Last July I wrote here about “Humanity’s Last Exam”:
When every frontier AI model can pass your tests, how do you figure out which model is best? You write a harder test.
That was the idea behind Humanity’s Last Exam, an effort by Scale AI and the Center for AI Safety to develop a large database of PhD-level questions that the best AI models still get wrong.
The group initially released an arXiV working paper explaining how we created the dataset. I was surprised to see a version of that paper published in Nature this year, with the title changed to the more generic “A benchmark of expert-level academic questions to assess AI capabilities.”
One the one hand, it makes sense that the core author groups at the Center for AI Safety and Scale AI didn’t keep every coauthor in the loop, given that there were hundreds of us. On the other hand, I’m part of a different academic mega-project that currently is keeping hundreds of coauthors in the loop as it works its way through Nature. On the third, invisible hand, I’m never going to complain if any of my coauthors gets something of ours published in Nature when I’d assumed it would remain a permanent working paper.
AI is now getting close to passing the test:
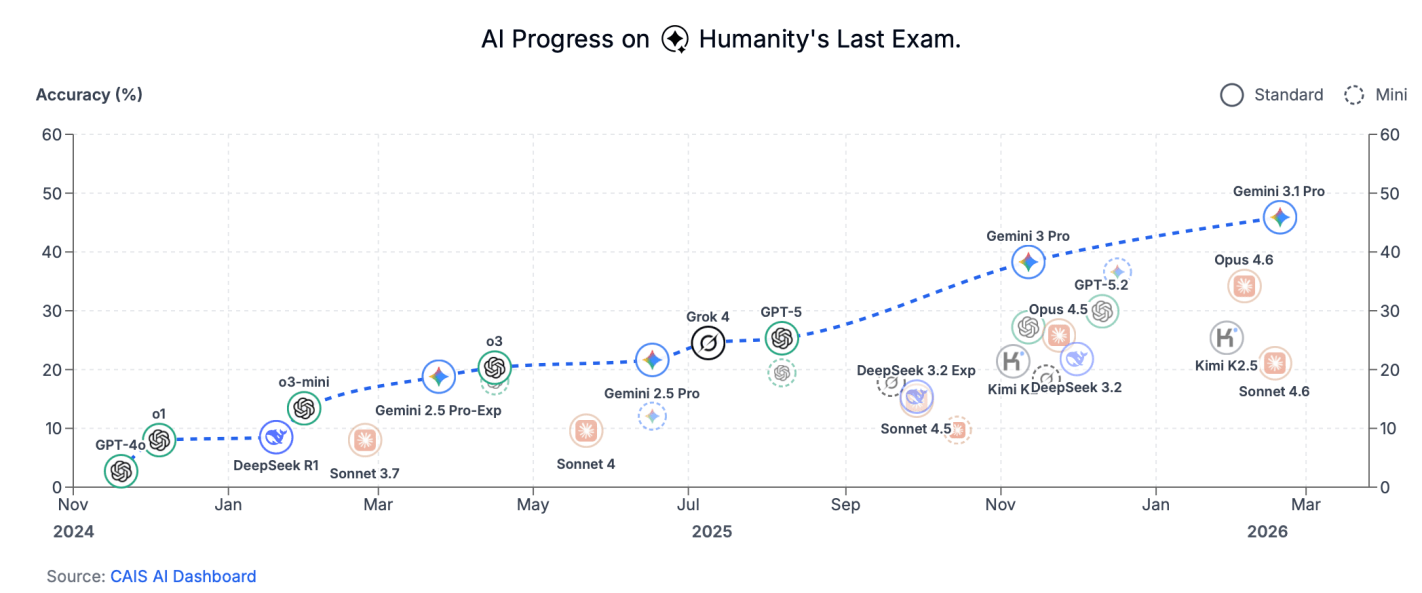
What do we do when it can answer all the questions we already know the answer to? We start asking it questions we don’t know the answer to. How do you cure cancer? What is the answer to life, the universe, and everything? When will Jesus return, and how long until a million people are convinced he’s returned as an AI? Where is Ayatollah Khamenei right now?
