It’s feeling like the late ’90s, with an impressive new technology pushing tech stocks and the broader US market to all-time highs. Retail investors are using new platforms to get in on the action, tech companies are doing more IPOs to take advantage of the higher stock prices, and other companies are trying to boost their stocks by saying they are pivoting to the new technology (though often they aren’t really changing).
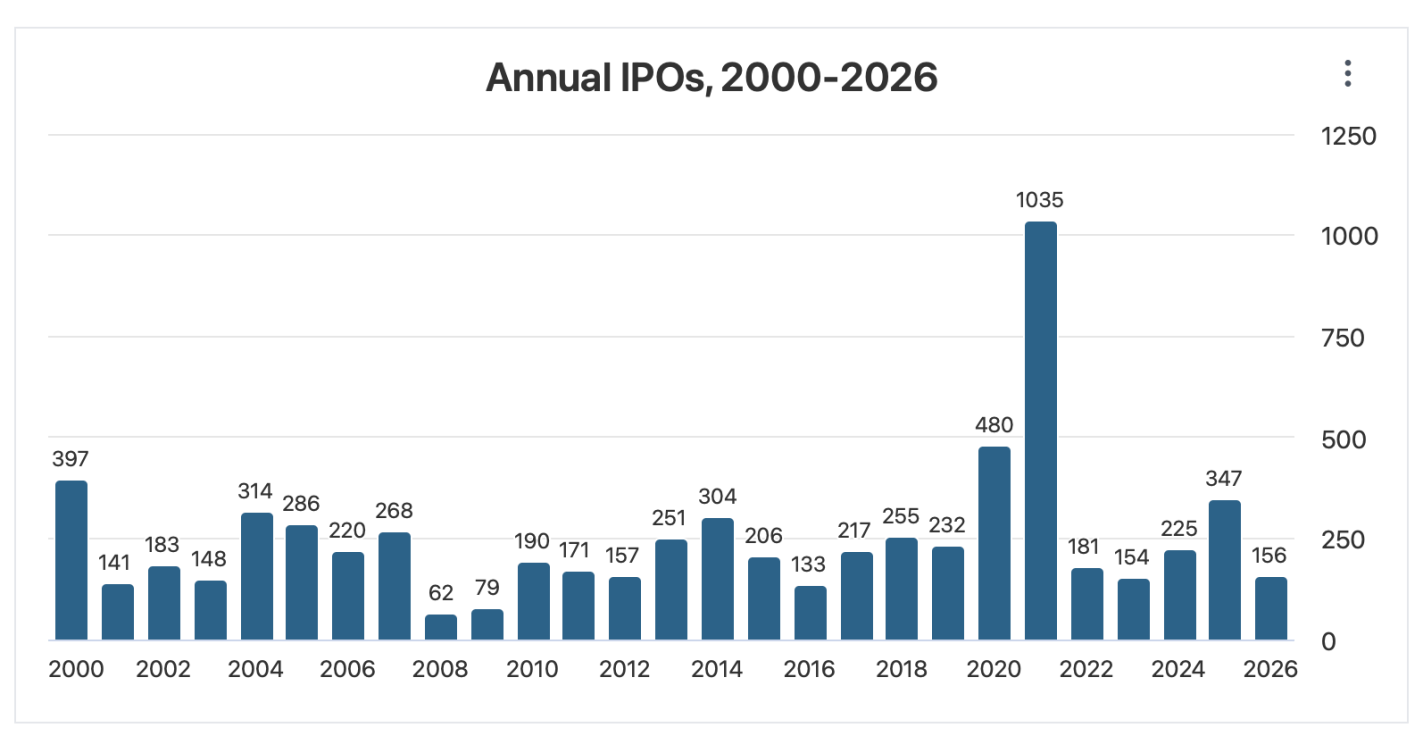
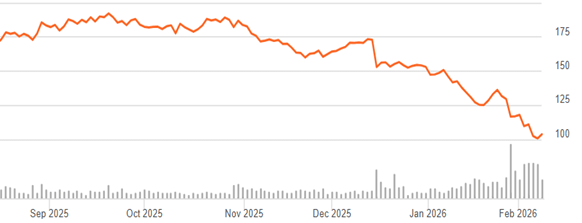
The excitement drives valuations to record levels:
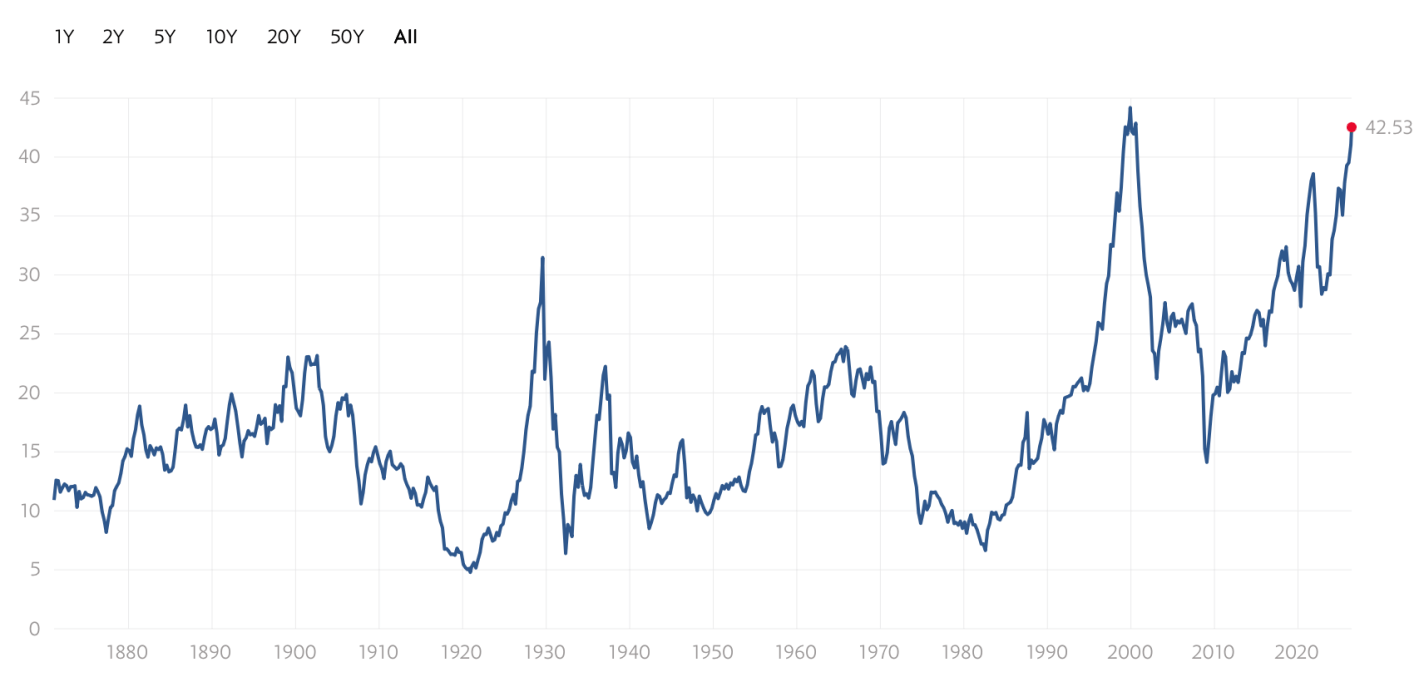
In the ’90s, the internet really was a transformational new technology that would enable lots of profitable new companies. But the market got ahead of itself, a bubble that led to a crash- the S&P fell by almost half, while the tech-heavy NASDAQ fell by over 3/4 and took 15 years to recover.
History rhymes, but it doesn’t repeat exactly. I don’t currently expect a big crash driven by AI stocks; it helps that unlike in the ’90s, many of the big players are currently profitable. But I also don’t expect the NASDAQ to keep posting 20+% returns every year.
If the AI bull market doesn’t end in a dramatic crash, how will it end? It’s already shrugged off a war. A US recession is unlikely this year, though plausible next year.
The end I see slowly approaching comes from crowding out. What Robert Solow said about computers in 1987 is true about AI today: you see the AI age everywhere except the productivity statistics. There’s only so much money to go around in markets when productivity growth is unexceptional and savings rates are falling.
We’re already seeing the war hit certain markets (if not US stocks). Iran’s gulf neighbors are now putting lots of money into missile defense, money they now won’t be spending on data centers or gold (down 16% from pre-war), and everyone else has to spend more on oil.
Interest rates have been rising- partly due to central bank attempts to fight inflation, partly due to ongoing high rates of government borrowing, and partly due to financing the AI buildout itself. Higher rates make it more expensive for companies to invest in the physical AI buildout, and make investors discount future AI revenues more while making bonds a more attractive substitute for stocks today. 10-year TIPS now yield 2% over the inflation rate, a sharp contrast to the 2021 stock boom when they yielded less than inflation. If I were older I’d be loading up on TIPS, and even at 38 I’m starting to get tempted.
Trying to call the top exactly is a fool’s errand, but if I were feeling foolish, I’d point to the big upcoming IPOs. SpaceX just filed for an IPO that would be the biggest ever both for the amount of money raised ($75 billion) and the total company valuation ($1.77 trillion). This shatters the previous records for the biggest overall raise ($29 billion raised by Saudi Aramco when it went public in 2019) and the biggest raise by an American company ($18 billion raised by Visa in 2008). OpenAI and Anthropic are likely to follow with IPOs that would also break the previous records- making 3 companies each trying to raise more than the $45 billion raised by the entire US IPO market in 2025. Even if the process of going public doesn’t reveal any flaws in the companies, that money has to come from somewhere- and it takes up a substantial proportion of all net inflows to US stocks in a typical year (IPOs plus new money into existing stocks).
In short- where will the money come from? What are investors going to sell in order to buy into these IPOs? Technically they could do it all with cash, but I think it’s at least plausible that they start selling other stocks. The selling pressure will continue after the IPOs as employees of the newly-public companies see their stocks vest and other early investors become able to sell off.
I’m not trying to time the market. Even if this is a ’90s re-run, we could easily still be in the 1998 buildup, not the 2000 peak and crash. But I am diversifying. US stocks are currently the world’s most expensive. Investors value US stocks that highly because there’s a real chance that US companies are profitably building the technologies that will drive the future. But there’s also a real chance they aren’t– and if that state of the world comes to pass, I’d prefer to own a significant chunk of bonds, foreign stocks, and real assets.