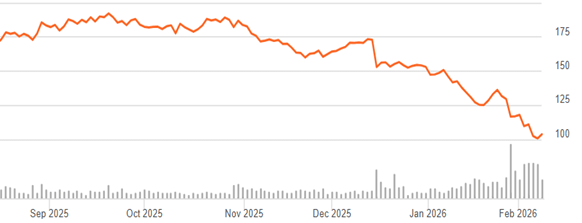
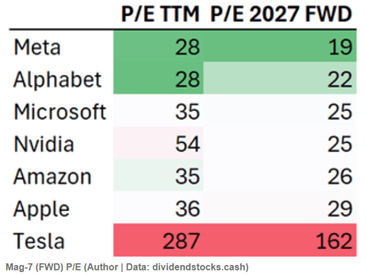
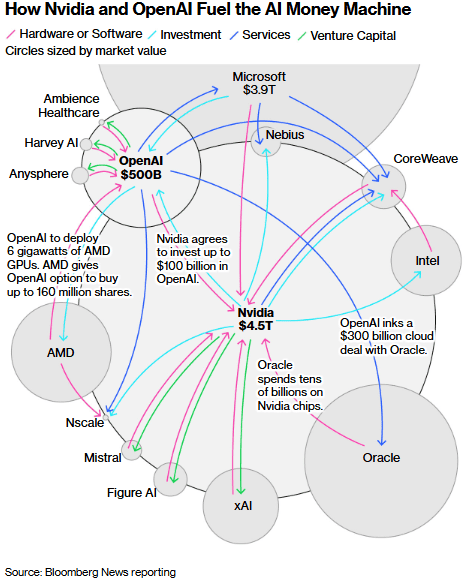
We noted last week Meta’s successful efforts to hire away the best of the best AI scientists from other companies, by offering them insane (like $300 million) pay packages. Here we summarize and excerpt an excellent article in Newsweek by Gabriel Snyder who interviewed Meta’s chief AI scientist, Yann LeCun. LeCun discusses some inherent limitations of today’s Large Language Models (LLMs) like ChatGPT. Their limitations stem from the fact that they are based mainly on language; it turns out that human language itself is a very constrained dataset. Language is readily manipulated by LLMs, but language alone captures only a small subset of important human thinking:
Returning to the topic of the limitations of LLMs, LeCun explains, “An LLM produces one token after another. It goes through a fixed amount of computation to produce a token, and that’s clearly System 1—it’s reactive, right? There’s no reasoning,” a reference to Daniel Kahneman’s influential framework that distinguishes between the human brain’s fast, intuitive method of thinking (System 1) and the method of slower, more deliberative reasoning (System 2).
The limitations of this approach become clear when you consider what is known as Moravec’s paradox—the observation by computer scientist and roboticist Hans Moravec in the late 1980s that it is comparatively easier to teach AI systems higher-order skills like playing chess or passing standardized tests than seemingly basic human capabilities like perception and movement. The reason, Moravec proposed, is that the skills derived from how a human body navigates the world are the product of billions of years of evolution and are so highly developed that they can be automated by humans, while neocortical-based reasoning skills came much later and require much more conscious cognitive effort to master. However, the reverse is true of machines. Simply put, we design machines to assist us in areas where we lack ability, such as physical strength or calculation.
The strange paradox of LLMs is that they have mastered the higher-order skills of language without learning any of the foundational human abilities. “We have these language systems that can pass the bar exam, can solve equations, compute integrals, but where is our domestic robot?” LeCun asks. “Where is a robot that’s as good as a cat in the physical world? We don’t think the tasks that a cat can accomplish are smart, but in fact, they are.”
This gap exists because language, for all its complexity, operates in a relatively constrained domain compared to the messy, continuous real world. “Language, it turns out, is relatively simple because it has strong statistical properties,” LeCun says. It is a low-dimensionality, discrete space that is “basically a serialized version of our thoughts.”
[Bolded emphases added]
Broad human thinking involves hierarchical models of reality, which get constantly refined by experience:
And, most strikingly, LeCun points out that humans are capable of processing vastly more data than even our most data-hungry advanced AI systems. “A big LLM of today is trained on roughly 10 to the 14th power bytes of training data. It would take any of us 400,000 years to read our way through it.” That sounds like a lot, but then he points out that humans are able to take in vastly larger amounts of visual data.
Consider a 4-year-old who has been awake for 16,000 hours, LeCun suggests. “The bandwidth of the optic nerve is about one megabyte per second, give or take. Multiply that by 16,000 hours, and that’s about 10 to the 14th power in four years instead of 400,000.” This gives rise to a critical inference: “That clearly tells you we’re never going to get to human-level intelligence by just training on text. It’s never going to happen,” LeCun concludes…
This ability to apply existing knowledge to novel situations represents a profound gap between today’s AI systems and human cognition. “A 17-year-old can learn to drive a car in about 20 hours of practice, even less, largely without causing any accidents,” LeCun muses. “And we have millions of hours of training data of people driving cars, but we still don’t have self-driving cars. So that means we’re missing something really, really big.”
Like Brooks, who emphasizes the importance of embodiment and interaction with the physical world, LeCun sees intelligence as deeply connected to our ability to model and predict physical reality—something current language models simply cannot do. This perspective resonates with David Eagleman’s description of how the brain constantly runs simulations based on its “world model,” comparing predictions against sensory input.
For LeCun, the difference lies in our mental models—internal representations of how the world works that allow us to predict consequences and plan actions accordingly. Humans develop these models through observation and interaction with the physical world from infancy. A baby learns that unsupported objects fall (gravity) after about nine months; they gradually come to understand that objects continue to exist even when out of sight (object permanence). He observes that these models are arranged hierarchically, ranging from very low-level predictions about immediate physical interactions to high-level conceptual understandings that enable long-term planning.
[Emphases added]
(Side comment: As an amateur reader of modern philosophy, I cannot help noting that these observations about the importance of recognizing there is a real external world and adjusting one’s models to match that reality call into question the epistemological claim that “we each create our own reality”.)
Given all this, developing the next generation of artificial intelligence must, like human intelligence, embed layers of working models of the world:
So, rather than continuing down the path of scaling up language models, LeCun is pioneering an alternative approach of Joint Embedding Predictive Architecture (JEPA) that aims to create representations of the physical world based on visual input. “The idea that you can train a system to understand how the world works by training it to predict what’s going to happen in a video is a very old one,” LeCun notes. “I’ve been working on this in some form for at least 20 years.”
The fundamental insight behind JEPA is that prediction shouldn’t happen in the space of raw sensory inputs but rather in an abstract representational space. When humans predict what will happen next, we don’t mentally generate pixel-perfect images of the future—we think in terms of objects, their properties and how they might interact…
This approach differs fundamentally from how language models operate. Instead of probabilistically predicting the next token in a sequence, these systems learn to represent the world at multiple levels of abstraction and to predict how their representations will evolve under different conditions.
And so, LeCun is strikingly pessimistic on the outlook for breakthroughs in the current LLM’s like ChatGPT. He believes LLMs will be largely obsolete within five years, except for narrower purposes, and so he tells upcoming AI scientists to not even bother with them:
His belief is so strong that, at a conference last year, he advised young developers, “Don’t work on LLMs. [These models are] in the hands of large companies, there’s nothing you can bring to the table. You should work on next-gen AI systems that lift the limitations of LLMs.”
This approach seems to be at variance with other firms, who continue to pour tens of billions of dollars into LLMs. Meta, however, seems focused on next-generation AI, and CEO Mark Zuckerberg is putting his money where his mouth is.