have spent many many hours constructing tests that would be hard to cheat on and watching students take them. I take cheating seriously, and all the faculty at my business school work hard to protect the value of our degree. I predict that this will become a trivial part of teaching within 10 years.
Will students respond with various forms of hacking and deep fakes against such a system? Maybe. So far, in any arms race, Uncle Sam has been winning in the end for a century now.
If there is a will to do so, we could even bring back the research paper by having students work on a monitored computer that does not let them use AI to write. (We could almost do that already, but perhaps the true limiting factor is that, as I like to say, readers are that which is scarce.)
[Credit to my colleagues Art Carden and Anna Leigh Stone who have talked with me about test proctoring this semester.]
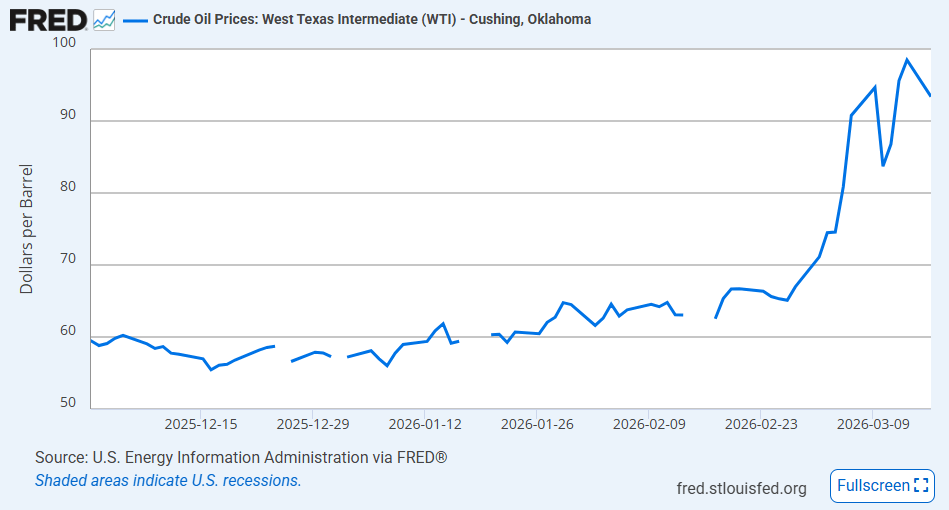
Alex Tabarrok noted in Oil versus Ice Cream that he and Tyler, as textbook authors, “chose the oil market as our central example. Oil is always in the news…”
when a student sees that the price of crude has surged past $100 a barrel because Iran closed the Strait of Hormuz—choking off 20% of the world’s oil supply—they have the framework to understand what is happening. Supply shock, inelastic demand, expectations and speculation, the macroeconomic transmission to GDP—it’s all right there in the headlines.
In a classroom, a good way to begin is to ask the students to tell you what they have noticed recently about oil or gas prices. Having the students obtain the oil price data themselves could be fun, if you are in an environment with screens/computers.
Ask students: “Is this price change primarily explained by
Increase in demand
Decrease in demand
Increase in supply
Decrease in supply
Correct answer: d. Decrease in supply
If you cover elasticity, this is especially helpful as an example. “Why would the price jump more when demand is inelastic?”
It’s not too late to work this into a lesson plan for the Spring 2026 semester, economic teachers. I might use it to illustrate supply shocks next week.
This event is a classic example of a negative supply shock: a disruption in the Strait of Hormuz would reduce the amount of oil reaching world markets, pushing energy prices sharply upward. Because oil is an important input for transportation, manufacturing, and heating, higher oil prices raise costs across much of the economy. Firms may cut production, households may spend more on gasoline and utilities and less on other goods, and overall economic activity can slow. That is why economists worry that large oil supply shocks can contribute to recessions. They do not just make one product more expensive; they can ripple outward, reducing real income, lowering consumer confidence, and weakening GDP growth while inflation rises.
Related posts. The whole crew showed up this month:
This post solves for the equilibrium quantity of production with quadratic total cost under Cournot and Stackelberg competition.
Say that there are two firms. They produce the exact same quality and type of goods and sell them at the same price. Let’s also assume that the market clears at one price. Finally, let’s assume increasing marginal costs.
Let’s say that they face the following demand curve:
The firms have a total cost of:
The marginal cost is the derivative with respect to the choice variable for each firm, or their respective quantities produced:
The total revenue is just the price times the quantity sold.
This is all standard fare for economic modeling. You’re free to make different assumptions. You can even adopt different slopes in the demand curve to reflect goods with different characteristics.
Cournot Competition
If you imagine a lengthy production process, or otherwise that they physically attend the same market, then it’s reasonable to assume that they don’t know one another’s choice of quantity produced.
We know how firms maximize profit: They produce the quantity at which the marginal revenue equals the marginal cost. But, what is marginal revenue? The derivative of total revenue with respect to the choice variable:
Now we can set the marginal revenue equal to marginal cost and solve for the optimal level of output:
Notice that the optimal level of output depends on the production decision of the other firm. These are called response functions. If we solve for the quantities at which they intersect, then we are solving for where both firms are producing the best response to one another. This is known as a Pure Strategy Nash Equilibrium (PSNE).
Luckily, in many applications, one or more of the above terms are zeros, which makes things much simpler.
The general process for solving for the Cournot equilibrium is:
Mike Mulligan and His Steam Shovel, by Virginia Lee Burton, is a classic 1939 children’s book about a man, Mike Mulligan, and his beloved steam shovel, Mary Anne, who are replaced by modern machinery. They get one last chance to demonstrate their worth by digging the cellar for a new town hall in a single day.
This book is more than just a nostalgic children’s story with a happy ending. This is a tale about economic history, comparative advantage, non-pecuniary benefits, labor and capital heterogeneity, and, of course, transaction costs.
Here’s some background. Historically, excavating or earth-moving equipment was powered by steam. Much like a steam engine locomotive (train), a steam shovel burns coal to heat water in a boiler, creating steam that can drive pistons that operate the mechanics. The result is machinery that can move a greater volume of soil at a faster speed than humans with simple hand shovels. Advancements in oil extraction and refining and internal combustion made the steam methods obsolete. Diesel or gasoline made earth movers safer, faster, and larger all because there was no need to build high pressures from boiling water. Steam pressure in the field takes a lot of time and is dangerous.
Here is how the story goes. Mike enjoys his earth-moving work with his steam-shovel and is proud to be more productive than hand-shovels. One day, diesel, electric, and gasoline-powered shovels arrive. They’re bigger and better than Mary Anne. She is now obsolete. It’s unclear whether Mike’s skills are transferable to the newer equipment, but he implicitly prefers working with Mary Anne. Together, they can’t compete in the urban areas where the value placed on quick excavation is high. So, they flee to the countryside.
The text doesn’t say why the newer shovels aren’t in the countryside. Let’s address that first. The new shovels haven’t spread to the rural areas because the opportunity cost is too high. Diesel Shovels are expensive and the owners/operators need revenue from many jobs in order to pay for their equipment in a reasonable amount of time and earn a positive return. Rural areas don’t have the same willingness to pay for as many projects, so less specialized capital is limited by the smaller extent of the market. Clearly, a higher cost of capital – the cost of the loan that pays for the diesel shovels or the alternative uses of the resources – accentuate the necessity for project volume.
Use the above game to generate interaction in a class setting. Students collectively form an LLM and have fun seeing the final sentence that gets produced. I call this game “LLM Telephone” based on the classic game of telephone. I suggest downloading the file LLM_Telephone_Game_Sheet and handing out printed copies. However, this game could be adapted to a virtual setting.
The nice thing about passing papers in the classroom is that you can have several sheets circulating in a quite room, so when the final sentence is read allowed it comes as a surprise to most people.
If you’d like to have a handout to follow the game with a more technical explanation, you can use this two-page PDF:
The game relies on a player presenting two tokens of which the next player can select their favorite. Participants should be bound by the rules of grammar and logic when making their selection and presenting two tokens to the next player.
This game works as a fun ice breaker for any type of class that touches on the topic of artificial intelligence. It is suitable for many ages and academic disciplines.
What I’m telling my Intro Macro students on the last day of class, since we weren’t able to get through every chapter in the textbook:
A few of you might end up working in economic policy, or in highly macro-sensitive businesses like finance. For you, I recommend taking followup classes like Intermediate Macroeconomics or Money and Banking so you can understand the details. For everyone else, here are the very basics:
In the long run, economic growth is what matters most. The difference between 2% and 3% real GDP growth per capita sounds small in a given year, but over your lifetime it is the difference between your country becoming 5 times better off vs 10 times better off.
How to increase long-run economic growth? This is complicated and mostly not driven by traditional macroeconomic policy, but rather by having good culture, institutions, microeconomic policy, and luck.
In the shorter run, you want to avoid recessions and bursts of inflation.
High inflation means too many dollars chasing too few goods. To fix it, the federal government and the central bank need to stop printing so much money (the details can get very complicated here, but if we’re talking moderately high inflation like 5% the solution is probably the central bank raising interest rates, and if we’re talking very high inflation like 50% the solution is probably a big cut to government spending).
If there is a recession (which will look to you like a big sudden increase in layoffs and bankruptcies), the solution is probably to reverse everything in the previous point. The government should make money ‘easier’ via the central bank lowering interest rates while the federal government spends more and taxes less.
If you don’t take more economics classes, you will likely hear about macro issues mainly through the news media and social media. You should be aware of their two main biases: negativity bias and political bias.
Negativity Bias: If It Bleeds, It Leads on the news. Partly this is because bad news tends to happen suddenly while good news happens slowly, so it doesn’t seem like news; partly it just seems to be what people want from the news and from social media.
Political Bias: People tend to seek out news and social media sources that match their current preferences. These sources can be misleading in consistent ways for ideological reasons, or in varying ways based on whether the political party they like is currently in power.
There are different ways to measure each key macroeconomic variable. Think through them now and make a principled decision about which ones you think are the best measures, and track those. Otherwise, your media ecosystem will cherry-pick for you whichever measures currently make the economy look either the best or the worst, depending on what their biases or incentives dictate.
There are good ways to keep learning about economics outside of formal courses and textbooks, I list a few here.
We all like high returns on our investments. We also like low volatility of those returns. Personally, I’d prefer to have a nice, steady 100% annual return year after year. But that is not the world we live in. Instead, there are a variety of returns with a diversity of volatilities. A general operating belief is that assets with higher returns tend to be associated with greater return volatility. The phrase ‘scared money don’t make money’ implies that higher returns are risky. The Sharpe ratio is a tool that helps us make sense of the risk-reward trade-off.
Let’s start with the definition.
By construction, the risk-free return is guaranteed over some time period and can be enjoyed without risk. Practically speaking, this is like holding a US treasury until maturity. We assume that the US government won’t default on its debt. Since there is no risk, the volatility of returns over the time period is zero.
Since an asset’s return doesn’t mean much in a vacuum, we subtract the risk-free return. The resulting ‘excess return’ or ‘risk premium’ tells us the return that’s associated with the risk of the asset. Clearly, it’s possible for this difference to be negative. That would be bad since assets bear a positive amount of risk and a negative excess return implies that there is no compensation for bearing that risk.
The standard deviation of an asset’s returns are a measure of risk. An asset might have a higher or lower value at sale or maturity. Since the future returns are unknown and can end up having any one of many values, this encapsulates the idea of risk. Risk can result in either higher or lower returns than average!
Putting all the pieces together, the excess return per risk is a measure of how much an asset compensates an investor for the riskiness of the returns. That’s the informational content of the Sharpe ratio, which we can calculate for each asset using historical information and forecasts. Once we’ve boiled down the risk and reward down to a single number, we can start to make comparisons across assets with a more critical eye.
Sometimes friends or students will discuss their great investment returns. They achieve the higher returns by adopting some amount of risk. That’s to be expected. But, invariably, they’ve adopted more risk than return! That means that their success is somewhat of a happy accident. The returns could easily have been much different, given the volatility that they bore.
Let’s get graphical.
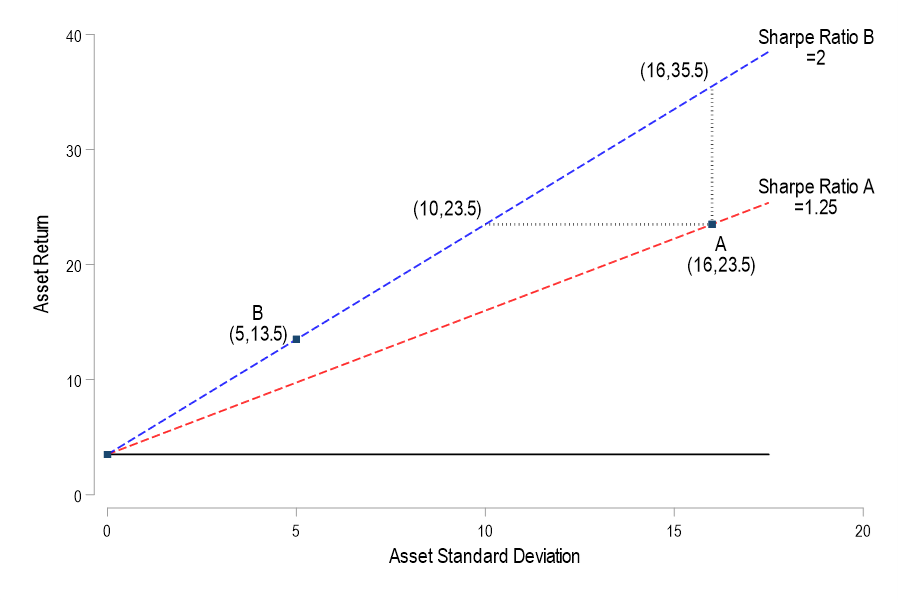
Consider a graph in (standard deviation, return) space. In this space we can plot the ordered pair for some portfolios. The risk-free return occurs on the vertical intercept where the return is positive and the standard deviation is zero. Say that a student was thrilled with asset A’s 23.5% return and that it’s standard deviation of returns was 16%. Meanwhile, another student was happy with asset B’s 13.5% return and 5% standard deviation. With a risk-free rate of 3.5%, the Sharpe ratios are 1.25 & 2 respectively. We can plot the set of standard deviation and return pairs that would share the same constant Sharpe ratio (dotted lines). Solving for the asset return:
The above is simply a linear function relating the return and standard deviation. In particular, it says that for any constant Sharpe ratio, there is a linear relationship between possible asset returns and standard deviations. The below graph plots the two functions that are associated with the two asset Sharpe ratios. The line between the risk-free coordinate and the asset coordinate identifies all of the return-standard deviation combinations that share the same Sharpe ratio. This line is known as the iso-Sharpe Line.
With this tool in hand, we can better interpret the two student asset performances. There are a couple of ways to think about it. If asset A’s 23.5% return had been achieved with an asset that shared the Sharpe ratio of asset B, then it would have had risk that was associated with a standard deviation of only 10%. Similarly, if asset A’s volatility remained constant but enjoyed the returns of asset B’s Sharpe ratio, then its return would have been 35.5% rather than 23.5%. In short, a higher Sharpe ratio – and a steeper iso-Sharpe line – imply a bigger benefit for each unity of risk. The only problem is that a such an nice asset may not exist.
Previously, I plotted the possible portfolio variances and returns that can result from different asset weights. I also plotted the efficient frontier, which is the set of possible portfolios that minimize the variance for each portfolio return.* In this post, I elaborate more on the efficient frontier (EF).
To begin, recall from the previous post the possible portfolio returns and variances.
From the above the definitions we can see that the portfolio return depends on the asset weights linearly and that the variance depends on the asset weights quadratically because the two w terms are multiplied. Since the portfolio return can be expressed as a function of the weights, this implies that the variance is also a quadratic function of returns. Therefore, every possible portfolio return-variance pair lies on a parabola. So, it follows that every pair along the efficient frontier also lies on a parabola. Not every pair lies on the same parabola, however – the efficient frontier can be composed on multiple parabolas!
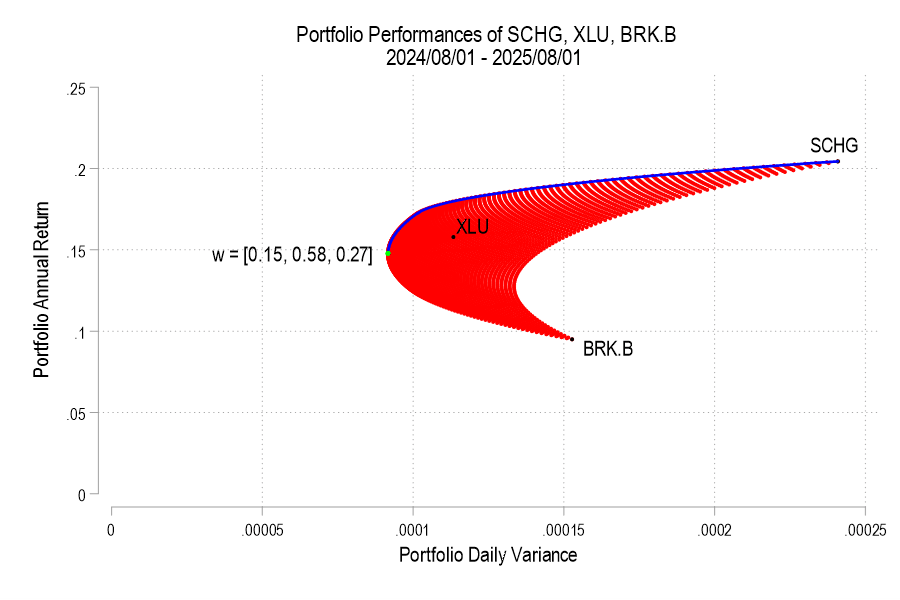
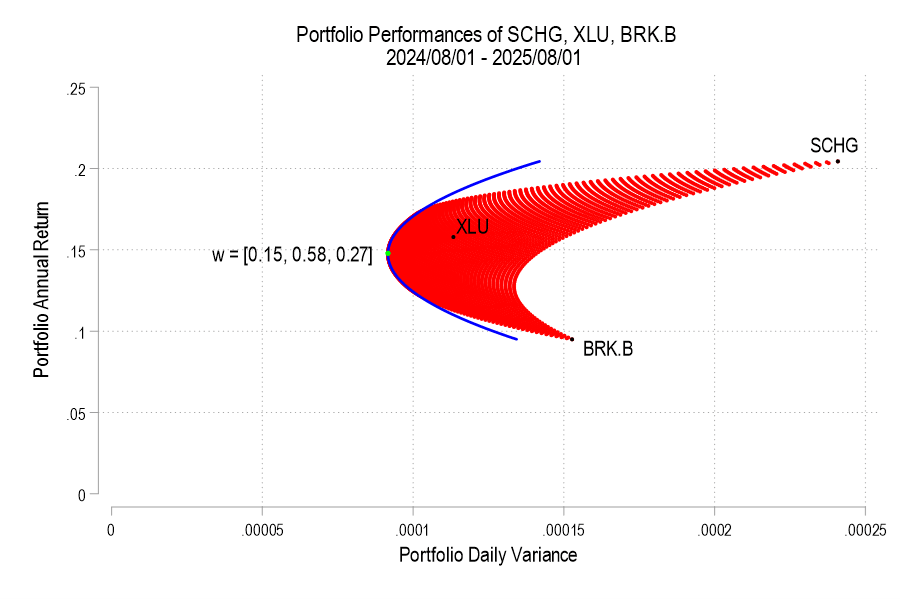
I’ll use the same 3 possible assets from the previous post, below is the image denoting the possible pairs, the EF set, and the variance-minimizing point.
One way to find the EF is to calculate every possible portfolio variance-return pair and then note the greatest return at each variance. That’s a discrete iterative process and it definitely works. One drawback is that as the number of assets can increase the number of possible weight combinations to an intractable number that makes iterative calculations too time consuming. So, we can instead just calculate the frontier parabolas directly. Below is the equation for a frontier parabola and the corresponding graph.
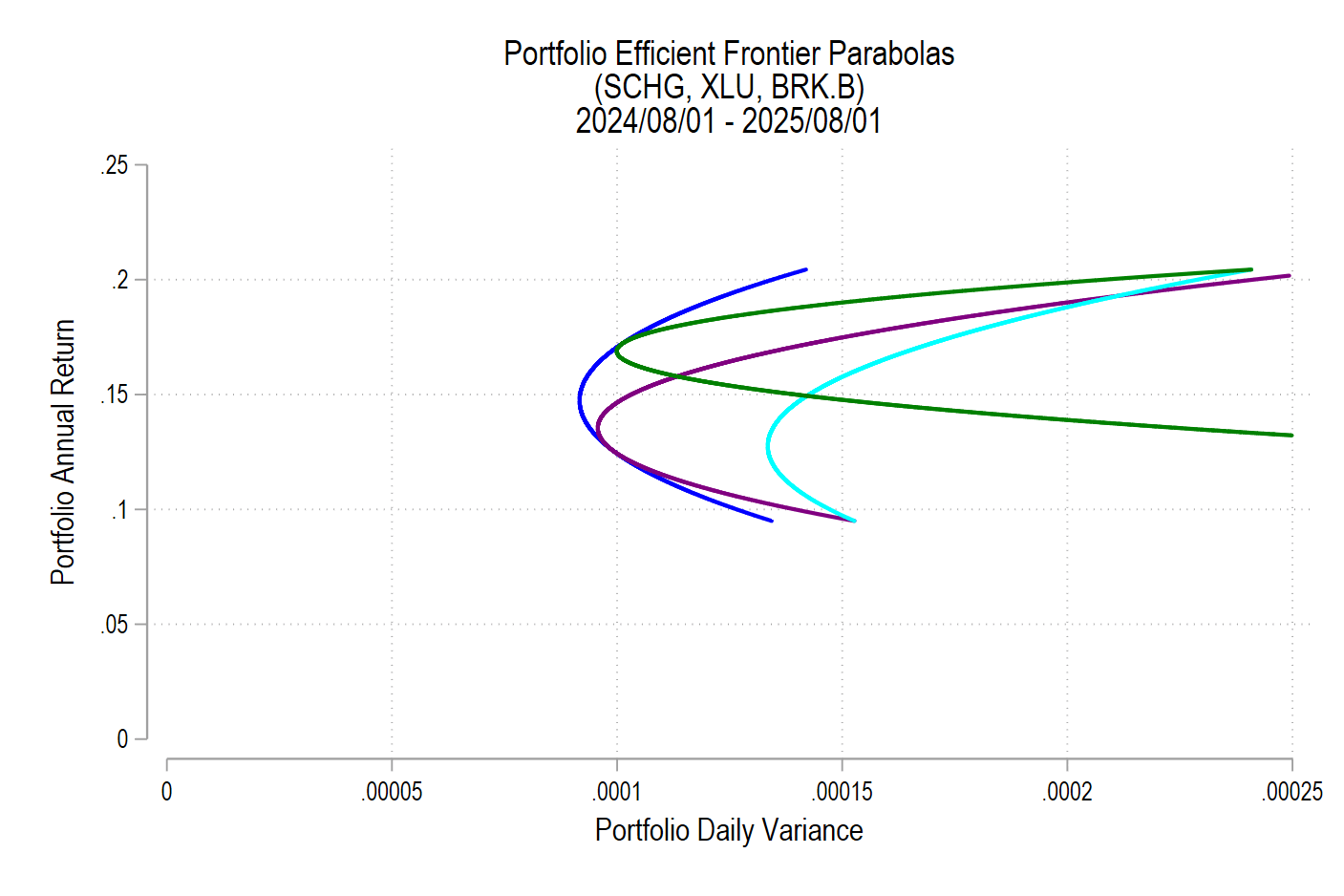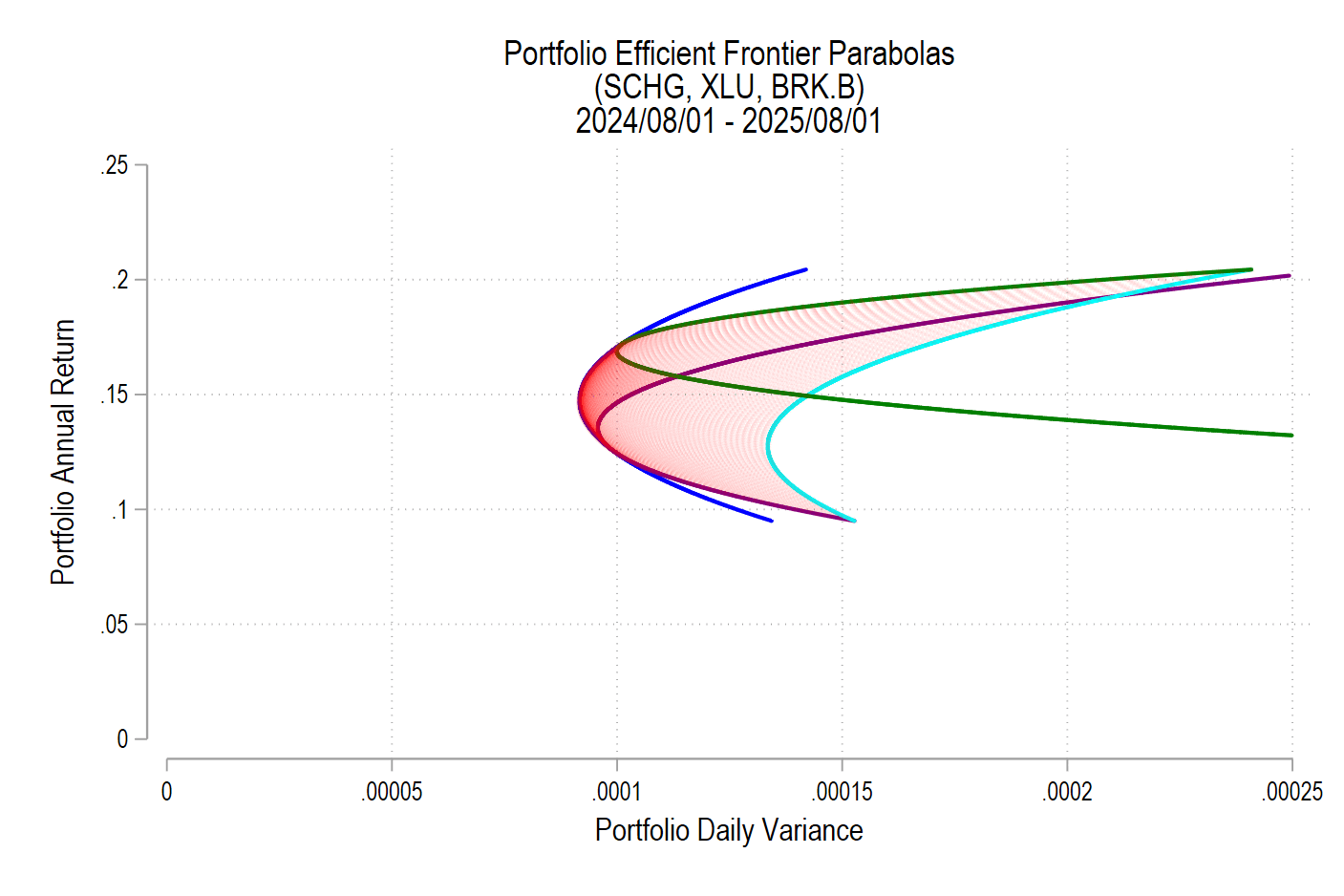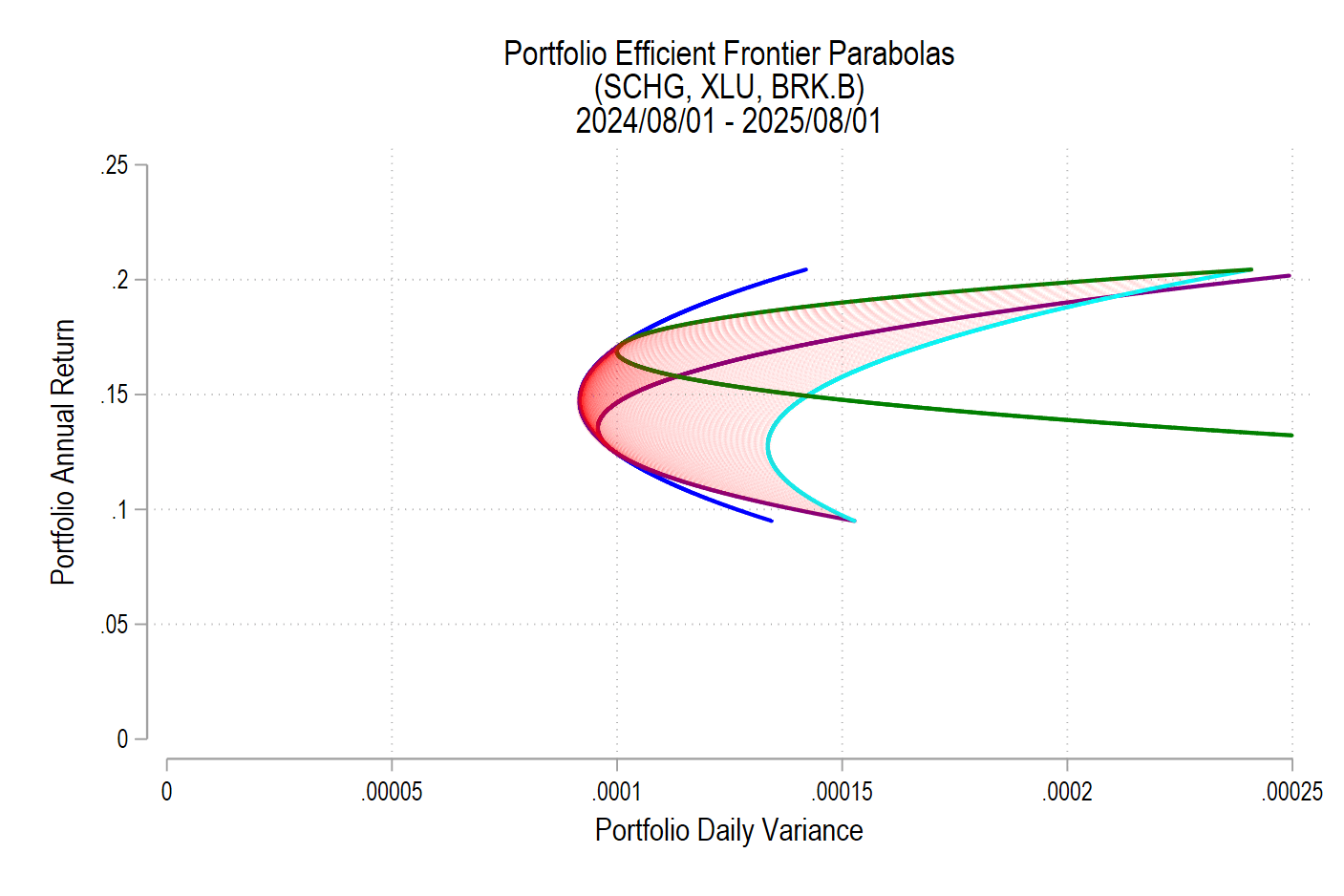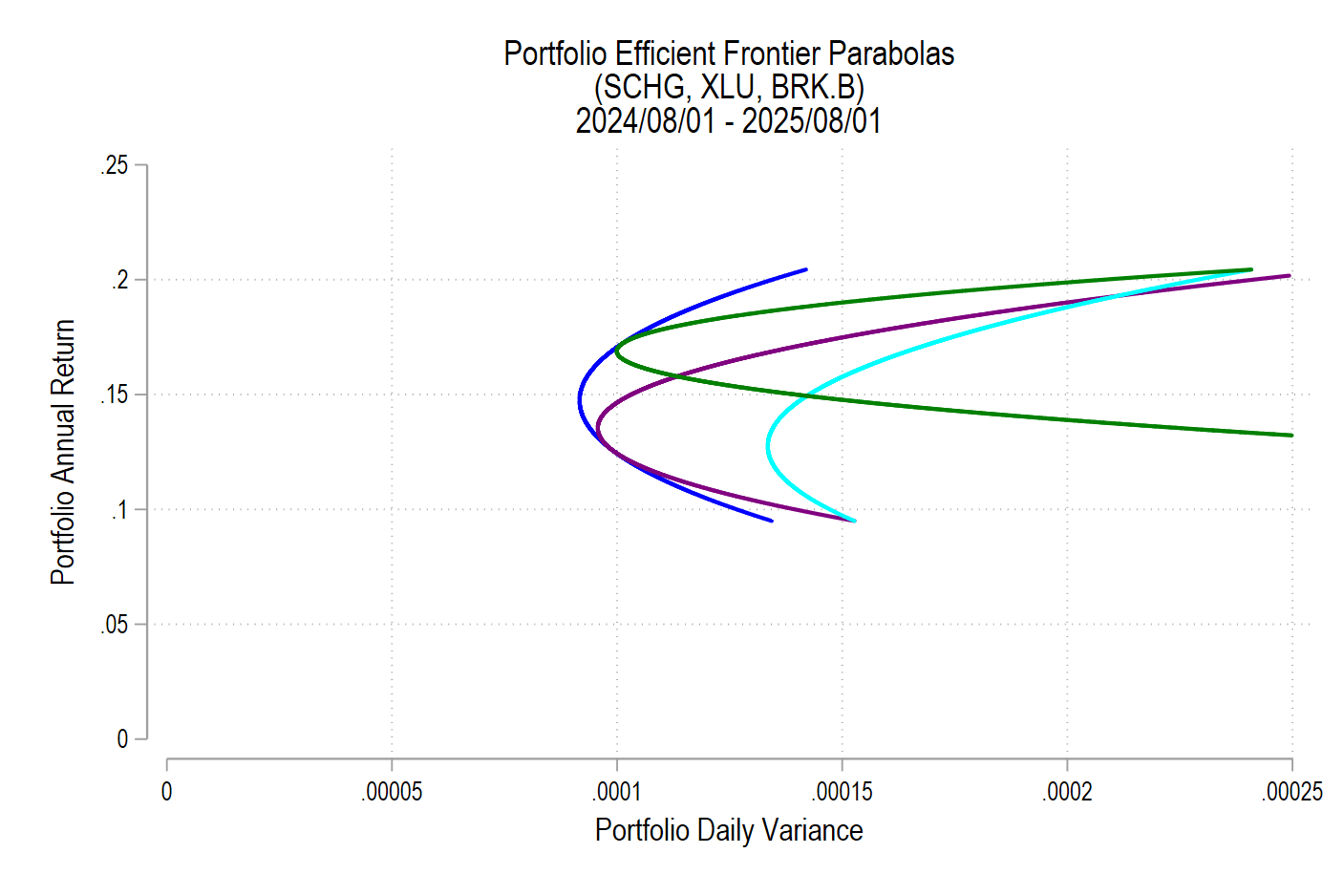
Notice that the above efficient frontier doesn’t appear quite right. First, most obviously, the portion below the variance-minimizing return is inapplicable – I’ve left it to better illustrate the parabola. Near the variance-minimizing point, the frontier fits very nicely. But once the return increases beyond a certain level, the frontier departs from the set of possible portfolio pairs. What gives? The answer is that the parabola is unconstrained by the weights summing to zero. After all, a parabola exists at the entire domain, not just the ones that are feasible for a portfolio. The implication is that the blue curve that extends beyond the possible set includes negative weights for one or more of the assets. What to do?
As we deduced earlier, each pair corresponds to a parabola. So, we just need to find the other parabolas on the frontier. The parabola that we found above includes the covariance matrix of all three assets, even when their weights are negative. The remaining possible parabolas include the covariance matrices of each pair of assets, exhausting the non-singular asset portfolios. The result is a total of four parabolas, pictured below.