I don’t think it’s a coincidence that movements like expressionism, impressionism, and abstract art took off after the invention of the camera. Photorealistic paintings are impressive, but once they are duplicating what a camera does, they’re less interesting.
We’re due for similar movements in other fields to emerge as reactions to AI. Like writing in a way totally different from how an AI would write- ideally better than an AI would write, but even writing worse than an AI can be interesting if it is at least different.
It’s still early days for both AI and our reactions to it. But since the release of ChatGPT in 2022, what is the good new essay or book that you’re most confident was not written by AI, one that was written in an almost deliberately extra-human manner?
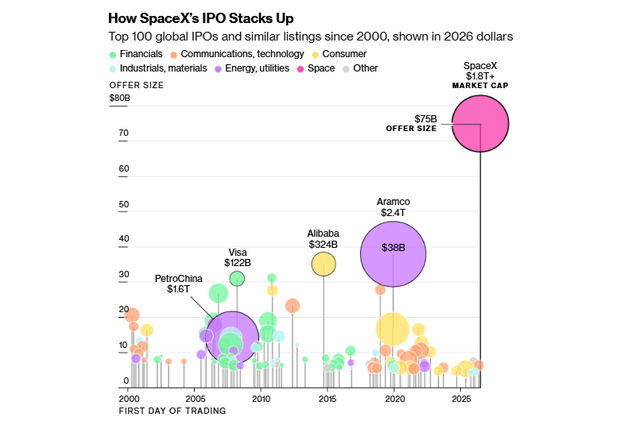
Here is a graphic that compares the size of the initial public offering (vertical axis) and the total company market cap (size of circle) of SpaceX to everything that has come before:
Elon Musk’s space launch/AI conglomerate spin-off SpaceX went public on Friday. Retail investors were all over it like a pack of starving dogs, driving up prices of SPCX from its opening $162 to $192 as of the close Monday. This has been grand theater, with Musk serving up signature visions of gargantuan total addressable markets, while investors are in fact getting crumbs of a money-loser. In the restaurant biz, this is known as selling the sizzle instead of the steak.
Let us pause for a reverent moment to savor the grand vision used to sell SpaceX: making humanity multiplanetary by dramatically lowering the cost of access to space. It extends beyond launch services into global communications (via Starlink), space infrastructure, in-space manufacturing, resource extraction, transportation, and ultimately a potential Mars economy—expanding from billions to trillions of dollars in theoretically addressable markets. Ooh, ahh, who would not want a piece of that?
Well, there are some problems here. It is hard not to splutter when trying to explain it, it is so bad for investors. I will just call out three issues I see:
( 1 ) Governance: You Own It But Can’t Influence It The IPO float represents roughly 4-5% of total shares, so we the people only get a sliver of the company. But it gets worse. Public shareholders receive Class A shares with one vote each, while Musk holds Class B shares carrying ten votes each, giving him approximately 85% voting control. More unusually, the company bylaws explicitly prohibit shareholder proposals — meaning investors cannot even put advisory resolutions to a vote. This is governance subordination beyond what even Zuckerberg imposed on his investors.
( 2 ) Valuation: Priced for Perfection Without Profits There is no price/earnings ratio because there are no earnings. At $2 trillion, SpaceX trades at approximately 20 times REVENUE. That price/sales is not unheard of for a small, fast-growing software company with almost no capital requirements (think: early-stage Amazon, Google, Palantir, etc.). But it makes no sense to apply it to a capital-intensive hardware and infrastructure business with negative GAAP earnings. Starlink is growing rapidly but requires continuous heavy capital expenditure to maintain and expand its satellite constellation. And SpaceX faces meaningful competition for orbital launches from Blue Origin, ULA (for military missions), maybe Rocket Labs, and the Chinese (for non-West payloads). And, if you dig into it, over 90% of their proposed addressable market is not space at all, but enterprise AI (!!). SpaceX pitches a total addressable market of $28.5 trillion, with AI opportunities alone accounting for $26.5 trillion. This is essentially the entire global GDP of the planet for a single year, and I guess they assume their pitiful Grok will claw back lots of market share from Claude, ChatGPT, and Gemini. As we said, priced for perfection.
( 3 ) Unbuilt Revenue Streams SpaceX has announced contracts to provide AI compute services to other companies — potentially a significant revenue source — but the data centers required don’t yet exist. Investors are therefore paying partially for infrastructure that is neither built nor generating revenue, on a timeline that remains speculative.
OK, but we have seen shares of Musk’s other baby, Tesla (TSLA), remain at uniquely high price/sales and price/earnings, seemingly indefinitely. So, investing in SpaceX is much like investing in that shiny yellow metal called gold: there will never be conventional earnings payback, but there might well be some greater fool out there who will pay more for my shares than I did. This really comes down to a psychological head game, not fundamentals. Gold has in fact done very well over the years, and the pros learned the hard way not to short TSLA, not matter how unsupportable its price is.
Final comments on index fund buying to drive up the share price – one of the bull drivers for SpaceX has been the prospect that the huge company market cap (around $2 Trillion) would force index funds like NASDAQ and S&P500 to buy boatloads of SPCX stock, driving up the price. But it turns out this will not be such a big factor. These indices only take into account the publicly traded shares, not locked-up, non-traded founder shares. So, we are looking at around $100 billion in traded SPCX shares, not the full $2 billion, which is mainly shares controlled by Musk and venture capital. $100 billion is only about 0.15% of the total S&P500 market cap of about $70 trillion. This means fund purchases of SPCX should not by itself drive down prices of other companies.
It is true that inclusion in Nasdaq-100 and Russell indexes will force automatic buying of around $25 billion in SPCX shares from funds tracking those indices. That seems like a significant driver, but (a) everyone knows this, so it is already factored into today’s prices, and (b) index fund purchases will be offset by billions in sales from VC’s as they sell shares when their lock-up periods expire in a few months.
Side comment: Historically, the major indices have had a little gravitas about what companies to include. The Nasdaq-100 typically requires at least a 3 month “seasoning” period for an IPO to trade, and then waiting till the next regularly-scheduled reconstitution. Thus, it might take around six months for an IPO to make it into the Nasdaq-100 index. For SpaceX (and presumably for Anthropic and OpenAI IPOs), NASDAQ changed the rules to allow REALLY big IPOs to be included within 15 days. (This means that some other company will get booted from the Nasdaq-100). Russell caved even further than NASDAQ, with almost immediate inclusion in the Russell 3000.
Staid Standard and Poor’s alone has maintained its dignity here, refusing to compromise on its principles. For inclusion in the S&P 500, a company must be publicly listed for at least one full year, must show positive GAAP earnings in the most recent quarter and positive cumulative earnings across the trailing four quarters (this is going to be tough for a cash-burner like SpaceX), and at least 10% (not 5%) of its shares must be publicly traded. So, no S&P listing for SpaceX in the near future.
The SpaceX IPO is set for June 12th, with an anticipated market cap after day one between $1.5 and $2.5 trillion. Most of that valuation is based on the prospect of dominating the market for satellites, putting data centers in space, and the endless demand for computing power from AI. It is essentially an AI-related market power play.
I have no speculative insight into the value of SpaceX stock as an investment, but I am an inveterate, unrepentant consumer of irony. An IPO is a speculative investment, but it’s also the act of becoming a publicly held company. A large part of being a public company is getting the accounting right. Modern accounting has all kinds of informational value, but from the point of view of large companies it’s mostly about minimimizing taxes while maximizing perceived value. Both of those ambitions include strong incentives for malfeasance, which is why we have audits, financial regulation, and the IRS. The IRS and financial regulation have been defanged, however, mostly due to a lack of personnel from aggressive destaffing, at least some of which you can lay at the feet of DOGE. You can’t audit a massive company effectively without accountants.
Or can you?
I can’t think of a technical task that is more perfectly suited to AI than auditing a public company’s accounts and SEC filings. You feed AI a billion previous filings, all of the associated laws and regulations, and then flag all the records previously found in violation. Then you feed it new ones and say “show me the violations and discrepancies in rank order of dollar value.” A hundred good accountants using a dedicated AI, that’s exactly the kind of story that leads to the order of magnitude increase in labor output that the biggest proponents of AI are looking for.
Never forget that the event that initially popped the dotcom bubble was Microstrategy getting caught cooking the books.
I know you can’t write history like a novel, but “IRS, previously destaffed by Musk-headed DOGE, is forced to use AI enabled audits and finds massive revenue discrepancies, leading to panicked sell-off of Musk-headed IPO record holding company and kicking off AI stock sell-off”…that’s too easy, right?
This is a “guest” blog post that I asked Google Gemini Pro to write. Data centers are increasingly becoming a political issue in communities across America. People are asking questions like: “Why do we need these things? How much water will this use?” Because these are sometimes referred to as “AI Data Centers,” people might assume that data centers are primarily about creating cat memes and fake videos. And it’s true that’s a part of AI, and it’s true that much of the new data center construction is for AI.
But… data centers have been around for a while. People are only now taking notice of them, for the most part. To better understand this issue, I asked — what else? — AI to explain how much data centers are used in our daily lives. AI in this case means Google Gemini Pro.
I’ll paste the full guest post below, but I want to point something out first: this blog post makes no mention of AI. Instead, it talks about: GPS and mapping apps; almost everything you do if you work in an office; credit cards and digital banking; news and social media. All of these things rely on data centers and would cease to function without data centers. That’s not because I asked Gemini to leave out AI from the guest post — when I followed up on this omission, Gemini said “It was a calculated omission—partly to keep the focus on the immediate ‘analog’ shock to daily life.” Most people probably wouldn’t care of they lost the ability to create funny images with AI. They would care if they lost all of their photos, access to their Dropbox account, and the ability to send email.
You could interpret all of this as saying we are “too dependent” on data centers and the modern Internet. You could also say we are “too dependent” on electricity. Or modern plumbing. Or modern supply chains. Or agriculture. Modern life is based on modern technology. I don’t know if it really makes sense to say we are “dependent” on these things, other than that we use them and they are beneficial.
Anyway, on to the guest post from Google Gemini Pro:
The Day the Cloud Evaporated: Life After the Data Center Collapse
Imagine waking up tomorrow morning in your suburban home in Ohio, or your apartment in Seattle. You reach for your smartphone to silence the alarm, but the screen is a stubborn, glowing rectangle of error messages. You try to check the weather, but the app’s spinning wheel never stops. You try to text your partner, but the message stays “Sending…” until it eventually fails.
This isn’t just a bad Wi-Fi connection. Every data center on Earth—those massive, humming warehouses filled with silicon and cooling fans—has vanished. In an instant, the “brain” of the modern world has been lobotomized. For the average person in the United States, life wouldn’t just slow down; it would fundamentally reset to 1950, but without the physical infrastructure of 1950 to catch the fall.
A native New Zealander, Tim Brown had two separate ambitions: to become a professional soccer player and a designer. On the soccer (“football”, outside North America) front, he succeeded beyond expectations. He played on the New Zealand national team between 2004 and 2012, often as captain or vice-captain. Brown executed a personal pivot in 2012. After retiring from soccer, he enrolled in the London School of Economics to learn the business skills needed to launch an idea he had been mulling for several years. This was a shoe made mainly of wool.
He wanted to give a boost to New Zealand’s declining sheep in industry (battered by competition from polyester textiles), and wanted to promote something more sustainable than the plasticky shoes that he was always being asked to endorse as a professional player. There seemed to be plenty of room in the half-billion dollar per year footwear industry for something more environmentally friendly.
Brown launched his idea on Kickstarter in 2014, raising over $100,000. He and his partner started selling the Allbirds Wool Runner in 2016. Their green vibe was perfect for that era, and their shoes became wildly popular among the Silicon Valley VC set. They were seen on Larry Page, Barack Obama, Leonardo DiCaprio, and a whole gaggle of Hollywood actors and actresses.
Allbirds expanded its product line, and opened brick and mortar stores on several continents. Allbirds went public in 2021, and its market value ran up to $4 billion. But then the novelty of wool shoes wore off, sustainability became less urgent, and it became widely known that these “Wool Runners” are too flimsy to actually run or exercise in. They are more like slippers, and folks outside of Hollywood or Silicon Valley were not eager to pay $150 for a pair of slippers. Also, better-capitalized competitors muscled into the sustainable footwear market. Sales slid down and down, management conflicts erupted, and founder Tim Brown left to pursue other interests. On April 1, Allbirds announced it was selling the remnants of its shoe business for an ignominious $39 million.
So far, the story is unremarkable – – as with so many other startups, idealistic founders have initial success, but eventually go under upon scale-up. But there is an interesting plot twist. Instead of just going chapter 7 BK, paying off creditors, and returning a few pennies to investors, the company is using the shell of its former business to generate capital and transform itself into a new AI venture of renting out computing centers for AI usage. I assume the managers wanted to keep their jobs as managers, and cooked up this scheme to traffic on the current AI hype.
Apparently, these guys know nothing about GPU centers, so they’ll have to hire folks with expertise. Some unknown investor is backing them to the tune of $50 million, but they will have to raise much more than that to compete in the AI server business. That will horribly dilute current stockholders. They are directly competing with much better-capitalized behemoths like CoreWeave and Oracle, that can raise money on better terms. No moat, no expertise, almost no capital. But, hey, it’s AI, and so the company stock BIRD soared 600% on the news of the computing pivot.
I give them modest odds of succeeding bigly, but sometimes a mission pivot like this does come off. I’m thinking of the 1960’s when Berkshire Hathaway, facing declining earnings from its core textile business, under the leadership of Warren Buffett shifted into insurance. That generated the “float” that then enabled the purchase of other profitable businesses. We shall see if Allbirds (soon to be “NewBird”) management can likewise preside over such a seismic business shift.
The latest AI model from Anthropic is so powerful that they don’t dare release it to the public. It is such a threat that Jay Powell and Scott Bessant summoned the major bank CEOs to a meeting last week to warn them about it. In line with Anthropic’s “helpful, honest, and harmless” motto, they have released it only to their Project Glasswing partners. These are organizations like AWS, Apple, Cisco, CrowdStrike, Google, JPMorgan Chase, the Linux Foundation, Microsoft, NVIDIA, and Palo Alto Networks, who have been granted access to the model to identify and patch vulnerabilities in critical software.
Mythos is designed to identify and exploit vulnerabilities in software systems when prompted. Its specialty is identifying critical software vulnerabilities and bugs, but it can also assemble sophisticated exploits.
What makes Mythos particularly unsettling is that its most dangerous capabilities were not deliberately engineered. Anthropic’s team made it clear that they did not explicitly train Mythos to have these capabilities. Instead, they “emerged.”
Internal testing revealed that Mythos has already uncovered thousands of weak points in “every major operating system and web browser.” The implications are disturbing. Claude Mythos has autonomously discovered thousands of zero-day vulnerabilities in major operating systems and web browsers— flaws that human security researchers, working for years, had never detected. (see also here and here for examples).
Mythos can rapidly uncover hidden flaws in the codes of organizations and software development firms, but it also raises the fear that attackers could find those vulnerabilities first. Much of the underlying software that Mythos can scan supports banking, retail, airlines, hospitals, and critical utilities. Regulators worry that if Mythos, or models like it, fell into the wrong hands, “systemically important” banks and even entire financial networks could be compromised before institutions even knew they were exposed.
Anthropic launched Project Glasswing in April 2026 to collaborate with tech giants and banks to identify and fix vulnerabilities before they can be exploited. This year, organizations should expect a large influx of AI-discovered hack points in critical software. The game plan is to use AI tools to patch the vulnerabilities it discovers. Your venerable legacy system is no longer safe. What AI can expose, it can also fix. We hope.
Ray Kurzweil predicted The Singularity (when artificial intelligence growth accelerates beyond human control) would arrive in 2045, but we might be closing in on it ahead of schedule.
One of Anthropic’s biggest wins has been its wildly-popular Claude Code program, that can do nearly all the grunt work of programming. Properly prompted, it can build new features, migrate databases, fix errors, and automate workflows.
So, it was big news in the AI world last week when an Anthropic employee accidently exposed a link that allowed folks to download the source code for this crown jewel – – the entire code, all 512,000 lines of it, which revealed the complete logic flow of the program, down to the tiniest features. For instance, Claude Code scans for profanity and negative phrases like “this sucks” to discern user sentiment, and tries to adjust for user frustration.
Gleeful researchers, competitors, and hackers promptly downloaded zillions of copies. Anthropic issued broad copyright takedown requests, but the damage was done. Researchers quickly used AI to rewrite the original TypeScript source code into Python and Rust, claiming to get around copyright laws on the original code. Oh, the irony: for years, AI purveyors have been arguing that when they ingest the contents of every published work (including copyrighted works) and repackage them, that’s OK. So now Anthropic is tasting the other side of that claim.
The leak has been damaging to Anthropic to some degree. Competitors don’t have to work to try to reverse engineer Claude Code, since now they know exactly how it works. Hackers have been quick to exploit vulnerabilities revealed by the leak. And Anthropic’s claim to be all about “Safety First” has been tarnished.
On the other hand, the model weights weren’t exposed, so you can’t just run the leaked code and get Claude’s results. Also, no customer data was revealed. Power users have been able to discern from the source how to run Claude Code most advantageously. This YouTube by Nick Puru discussed such optimizations, which he summarized in this roadmap:
There have actually been a number of unexpected benefits of the leak for Anthropic. Per AI:
Brand resonance and community engagement have surged, with some observers calling the incident “peak anthropic energy” that generated significant hype and validated the product’s technical impressiveness. The leak has acted as a massive free marketing campaign, reinforcing the narrative of a fast-moving, innovative company while bouncing the brand back among developers despite the security lapse.
Accelerated ecosystem adoption and bug fixing are also potential benefits, as the exposure allowed engineers to dissect the agentic harness and create open-source versions or “harnesses” that keep users within the Anthropic ecosystem. Additionally, the public scrutiny likely helps identify and patch vulnerabilities faster, while the leaked source maps provide a roadmap for competitors to build “Claude-like” agents, potentially standardizing the market around Anthropic’s architectural patterns.
The leak also revealed hidden roadmap features that build anticipation, such as:
Kairos: A persistent background daemon for continuous operation.
Proactive Mode: A feature allowing the AI to act without explicit user prompts.
Terminal Pets: Playful, personality-driven interfaces to increase user engagement.
Because of these benefits, conspiracy theorists have proposed that Anthropic leaked the code on purpose, or even (April Fools!) leaked fake code. Fact checkers have come to the rescue to debunk the conspiracy claims. But in the humans vs. AI competency debate, this whole kerfuffle doesn’t make humans look so great.
Last July I wrote here about “Humanity’s Last Exam”:
When every frontier AI model can pass your tests, how do you figure out which model is best? You write a harder test.
That was the idea behind Humanity’s Last Exam, an effort by Scale AI and the Center for AI Safety to develop a large database of PhD-level questions that the best AI models still get wrong.
One the one hand, it makes sense that the core author groups at the Center for AI Safety and Scale AI didn’t keep every coauthor in the loop, given that there were hundreds of us. On the other hand, I’m part of a different academic mega-project that currently is keeping hundreds of coauthors in the loop as it works its way through Nature. On the third, invisible hand, I’m never going to complain if any of my coauthors gets something of ours published in Nature when I’d assumed it would remain a permanent working paper.
What do we do when it can answer all the questions we already know the answer to? We start asking it questions we don’t know the answer to. How do you cure cancer? What is the answer to life, the universe, and everything? When will Jesus return, and how long until a million people are convinced he’s returned as an AI? Where is Ayatollah Khamenei right now?
At the link, I speculate on doom, hardware, human jobs, the jagged edge (via a Joshua Gans working paper), and the Manhattan Project. The fun thing about being 6 years late to a seminal paper is that you can consider how its predictions are doing.
Sutton draws from decades of AI history to argue that researchers have learned a “bitter” truth. Researchers repeatedly assume that computers will make the next advance in intelligence by relying on specialized human expertise. Recent history shows that methods that scale with computation outperform those reliant on human expertise. For example, in computer chess, brute-force search on specialized hardware triumphed over knowledge-based approaches. Sutton warns that researchers resist learning this lesson because building in knowledge feels satisfying, but true breakthroughs come from computation’s relentless scaling.
The article has been up for a week and some intelligent comments have already come in. Folks are pointing out that I might be underrating the models’ ability to improve themselves going forward.
Second, with the frontier AI labs driving toward automating AI research the direct human involvement in developing such algorithms/architectures may be much less than it seems that you’re positing.
If that commenter is correct, there will be less need for humans than I said.
Also, Jim Caton over on LinkedIn (James, are we all there now?) pointed out that more efficient models might not need more hardware. If the AIs figure out ways to make themselves more efficient, then is “scaling” even going to be the right word anymore for improvement? The fun thing about writing about AI is that you will probably be wrong within weeks.
Between the time I proposed this to Econlog and publication, Ilya Sutskever suggested on Dwarkesh that “We’re moving from the age of scaling to the age of research“.
Tech stocks (e.g. QQQ) roared up and up and up for most of 2023-2025, more than doubling in those three years. A big driving narrative was how AI was going to make everything amazing – productivity (and presumably profits) would soar, and robust investments in computing capacity (chips and buildings), and electric power infrastructure buildout, would goose the whole economy.
Will the Enormous AI Capex Spending Really Pay Off?
But in the past few months, a different narrative seems to have taken hold. Now the buzz is “the dark side of AI”. First, there is growing angst among investors over how much money the Big Tech hyperscalers (Google, Meta, Amazon, Microsoft, plus Oracle) are pouring into AI-related capital investments. These five firms alone are projected to spend over $0.6 trillion (!) in 2026. When some of this companies announced greater than expected spends in recent earning calls, analysts threw up all over their balance sheets. These are just eye-watering amounts, and investors have gotten a little wobbly in their support. These spends have an immediate effect on cash flow, driving it in some cases to around zero. And the depreciation on all that capex will come back to bite GAAP earnings in the coming years, driving nominal price/earnings even higher.
The critical question here is whether all that capex will pay out with mushrooming earnings three or four years down the road, or is the life blood of these companies just being flushed down the drain? This is viewed as an existential arms race: benefits are not guaranteed for this big spend, but if you don’t do this spending, you will definitely get left behind. Firms like Amazon have a long history of investing for years at little profit, in order to achieve some ultimately profitable, wide-moat quasi-monopoly status. If one AI program can manage to edge out everyone else, it could become the default application, like Amazon for online shopping or Google/YouTube for search and videos. The One AI could in fact rule us all.
Many Companies May Get Disrupted By AI
We wrote last week on the crash in enterprise software stocks like Salesforce and ServiceNow (“SaaSpocalypse”). The fear is that cheaper AI programs can do what these expensive services do for managing corporate data. The fear is now spreading more broadly (“AI Scare Trade”); investors are rotating out of many firms with high-fee, labor-driven service models seen as susceptible to AI disruption. Here are two representative examples:
Wealth management companies Charles Schwab and Raymond James dropped 10% and 8% last week after a tech startup announced an AI-driven tax planning tool that could customize strategies for clients
Freight logistics firms C.H. Robinson and Universal Logistics fell 11% and 9% after some little AI outfit announced freight handling automation software
These AI disruption scenarios have been known for a long time as possibilities, but in the present mood, each new actual, specific case is feeding the melancholy narrative.
All is not doom and gloom here, as investors flee software companies they are embracing old-fashioned makers of consumer goods and other “stuff”:
The narrative last week was very clearly that “physical” was a better bet than “digital.” Physical goods and resources can’t be replaced by AI like digital goods and services can be at an alarming rate
As I write this (Monday), U.S. markets are closed for the holiday. We will see in the coming week whether fear or greed will have the upper hand.