I just ran across a short article [1] summarizing a talk with some techniques on learning more efficiently, which seemed worth sharing here. It may be something for professors to pass along to their students.
The speaker was Andrew Watson, who is an expert on learning and the brain, and currently a teacher at the Loomis Chaffee School in Connecticut. He noted three key ways that students (and adults) can work with the ways the brain learns information. The last two points are good but well known, while the first point was not something I have seen emphasized much:
( 1 ) Retrieve information while studying:
To study better, students should focus on the idea of retrieval rather than review. Trying to recall information before looking back at it produces more remembering than simply reading it through again. He suggested creating flash cards and using visual hints and clues as effect retrieval techniques.
( 2 ) Change the environment to avoid distractions:
The environment in which someone studies also affects how well they retain information because the human brain works best when it focuses on one activity at a time.
(My comment: That is absolutely true for me, I can’t stand any distraction when I am studying or writing, but I know people who claim they study more effectively with a TV show or music going in the background…I wonder what academic studies show about that.)
( 3 ) Bolster your health:
The brain, like the rest of the body, benefits from a healthy lifestyle, including eating well and exercising regularly. Ample sleep helps the brain to process and solidify information absorbed during the day. If homework is everything that helps a person learn and if sleep help you learn, then sleep is a part of homework.
[1] “Brain Hacks for Brainiacs” in the Loomis Chaffee Magazine, Spring 2022, page 13.
So, to summarize, there is a medical service for which there is significant demand. That demand, at the micro level of an individual consumer, comes with time pressure in a heightened emotional context. The supply of the service will vary geographically. Given the clustering of states that are prohibiting abortion in the south and midwest, there will be considerable heterogeneity in legal abortion access based almost entirely on physical distance and access to transportation.
Prohibition of a good with strong demand, heterogeneous legal supply, and heavy punishments for those seeking to enable arbitrage across state lines. This is not a new story. First alcohol, then narcotics, now abortion. This might feel different because abortion is a service good, but it’s not. Why?
As it stands, a state cannot ban a drug with FDA approval, but access is nonetheless thin. There will also be, with similarly little doubt, efforts to quickly ban mifepristone and misoprostol, with accompanying heavy punishments. Eleven weeks is a long enough window that it will cover the majority of abortions. It’s small and portable, which means it will be easily transported and resold. It will also remain perfectly legal in a number of states bordering those prohibiting abortion. There will be, with nearly zero doubt, a booming black market in mifepristone and misoprostol within a matter of months.
But this isn’t a medical procedure provided in a fixed building with identifiable practitioners. These will be pills that will be exchanged in school bathrooms and college dorms, purchased by professional women who drove 300 miles in a Lexus and came back with enough to give to their professional friends who want to be proactive and prepared for daughters who may be sexually active. Further, these aren’t addictive products: there won’t be weekly customers whose symptoms will create patterns of consumption and the kinds of collateral damage that attract attention. Passive enforcement of these laws will be highly ineffective.
In some places, enforcement on pill restrictions will simply be weak, meaning anyone whose pregnancy can be terminated in the short run will retain some meaningful access. The price will be elevated like any good where suppliers incur legal risk, which means access to abortion will correlate heavily with income, resources, and social privilege. This will also shift the effective burden of abortion restrictions towards the later term “abortions” that only account for 1.3% of terminated pregnancies, but are more heavily associated with medical emergencies, incomplete miscarriages, and the kinds of pregnancy events associated with trauma and shame (e.g. rape or incest) where a women is not necessarily in a position to take decisive early action. Given that the majority of Americans averse to abortion are principally concerned with late term abortions, but also believe abortion should always be an option when the health of the mother is in jeopardy, it is expecially vexxing that laws that reduce access to early term abortions will increase the previously miniscule demand for late term abortions.
I expect some states will attempt to enforce prohibitions or limitations on mifepristone and misoprostol with a war-on-drugs like zeal. How do you heavily enforce a ban on a small pill that is easily hidden, not regularly used, legally manufactured in other states, and has a viable market with high income individuals? Experience tells us the answer is to dedicate lots of resources while carrying little regard for individual rights or public safety.
Marijuana legalization has spread rapidly across the country. District attorneys are increasingly uninterested in prosecuting minor possession charges of nearly any drug. In 1993 state and local governments spent $15.9 billion on the criminal justice of drug enforcement, $26 billion by 2003. Now it’s probably closer to $40 billion (I couldn’t easily find a good current estimate). That’s a lot of money. That’s a lot of jobs. That’s a lot of government jobs, with government job security, many of whom might be wondering what their job is actually going to be in five years. They needn’t worry. When one prohibition closes a door, a new one opens a window.
Local governments have been seizing property, charging fines and fees, and generally subsidizing their local tax bases on the back of the drug war for decades now. Cracking down on a new banned substance might not work for a variety of reasons already listed, but that doesn’t mean they won’t try, particularly if trying means getting a lot of political attention while hosting photo ops with seized contraband next to local police and publicly shaming perpetrators as unforgivable monsters.
Prohibition of alcohol failed in large part because it made nearly everyone a criminal. Alcohol appealed across every strata of American life. Most Americans had a hidden liquor cabinet, a favored speakeasy, or even a backyard still. That breadth and depth of demand brought tremendous profits to those who could supply it outside of the law and, eventually, tremendous violence from those eager to capture those profits.
Demand for abortion access, whether for discretionary reasons or medical necessity, appears randomly in lives, but those rolls of the dice are inclusive of nearly every woman and every family. With that breadth and depth of demand will come a black market. Possibly even a highly profitable market. Materially profitable for suppliers. Politically profitable for those legislating to suppress it. Budgetarily profitable for those working every day to destroy it. These prohibition rents will appear, they will be fought for, and they will sustain themselves through a process that will destroy lives. Mostly women.
The third act of American Prohibition is here and it will hurt us all. Mostly women.
If you are teaching a quantitative college course, then you have probably thought about where to get data that students can practice with.
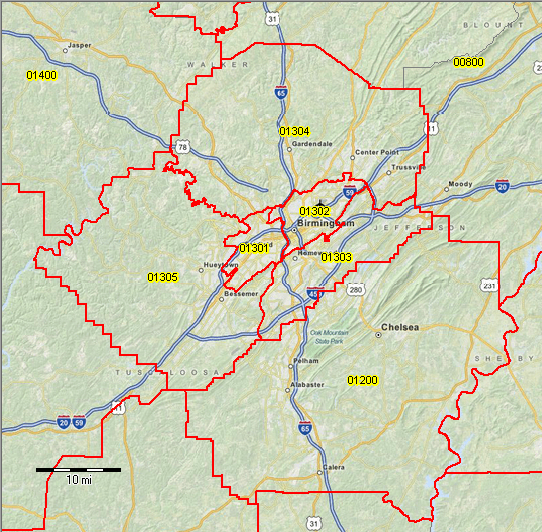
Public Use Microdata Areas (PUMAs) are non-overlapping, statistical geographic areas that partition each state or equivalent entity into geographic areas containing no fewer than 100,000 people each. The image here shows PUMAs around Birmingham, AL. I created a dataset for my students that includes demographic data from the American Community Survey (ACS) for the region around our university.
For just about any topic you would teach in stats, I can create a mini assignment using data on the people around us. Any American metro area has clusters of high-income households and clusters of low-income households. One example of a an exercise is to create summary statistics on income by PUMA. Students will be surprised to learn the facts about their own city.
Zachary has blogged about how great IPUMS is. The way I obtained the data was to make a free account with IPUMS. If you asked for data on every American, you’ll end up with an unwieldy big file. The trick is to filter out all but a handful of PUMAs. I also recommend restricting it to just one year unless you are teaching time series techniques.
I originally got the idea from Matt Holian. Matt wrote fantastic book called Data and the American Dream. The book has data and R codes that allow you to reproduce the findings from several interesting econ papers that all use ACS data. I’m not teaching material that overlaps perfectly with Matt’s book, so I couldn’t assign it to my students, but I did borrow some elements of his idea and even (with his permission) some of his code.
Last year, our economics department launched a data analytics minor program. The first class is a simple 2 credit course called Foundations of Data Analytics. Originally, the idea was that liberal arts majors would take it and that this class would be a soft, non-technical intro of terminology and history.
However, it turned out that liberal arts majors didn’t take the class and that the most popular feedback was that the class lacked technical challenge. I’m prepping to teach the class and it will have two components. A Python training component where students simply learn Python. We won’t do super complicated things, but they will use Python extensively in future classes. The 2nd component is still in the vein of the old version of the course.
I’ll have the students read and discuss “Big DataDemystified” by David Stephenson. He spends 12 brief chapters introducing the reader to the importance of modern big data management, analytics, and how it fits into an organization’s key performance indicators. It reads like it’s for business majors, but any type of medium-to-large organization would find it useful.
Davidson starts with some flashy stories that illustrate the potential of data-driven business strategies. For example, Target corporation used predictive analytics to advertise baby and pregnancy products to mothers who didn’t even know that they were pregnant yet. He wets the appetite of the reader by noting that the supercomputers that could play Chess or Go relied on fundamentally different technologies.
The first several chapters of the book excite the reader with thoughts of unexploited potentialities. This is what I want to impress upon the students. I want them to know the difference between artificial intelligence (AI) and machine learning (ML). I want them to recognize which tool is better for the challenges that they might face and to see clear applications (and limitations).
AI uses brute force, iterating through possible next steps. There are multiple online tic-tac-toe AI that keep track records. If a student can play the optimal set of strategies 8 games in a row, then they can get the general idea behind testing a large variety of statistical models and explanatory variables, then choosing the best.
But ML is responsive to new data, according to what worked best on previous training data. There are multiple YouTubers out there who have used ML to beat Super Mario Brothers. Programmers identify an objective function and the ML program is off to the races. It tries a few things on a level, and then uses the training rounds to perform quite well on new levels that it has never encountered before.
There are a couple of chapters in the middle of the book that didn’t appeal to me. They discuss the question of how big data should inform a firm’s strategy and how data projects should be implemented. These chapters read like they are written for MBAs or for management. They were boring for me. But that’s ok, given that Stephenson is trying to appeal to a broad audience.
The final chapters are great. They describe the limitations of big data endeavors. Big data is not a panacea and projects can fail for a variety of what are very human reasons.
Stephenson emphasizes the importance of transaction costs (though he doesn’t say it that way). Medium sized companies should outsource to experts who can achieve (or fail) quickly such that big capital investments or labor costs can be avoided. Or, if internals will be hired instead, he discusses the trade-offs between using open source software, getting locked in, and reinventing the wheel. These are a great few chapters that remind the reader that data scientists and analysts are not magicians. They are people who specialize and can waste their time just as well as anyone else.
Overall, I strongly recommend this book. I kinda sorta knew what machine learning and artificial intelligence were prior to reading, but this book provides a very accessible introduction to big data environments, their possible uses, and organizational features that matter for success. Mid and upper level managers should read this book so that they can interact with these ideas prudentially. Those with a passing interest in programming should read it for greater clarity and to get a better handle on the various sub-fields. Hopefully, my students will read it and feel inspired to be on one side or the other of the manager- data analyst divide with greater confidence, understanding, and a little less hubris.