Wojak Meme Generator from Glif will build you a funny meme from a short phrase or single word prompt. Note that it is built to be derogatory, cruel for sport, and may hallucinate up falsehoods. (see tweet announcement)
I am fascinated by this from the angle of modern anthropology. The AI has learned all of this by studying what we write online. Someone can build an AI to make jokes and call out hypocrisy.
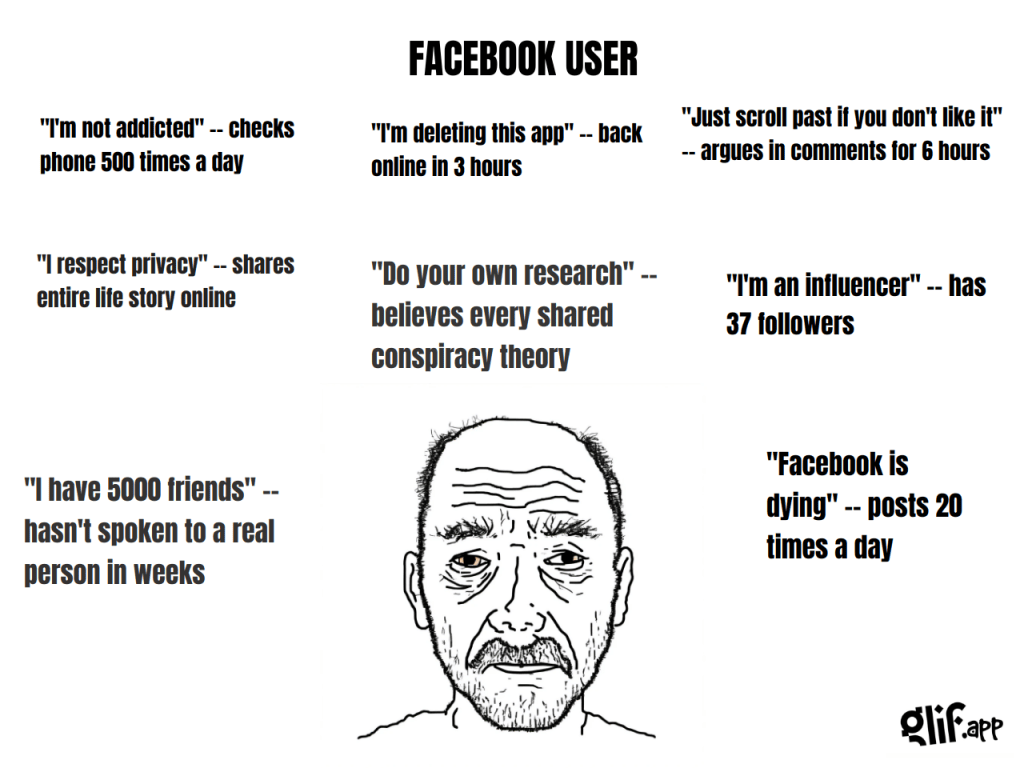
Here are GLIFs of the different social media user stereotypes as of 2024. Most of our current readers probably don’t need any captions to these memes, but I’ll provide a bit of sincere explanation to help everyone understand the jokes.
Twitter user: Person who posts short messages and follows others on the microblogging platform.
Facebook user: Individual with a profile on the social network for connecting with friends and sharing content.
Bluesky user: Early adopter of a decentralized social media platform focused on user control.
Folks who follow the stock market know that the average company in the S&P 500 has gone essentially nowhere in the last couple of years. What has pulled the averages higher and higher has been the outstanding performance of a handful of big tech stocks. Foremost among these is Nvidia. Its share price has tripled in the past year, after nearly tripling in the previously twelve months. Its market value climbed to $3.3 trillion last week, briefly surpassing tech behemoths Microsoft and Apple as the most valuable company in the world.
What just happened here?
It all began in 1993 when Taiwanese-American electrical engineer Jensen Huang and two other Silicon Valley techies met in a Denny’s in East San Jose and decided to start their own company. Their focus was making graphics acceleration boards for video games. Computing devices such as computers, game stations, and smart phones have at their core a central processing unit, CPU. A strength of CPUs is their versatility. They can do a lot of different tasks, but sequentially and thus at a limited speed. To oversimplify, a CPU fetches an instruction (command), and then loads maybe two chunks of data, then performs the instructed calculations on those data, and then stores the result somewhere else, and then turns around and fetches the next instruction. With clever programming, some tasks can be broken up into multiple pieces that can be processed in parallel on several CPU cores at once, but that only goes so far.
Processing large amounts of graphics data, such as rendering a high-resolution active video game, requires an enormous amount of computing. However, these calculations are largely all the same type, so a versatile processing chip like a CPU is not required. Graphics processing units (GPUs), originally termed graphics accelerators, are designed to do enormous number of these simple calculations simultaneously. To offload the burden on the CPU, computers and game stations for decades have included on auxiliary GPU (“graphics card”) alongside the CPU.
This was the original target for Nvidia. Video gaming was expanding rapidly, and they saw a niche for innovative graphics processors. Unfortunately, they the processing architecture they choose to work on fell out of favor, and they skated right up to the edge of going bankrupt. In 1993 Nvidia was down to 30 days before closing their doors, but at the last moment they got a $5 million loan to keep them afloat. Nvidia clawed its way back from the brink and managed to make and sell a series of popular graphics processors.
However, management had a vision that the massively parallel processing power of their chips could be applied to more exulted uses than rendering blood spatters in Call of Duty. The types of matrix calculations done in GPUs can be used in a wide variety of physical simulations such as seismology and molecular dynamics. In 2007, and video released its CUDA platform for using GPUs for accelerated general purpose processing. Since then, Nvidia has promoting the use of its GPUs as general hardware for scientific computing, in addition to the classic graphics applications.
This line of business exploded starting around 2019, with the bitcoin craze. Crypto currencies require enormous amount of computing power, and these types of calculations are amenable to being performed in massively parallel GPUs. Serious bitcoin mining companies set up racks of processors, built on NVIDIA GPUs. GPUs did have serious competition from other types of processors for the crypto mining applications, so they did not have the field to themselves. With people stuck at home in 2020-2021, demand for GPUs rose even further: more folks sitting on couches playing video games, and more cloud computing for remote work.
Nvidia Dominates AI Computing
Now the whole world cannot get enough of machine learning and generative AI. And Nvidia chips totally dominate that market. Nvidia supplies not only the hardware (chips) but also a software platform to allow programmers to make use of the chips. With so many programmers and applications standardized now on the Nvidia platform, its dominance and profitability should persist for many years.
Nearly all their chips are manufactured in Taiwan, so that provides a geopolitical risk, not only for Nvidia but for all enterprises that depend on high end AI processing.
Patel: We are talking about GPT-5 level models. What do you think will happen with GPT-6, GPT-7? Do you still think of it like having a bunch of RAs (research assistants) or does it seem like a different thing at some point?
Cowen: I’m not sure what those numbers going up mean or what a GPT-7 would look like or how much smarter it could get. I think people make too many assumptions there. It could be the real advantages are integrating it into workflows by things that are not better GPTs at all. And once you get to GPT, say 5.5, I’m not sure you can just turn up the dial on smarts and have it, for example, integrate general relativity and quantum mechanics.
Patel: Why not?
Cowen: I don’t think that’s how intelligence works. And this is a Hayekian point. And some of these problems, there just may be no answer. Like maybe the universe isn’t that legible. And if it’s not that legible, the GPT-11 doesn’t really make sense as a creature or whatever.
Patel (37:43) : Isn’t there a Hayekian argument to be made that, listen, you can have billions of copies of these things. Imagine the sort of decentralized order that could result, the amount of decentralized tacit knowledge that billions of copies talking to each other could have. That in and of itself is an argument to be made about the whole thing as an emergent order will be much more powerful than we’re anticipating.
Cowen: Well, I think it will be highly productive. What tacit knowledge means with AIs, I don’t think we understand yet. Is it by definition all non-tacit or does the fact that how GPT-4 works is not legible to us or even its creators so much? Does that mean it’s possessing of tacit knowledge or is it not knowledge? None of those categories are well thought out …
It might be significant that LLMs are no longer legible to their human creators. More significantly, the universe might not be legible to intelligence, at least of the kind that is trained on human writing. I (Joy) gathered a few more notes for myself.
(37:00) Tyler expresses skepticism that GPT-N can scale up its intelligence that far, that beyond 5.5 maybe integration with other systems matters more, and says ‘maybe the universe is not that legible.’ I essentially read this as Tyler engaging in superintelligence denialism, consistent with his idea that humans with very high intelligence are themselves overrated, and saying that there is no meaningful sense in which intelligence can much exceed generally smart human level other than perhaps literal clock speed.
I (Joy) took it more literally. I don’t see “superintelligence denialism.” I took it to mean that the universe is not legible to our brand of intelligence.
There is one other comment I found in response to a short clip posted by @DwarkeshPatel by youtuber @trucid2
Intelligence isn’t sufficient to solve this problem, but isn’t for the reason he stated. We know that GR and QM are inconsistent–it’s in the math. But the universe has no trouble deciding how to behave. It is consistent. That means a consistent theory that combines both is possible. The reason intelligence alone isn’t enough is that we’re missing data. There may be an infinite number of ways to combine QM and GR. Which is the correct one? You need data for that.
I saved myself a little time by writing the following with ChatGPT. If the GPT got something wrong in here, I’m not qualified to notice:
Newtonian physics gave an impression of a predictable, clockwork universe, leading many to believe that deeper exploration with more powerful microscopes would reveal even greater predictability. Contrary to this expectation, the advent of quantum mechanics revealed a bizarre, unpredictable micro-world. The more we learned, the stranger and less intuitive the universe became. This shift highlighted the limits of classical physics and the necessity of new theories to explain the fundamental nature of reality. General Relativity (GR) and Quantum Mechanics (QM) are inconsistent because they describe the universe in fundamentally different ways and are based on different underlying principles. GR, formulated by Einstein, describes gravity as the curvature of spacetime caused by mass and energy, providing a deterministic framework for understanding large-scale phenomena like the motion of planets and the structure of galaxies. In contrast, QM governs the behavior of particles at the smallest scales, where probabilities and wave-particle duality dominate, and uncertainty is intrinsic.
The inconsistencies arise because:
Mathematical Frameworks: GR is a classical field theory expressed through smooth, continuous spacetime, while QM relies on discrete probabilities and quantized fields. Integrating the continuous nature of GR with the discrete, probabilistic framework of QM has proven mathematically challenging.
Singularities and Infinities: When applied to extreme conditions like black holes or the Big Bang, GR predicts singularities where physical quantities become infinite, which QM cannot handle. Conversely, when trying to apply quantum principles to gravity, the calculations often lead to non-renormalizable infinities, meaning they cannot be easily tamed or made sense of.
Scales and Forces: GR works exceptionally well on macroscopic scales and with strong gravitational fields, while QM accurately describes subatomic scales and the other three fundamental forces (electromagnetic, weak nuclear, and strong nuclear). Merging these scales and forces into a coherent theory that works universally remains an unresolved problem.
Ultimately, the inconsistency suggests that a more fundamental theory, potentially a theory of quantum gravity like string theory or loop quantum gravity, is needed to reconcile the two frameworks.
P.S. I published “AI Doesn’t Mimic God’s Intelligence” at The Gospel Coalition. For now, at least, there is some higher plane of knowledge that we humans are not on. Will AI get there? Take us there? We don’t know.
For the first time this week, I paid for a subscription to an LLM. I know economists who have been on the paid tier of OpenAI’s ChatGPT since 2023, using it for both research and teaching tasks.
I have nothing against ChatGPT. For various reasons, I never paid for it, even though I used it occasionally for routine work or for writing drafts. Perhaps if I were on the paid tier of something else already, I would have resisted paying for Claude.
Yesterday, I made an account with Claude to try it out for free. Claude and I started working together on a paper I’m revising. Claude was doing excellent work and then I ran out of free credits. I want to finish the revision this week, so I decided to start paying $20/month.
Here’s a little snapshot of our conversation. Claude is writing R code which I run in RStudio to update graphs in my paper.
This coding work is something I used to do myself (with internet searches for help). Have I been 10x-ed? Maybe I’ve been 2x-ed.
I’ll refer to Zuckerberg via Dwarkesh (which I’ve blogged about before):
My old Honda Civic was a fairly small sedan. It had a 1.8 liter engine, that generated about 140 horsepower. It would not win any drag races, but had functional acceleration.
I recently got a Honda CR-V, a much larger, heavier vehicle. I was nonplussed to learn that it only had a 1.5 liter engine. Would I have to get out and push it up steep hills? As it turns out, this small engine can crank out some 190 horsepower. Given the size of this crossover SUV, this still does not make for a peppy drive, but at least I can actually pass another car as needed.
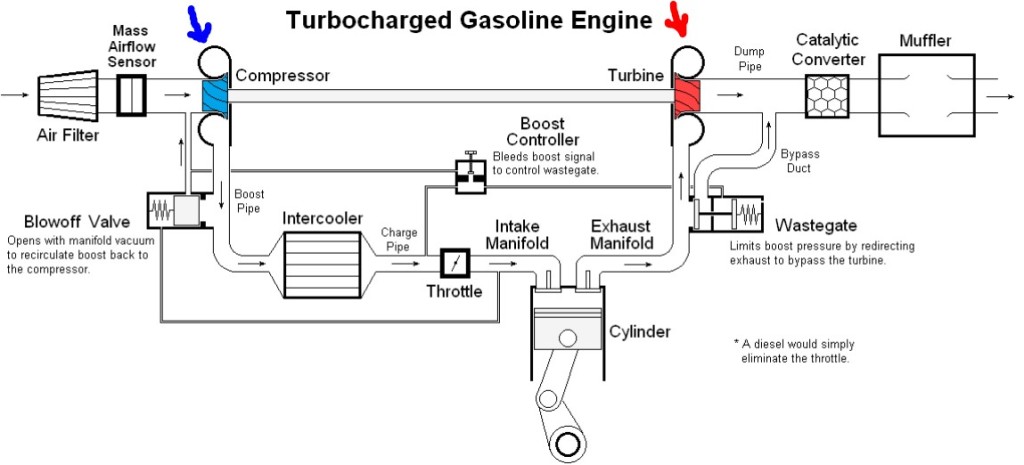
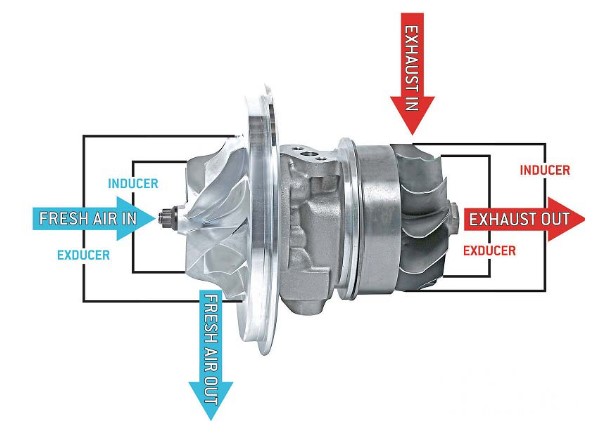
This high power with small engine displacement is made possible by the magic of turbocharging. As the (hot, expanded) exhaust gas leaves the engine, it goes through a turbine and makes it spin. A connected power shaft then spins a compressor, which takes outside air and jams it into the engine at higher pressure, i.e., higher density. With extra air stuffed into the engine cylinders, the engine can inject extra gasoline (keeping the air/fuel ratio roughly constant) – -and voila, high power output.
A schematic of this setup is shown below. I drew in a red arrow to mark the exhaust turbine, and a blue arrow for the intake air compressor. The rest should be fairly self-explanatory.
When the engine is turning at low-moderate speeds (say below 2000-3000 RPM), the turbine is doing relatively little, and so you are essentially driving around with a small (1.5 L) engine. This is good for gas mileage. When you floor it, the engine spins up and the turbo boost kicks in, giving considerably more power. [1]
What’s not to like? Apart from the potential maintenance headache of a rapidly spinning, complex chunk of precision machinery, there are a couple of issues with driving turbocharged engines that drivers should be aware of. There are articles and videos (see good comments there) that address these and other issues in some detail.
( A ) Time Lag Before Turbo Boost Kicks In
With a normal non-turbo engine, you can feel the power kick in nearly immediately when you depress the pedal. The pedal opens the throttle, and instantly the engine is gulping more air (and fuel).
With a turbo, there can be a detectible time lag. The engine must rev up until the turbo effect starts to kick in, and then it spins faster, and there is more air shoved into the engine. As long as you know this, you can drive accordingly. This might be a life and death matter if as you are in the middle of passing a car on a two-lane highway, and suddenly an oncoming car appears in your passing lane. If you are not up to full power by that point, such that you can complete the passing quickly, you could become a statistic. I have only faced that situation maybe once every ten years in my driving, but it should be figured in.
The actual time lag varies from one model to another. I’d suggest just testing this out on your car. In some safe driving scenario, floor it and assess how much of a lag there is.
( B ) Don’t turn the engine off immediately if it has been running fast.
The thought here is to let the engine slow down to idle, and maybe even cool down a hair, before turning it off. The reason is that if the engine is revving at say 2000 rpm, and you suddenly turn the engine off, the oil pumping action stops, but the turbo is still spinning away in there. Having the turbine spinning away with no oil circulation can wreck the bushings.
There are articles and videos (see good comments there) that address these and other issues in some detail.
Comment on Driving Honda CR-V Turbo Engine
Various engines have been used in CR-Vs. The 1.5 L turbo has been common in North America since 2017. It was designed to not have a very noticeable lag, in the sense that nothing happens for two seconds, and then the vehicle lurches forward. The turbo effect reportedly starts to kick in at 2000 rpm. However, this effect is progressive, so the power at 2000-3000 rpm is still modest. So, if you just push halfway down on the accelerator, the response is modest. If you floor it, the engine will within a second or two scream up to like 5000 rpm, and then start to really accelerate. That said, I have a visceral aversion to revving my engines that close to the red-line danger zone on the tachometer (my previous non-turbo cars I never took above about 3500 rpm, never needed to). Even with all that revving, the net acceleration is still modest.
Another factor with driving a CR-V is the “Econ” fuel-saving engine setting. When that is on, it seems to prevent the engine from revving over about 3500 rpm. So, if I plan to pass another car, or if I need power for some other reason, I need to remember to punch the leafy green Econ button to turn off this mode.
The bottom line is that I will think twice, maybe thrice, before passing another vehicle on a two-lane road in my CR-V.
ENDNOTE
[1] That is the theory anyway: great gas mileage most of the time, and bursts of power available for those rare times when you need it. The reality seems to be a little different. There may be reason to believe that turbocharged small engines give good idealized EPA test gas mileage numbers, but that in ordinary driving, the results are not so great. The turbo is never actually turned off, it just contributes more or less at various RPMs. The turbocharging forces the manufacturer to adjust the air/fuel mixture to be less efficient, in order to avoid knock. So, the manufacturer may be essentially manipulating things to look good on the EPA tests. A larger engine, where some of the cylinders are shut off when not under load, may be more efficient. See video.
I’m back from Manifest, a conference on prediction markets, forecasting, and the future. It was an incredible chance to hear from many of my favorite writers on the internet, along with the CEOs of most major prediction markets; in Steve Hsu’s words, Woodstock for Nerds. Some highlights:
Robin Hanson took over my session on academic research on prediction markets (in a good way; once he was there everyone just wanted to ask him questions). He thinks the biggest current question for the field is to figure out why is the demand for prediction markets so low. What are the different types of demand, and which is most likely to scale? In a different talk, Robin says that we need to either turn the ship of world culture, or get off in lifeboats, before falling fertility in a global monoculture wrecks it.
Play-money prediction markets were surprisingly effective relative to real-money ones in the 2022 midterms. Stephen Grugett, co-founder of Manifold (the play-money prediction market that put on the conference), admitted that success in one election could simply be a coincidence. He himself was surprised by how well they did in the 2022 midterms, and said he lost a bunch of mana on bets assuming that Polymarket was more accurate.
Substack CEO Chris Best: No one wants to pay money for internet writing in the abstract, but everyone wants to pay their favorite writer. For me, that was Scott Alexander. We are trying to copy Twitter a bit. Wants to move into improving scientific publishing. I asked about the prospects of ending the feud with Elon; Best says Substack links aren’t treated much worse than any other links on X anymore.
Razib Khan explained the strings he had to pull for his son to be the first to get a whole genome sequence in utero back in 2014- ask the hospital to do a regular genetic test, ask them for the sample, get a journalist to tweet at them when they say no, get his PI’s lab to run the sample. He thinks crispr companies could be at the nadir of the hype cycle (good time to invest?).
Kalshi cofounder Luana Lopes Lara says they are considering paying interest on long term markets, and offering margin. There is enough money in it now that their top 10 or so traders are full time (earning enough that they don’t need a job). The CFTC has approved everything we send them except for once (elections). We don’t think their current rule banning contest markets will go through, but if it does we would have to take down Oscar and Grammy markets. When we get tired of the CFTC, we joke that we should self certify shallot futures markets (toeing the line of the forbidden onion futures). Planning to expand to Europe via brokerages. Added bounty program to find rules problems. Launching 30-50 markets per week now (seems like a good opportunity, these can’t all be efficient right?).
There was lots else of interest, but to keep things short I’ll just say it was way more fun and informative doing yet another academic conference, where I’ve hit diminishing returns. More highlights from Theo Jaffee here; I also loved economist Scott Sumner’s take on a similar conference at the same venue in Berkeley:
If you spend a fair bit of time surrounded by people in this sector, you begin to think that San Francisco is the only city that matters; everywhere else is just a backwater. There’s a sense that the world we live in today will soon come to an end, replaced by either a better world or human extinction. It’s the Bay Area’s world, we just live in it.
When I give talks about AI, I often present my own research on ChatGPT muffing academic references. By the end I make sure that I present some evidence of how good ChatGPT can be, to make sure the audience walks away with the correct overall impression of where technology is heading. On the topic of rapid advances in LLMs, interesting new claims from a person on the inside can by found from Leopold Aschenbrenner in his new article (book?) called “Situational Awareness.” https://situational-awareness.ai/ PDF: https://situational-awareness.ai/wp-content/uploads/2024/06/situationalawareness.pdf
He argues that AGI is near and LLMs will surpass the smartest humans soon.
AI progress won’t stop at human-level. Hundreds of millions of AGIs could automate AI research, compressing a decade of algorithmic progress (5+ OOMs) into ≤1 year. We would rapidly go from human-level to vastly superhuman AI systems. The power—and the peril—of superintelligence would be dramatic.
Based on this assumption that AIs will surpass humans soon, he draws conclusions for national security and how we should conduct AI research. (No, I have not read all if it.)
Isn't it true that the "smart high schooler" can just repeat what they learned in a textbook? Why is it a linear progression from there to an AI researcher who is producing novel brilliant papers?
I might offer to contract out my services in the future based on my human instincts shaped by growing up on internet culture (i.e. I know when they are joking) and having an acute sense of irony. How is Artificial General Irony coming along?
I recently did some business where I had a text file of names and email addresses that I wanted to send a group email to, in Gmail. Here I will share the steps I followed to import this info into a Google contact group.
The Big Picture
First, a couple of overall concepts. In Gmail (and Google), your contacts exist in a big list of all your contacts. To create a group of contacts for a mass email, you have to apply a label to those particular contacts. A given contact can have more than one label (i.e., can be member of more than one group).
To enter one new contact at a time into Gmail, you go to Contacts and Create Contact, and type in or copy/paste in data like name and email address for each person or organization. But to enter a list of many contacts all at once, you must have these contacts in the form of either a CSV or vCard file, which Google can import. So here, first I will describe the steps to create a CSV file, and then the steps to import that into Gmail.
Comma-separated values (CSV) is a text file format that uses commas to separate values. Each record (for us, this means each contact) is on a separate line of plain text. Each record consists of the same number of fields, and these are separated by commas in the CSV file.
A list of names and of email contacts (two fields) might look like this in CSV format:
We could have added additional data (more fields) for each contact, such as home phone numbers and cell numbers, again separated by commas.
For Gmail to import this as a contact list, this is not quite enough. Google demands a header line, to identify the meaning of these chunks of data (i.e., to tell Google that these are in fact contact names, followed by email addresses). This requires specific wording in the header. For a contact name and for one (out of a possible two) email address, the header entries would be “Name” and “E-mail 1 – Value”. If we had wanted to add, say, home phones and cell phones, we could have added four more fields to the header line, namely: ,Phone 1 - Type,Phone 1 - Value,Phone 2 - Type,Phone 2 – Value. For a complete list of possible header items, see the Appendix.
The Steps
Here are steps to create a CSV file of contacts, and then import that file to Gmail:
( 1 ) Start with a text file of the names and addresses, separated by commas. Add a header line at the top: Name, E-mail 1 – Value . If this is in Word, Save As a plain text file (.txt). For our little list, this text file would look like this:
( 2 ) Open this file in Excel: Start Excel, click Open, use Browse if necessary, select “All Files” (not just “Excel Files”) and find and select your text file. The Text Import Wizard will appear. Make sure the “Delimited” option is checked. Click Next.
In the next window, select “Comma” (not the default “Tab”) in the Delimiters section, then click “Next.” In the final window, you’ll need to specify the column data format. I suggest leaving it at “General,” and click “Finish.” If all has gone well, you should see an Excel sheet with your data in two columns.
( 3 ) Save the Excel sheet data as a CSV file: Under the File tab, choose Save As, and specify a folder into which the new file will be saved. A final window will appear where you specify the new file name (I’ll use “Close Friends List”), and the new file type. For “Save as type” there are several CSV options; on my PC I used “CSV (MS-DOS)”.
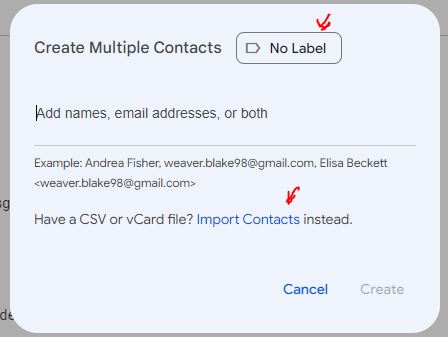
( 4 ) Go to Gmail or Google, and click on the nine-dots icon at the upper right, and select Contacts. At the upper left of the Contacts page, click Create Contact. You’ll have choice between Create a Contact (for single contact), or Create multiple contacts. Click on the latter.
( 5 ) Up pops a Create Multiple Contacts window. At the upper right of that window you can select what existing label (contact group name) you want to apply to this new list of names, or create a new label. For this example, I created (entered) a new label (in place of “No Label”), called Close Friends. Then, towards the bottom of this window, click on Import Contacts.
Then (in the new window that pops up) select the name of the incoming CSV file, and click Import. That’s it!
The new contacts will be in your overall contact list, with the group name label applied to them. There will also be a default group label “Imported on [today’s date]” created (also applied to this bunch of contacts). You can delete that label from the list of labels (bottom left of the Contacts page), using the “Keep the Contacts” option so the new contacts don’t get erased.
( 6 ) Now you can send out emails to this whole group of contacts. If this is a more professional or sensitive situation, or if the list of contacts is unwieldy (e.g. over ten or so), you might just send the email to yourself and bcc it to the labeled group.
APPENDIX: List of all Header Entries for CSV Files, for Importing Contacts to Gmail
I listed above several header entries which could be used to tell Google what the data is in your list of contact information. This Productivity Portfolio link has more detailed information. This includes tips for using VCard file format for transferring contact information (use app like Outlook to generate VCard or CSV file, then fix header info as needed, and then import that file into Google contacts).
There is also a complete list of header entries for a CSV file, which is available as an Excel file by clicking his “ My Google Contacts CSV Template “ button. The Excel spreadsheet format is convenient for lining things up for actual usage, but I have copied the long list of header items into a long text string to dump here, to give you the idea of what other header items might look like:
I bolded the two items I actually used in my example (Name and E-mail 1 – Value), as well as a pair of entries ( Phone 1 – Type and Phone 1 – Value) as header items which you might use for including, say, cell phone numbers in your CSV file of contact information.
Twice in the past year, I have received robo notices from doctors’ offices, blandly informing me that their systems have been penetrated, and that the bad guys have absconded with my name, phone number, address, social security number, medical records, and anything else needed to stalk me or steal my ID. As compensation for their failure to keep my information safe, they offer me – – – a year of ID theft monitoring. Thanks, guys.
And we hear about other data thefts, often on gigantic scales. For instance, this headline from a couple of months ago: “Substantial proportion” of Americans may have had health and personal data stolen in Change Healthcare breach”. By “substantial proportion” they mean about a third of the entire U.S. population (Change Healthcare, a subsidiary of UnitedHealth, processes nearly half of all medical claims in the nation). The House Energy and Commerce Committee last week called UnitedHealth CEO Sir Andrew Witty to testify on how this happened. As it turned out:
The attack occurred because UnitedHealth wasn’t using multifactor authentication [MFA], which is an industry standard practice, to secure one of their most critical systems.
UnitedHealth acquired Change Healthcare in 2022, and for the next two years did not bother to verify whether their new little cash cow was following standard protection practices on the sensitive information of around a hundred million customers. Sir Andrew could not give a coherent explanation for this lapse, merely repeating, “For some reason, which we continue to investigate, this particular server did not have MFA on it.”
But I can tell you exactly why this particular server did not have MFA on it: It was because Sir Andrew did not have enough personal liability for such a failure. If he knew that such an easily preventable failure would result in men in blue hauling him off to the slammer, I guarantee you that he would have made it his business within the first month of purchasing Change Healthcare to be all over the data security processes.
Humans do respond to carrots and sticks. The behaviorist school of psychology has quantified this tendency: establish a consistent system to reward behavior X and punish behavior not-X, and behaviors will change. As one example, Iin one corporate lab I worked in, a team of auditors from headquarters came one year for a routine, scheduled audit of the division’s operations. If the audit got less than the highest result, the career of the manager of the lab would be deeply crimped. Our young, ambitious lab manager made it crystal clear to the whole staff that for the next six months, the ONLY thing that really mattered was a spotless presentation on the audit. It didn’t matter (to this manager) how much productivity suffered on all the substantive projects in progress, as long as he was made to look good on the audit.
Let me move to another observation from my career in industry, working for a Certain Unnamed Large Firm, let’s called it BigCo. BigCo had very deep pockets. Lawyers loved to sue BigCo, and regulators loved to fine BigCo, big-time. And it would be a feather in the cap of said regulators, or other government prosecutors, to throw an executive of BigCo in the slammer.
Collusion among private companies to fix prices does do harm to consumers, by stifling competition and thereby raising prices. So, back in the day when regulators fiercely regulated, statutes were enacted making it a criminal act for company agents to engage in collusion, and authorizing severe financial penalties. American authorities were fairly aggressive about following up potential evidence, and over in Europe, police forces would engage in psychological warfare using their “dawn raid” tactic: just as everyone had sat down at their desks in the morning in would burst a SWAT team armed with submachine guns and lock the place down so no one could leave. I don’t know if the guns were actually loaded, but it was most unpleasant for the employees. BigCo’s main concern was avoiding multimillion dollar fines and restrictions on business that might result from a collusion conviction, so they devoted significant resources to training and motivating staff to avoid collusion.
Every year or two we researchers had to troop into a lecture hall (attendance was taken) and listen to the same talk by the same company lawyer, reminding us that corporations don’t go to jail, people (i.e. employees) go to jail, by way of motivating us to at all costs avoid even the appearance of colluding with other companies to fix prices or production or divide up markets or whatever. This was a live issue for us researchers, since some of us did participate in legitimate technical trade associations where matters were discussed like standardizing analytical tests. If memory serves, the lawyer advised us that if anyone in a trade association meeting, even in jest, made a remark bordering on a suggestion for collusion, we were to stand up, make a tasteful scene to make it memorable, and insist that the record show that the BigCo representative objected to that remark and left the meeting, and then stride out of the room. And maybe report that remark to a government regulator. That maybe sounds over the top, but I was told that just such a forceful response in a meeting actually saved BigCo from being subjected to a massive fine imposed on some other firms who did engage in collusion
My point is that if the penalties (on the corporate or managerial level) for carelessness are severe enough, the company WILL devote more substantial resources to preventing fails. It seems to me that the harm to we the people is far greater from having our personal data sucked out of health care and other company databases, than the harm from corporate collusion which might raise the price of copier paper or candle wax. Thus, I submit that if someone in the C-suite, like the chief information officer or the CEO, were liable to say 90 days in jail, management would indeed apply sufficient resources to data integrity to thwart the current routine data theft.
If I were king, this would be the policy in my realm. I recognize that in the current U.S. legal framework, the corporate structure shields management from much in the way of personal liability, and there are good reasons for that. I suppose another way to get at this is to have automatic fines structured to strip away nearly all shareholder value or management compensation, whilst still allowing the company to operate its business. This would be another route to put pressure on management to prioritize protection for their customers. Sir Andrew’s total compensation package has been running about $20 million/year. To my knowledge, the impact of the recent gigantic data breach on him has been fairly minimal in the big picture. Sure, it was aggravating for him to have to tell the U.S. Congress that he had no idea why his corporate division screwed up so badly, and to have to devote a good deal of effort to damage control, but I am guessing that his golf game (if he is a golfer) was not unduly impacted. He is still CEO, and collecting a princely compensation. But what if the laws were such that a major data hack would automatically result in a claw-back of say 95% of his past two years of compensation, and dismissal from any further management role in that company? I submit that such a policy would have motivated the good Sir Andrew to have devoted proper diligence and company resources to data integrity, such that this data breach would not have happened.
I don’t mean to pick on Andrew Witty as being uniquely negligent. By all accounts he is a nice guy, but his behavior is paradigmatic of ubiquitous benign management neglect, which has consequences for us little people.
These are just some personal musings; I’m sure readers can improve on these proposals.
Well, it’s finally over. As noted in previous blog posts, back when interest rates were essentially zero, I started an account with cryptocurrency investing firm BlockFi. They paid me a hefty 9% per year for lending out my crypto coin to “trusted institutional counterparties”, backed by large collateral. However, when Sam Bankman-Fried’s FTX exchange went belly up, it took BlockFi with it. (Bankman-Fried, the former rock-star white knight of the crypto world, is now in prison for fraud). My funds at BlockFi disappeared into the black hole of bankruptcy proceedings for about a year and a half.
Last month, a judge finally allowed a settlement for clients to withdraw their assets from their interest-bearing accounts. There were two wrinkles. First, you get far less than 100% of your funds. Most of my money got chewed up in the corporate bankruptcy itself, and then was eaten by the law firm (Kroll) processing the bankruptcy and the client reimbursement process. So, I’m only getting about 27% percent of my money back.
As an aside, Kroll got hacked about a year ago, leaking the names and email addresses of us BlockFi clients, and so some scammer sent out a very well-crafted email that a number of people, including me (briefly) were taken in by, as I wrote earlier. if you responded to that scam email, you ended up connecting your wallet to a scam application, which could then suck everything out of your wallet. Fortunately, I had almost nothing in my wallet for the short time I had it connected, but other victims lost considerable sums. I guess the reason why criminals continue to run crypto scams is because they are profitable, like the legendary bank robber Willie Sutton who robbed banks because “that’s where the money is.”
The other wrinkle In the BlockFi reimbursement is that they will only reimburse you with the actual cryptocurrency coin that you held, not with its dollar value. So, I had to set up a cryptocurrency wallet (I used Trust wallet) to receive my crypto, which was all in the form of the stablecoin USDC.
I had to do considerable background work to make this happen. In order to test that that wallet worked to receive USDC, I had to also set up a cryptocurrency exchange account, which I did with Coinbase (which seemed to be the most solid crypto exchange). I had to connect that account with my bank, put some money into the Coinbase exchange, buy some USDC, and send it to my crypto wallet to make sure that it all worked.
As of a week ago, after some fairly intrusive ID verification, the reimbursement machinery did finally deposit the measly remnants of my USDC into my wallet. OK, I thought, I’ll just transfer that to my Coinbase exchange account, turn the USDC into cash and be done with it all.
But not so fast… Because USDC is transferred over the Ethereum network, I had to have enough ETH coin in my Trust wallet to pay for the transfer. The network transfer cost, called the gas fee, was about eight dollars at midday, going down to about three dollars by 10 o’clock at night.
So, I had to go into my Coinbase account, convert some USDC there into ETH (incurring a $1.49 fee for that), and then send some ETH to my Wallet, incurring yet another a transfer fee there. Then I could use that ETH in my wallet to pay for the transfer of the USDC to my Coinbase exchange. Then at long last I was able to convert my USDC to cash and transfer it to my bank account, to finally put this whole BlockFi drama to rest.
Looking on the bright side of all this uproar, I now have a functioning cryptocurrency exchange account and wallet, and am familiar with elementary crypto operations. This might prove handy if I ever want to dabble more in this area or if some other need arises. For now, however, I have had enough of crypto.
ADDENDUM: Finally got all my BlockFi funds back as of November, 2024. BlockFi was able to claw back its assets from FTX, and fully reimburse its customers. Yay! This post describes the process:






{kind=link}