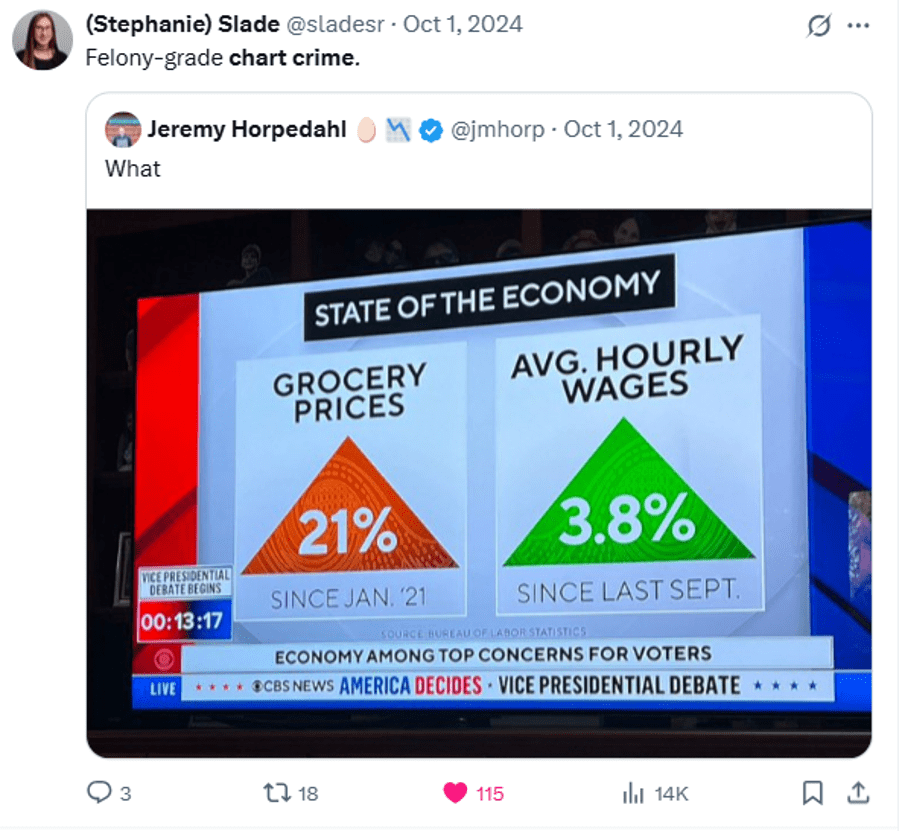
Many people take a basic statistics course in college. Those course usually include an overview of standard graphs and best practices for visualizing data.
To keep that section from getting boring (“here’s a line graph… here’s a bar chart…”) you can borrow my slides on #chartcrimes Teaching people best practices is more engaging when you can show real examples of charts gone wrong.
These are pictures I dropped directly into slides and talked through:
P.S. Joke I made about this section of my textbook:
My textbook includes a slide specifically telling people not to use techniques thought to be cutting edge in 1998. "Perplexing depth" and "distracting art" 💀 pic.twitter.com/Pk5baBZvK1
I suppose I’m sold on their claim that most kids can learn basic facts and some academic skills from an iPad app. Listen all the way through if you are going to listen at all, because even some cracks in the tech product are revealed after the big pitch in the beginning.
I have been using Duolingo to review my high school French and Spanish. I think the few minutes a day I spend have helped drag some vocabulary back out of long-term storage. Although, as I recently heard a comedian say, “All my friends who have Duolingo are still speaking English to me.”
Folks should consider whether AI learning apps is just MOOCs again. Essentially, they need to get kids to watch (short, this time) videos of lecture content. MOOCs were longer lecture content videos. Maybe shorter is the key, combined with personalized feedback. Maybe not, for getting cheap effective comprehensive education that scales.
About half an hour in, Liemandt asserts that anyone in America would agree that kids learn life skills through “sports” not school. That’s an oversimplification, but I agree that sports ranks higher than “math class” for developing leadership ability.
Since they at Alpha School believe that have solved quickly learning facts, it’s interesting to hear how they do the rest of “education.” The school must fill enough time that the parents don’t have to see their kids half the day and also teach leadership/ communication/character. Alpha school is expensive ($40,000 a year) and there are many paid adults involved who are called “guides and coaches.”
My students at Samford are especially good at taking on leadership roles and creating a thriving community. Residential college provides a good testing ground for leadership and there are real “market tests” of success for things like sorority events, as the Alpha school encourages for older kids.
I applaud people trying to innovate. I think we’ll see more educational apps in schools, and that will be great. I’m not trying to dump on Alpha School. I just think the underperformance arc of MOOCs should temper our enthusiasm.
Sometimes I get weeks in the summer that are more research focused. This past week is very much a teaching and service focused week at my university. I haven’t had any time to ponder topics related to research or current events. So, I will share what I’ve been telling my fellow college educators. This will sound backward to some and like common sense to others. Feel free to comment with your thoughts.
College professors who teach 200-level or “principles” classes should not change all that much in response to AI. Students still need to know something. There need to be a few concepts and vocabulary words in their heads. For example, a person cannot use a calculator effectively if they do not know what a square root is at all.
I see highly trained mid-career professionals bragging about how they get ChatGPT to do their work. Can a 20-year-old do that if they don’t know what words to use in a prompt? How does vibe coding go for people who never learned to write out a single line of code? (not a question I have an expert answer to right now)
We should largely be sticking to the “old ways” and at least to some extent still require memorization. Having an exam on paper is a good way to ensure that the students can form coherent thoughts of their own, when possible.
Indeed, students might become AI jockeys when they get to the workplace. A 400-level class would be a good place for them to start heavily integrating AI tools to accomplish tasks and do projects. For anyone unfamiliar with American college categories, that would mean that an undergraduate might heavily use AI tools in their 4th and final year of study.
AI makes a great tutor for learning and enforcing principles, but it should not serve as a replacement test-taker. A human who cannot read and write will not be able to take full advantage of an intelligent machine in the next decade. Voice recognition is getting very good and the models are getting more agentic, so this might all change if we can keep the data centers on long enough. In the future, you might argue that having students write an exam answer by hand is as superfluous as teaching them to play the violin.
As of 2025, what you might see is some teachers who feel pressured to claim they are integrating AI more than they actually want to. A relative I talked to his summer in a corporate job told me that she feels intense pressure at work to be able to claim that she’s using AI. Anyone doesn’t have the appearance of embracing AI looks behind or expendable!
As marriage rates decline nationally, Esther Perel’s “Where Should We Begin?” offers more than dating advice. These episodes are recordings of real couples or single people today who explain why they are struggling to find relationship success. It provides an anthropological study of why coupling is challenging in the 21st century.
Each couple’s struggle with intimacy and commitment reflects broader questions about what it means to build a life together in an age of individualism. “Where Should We Begin?” doesn’t offer easy solutions to the coupling crisis, but it does helps us understand the deeper currents shaping modern love. Especially now that she has branched out to non-romantic friendship topics this year, almost anyone can find an episode here that might help them navigate one of their own personal problems as if they had the world’s leading relationship therapist on hand.
One of Perel’s points is that modern couples are drowning under expectations that previous generations never faced. Partners are expected to be best friends, passionate lovers, co-parents, financial partners, emotional support systems, and personal growth catalysts all at once. Perel points out that they’re asking their relationship to fulfill needs that used to be met by entire communities.
One episode I listened to is “I Can’t Love You the Way You Want Me To” Description: Their relationship is on the edge. They’re grappling with communication issues and the emotional scars from their past. And they’re trapped. Trapped in an endless cycle of blame, defensiveness, and attack.
As someone who grew up on the periphery of Philadelphia, I was interested in their specific fight. The man said that Philly sports fans are trash. The woman defended the honor of Philly with specific examples, and now they hate each other. Honestly sounds like my high school.
These are notable posts from 2025, roughly presented in descending order, starting with the post that got the most views.
Is there a competitive threat to the NBA? Mike Makowsky wrote, “… let’s put it this way. Why *wouldn’t* the Saudi Arabian PIF invest $5 billion in creating a rival basketball league?”
2. Perspective: This Stock Correction Fear, Too, Will Pass In March, Scott Buchanan presented “an optimistic take on the current stock market pullback.” Indeed, the market came back, despite the tariff doomerism of 2025 Spring.
7. Was the US at Our Richest in the 1890s? If you don’t believe Jeremy, consider one of the American Girl Doll historical books I was just reading to my kid. In our book, a little girl sends a letter to Samantha (the 1904 doll) reporting that bothof her parents just died from the flu.
8. The Wild Market of July 8th, 2025 James Bailey on the topic that we are all trying to keep up with this year: “Yesterday the S&P 500 shot up 9% on the news that most of Trump’s new tariffs were paused.”
9. No Tech Workers or No Tech Jobs? I (Joy) wish I had more time to write about the market for tech jobs this year. There is some indication that hiring is slowing. Some people still call it a correction from the Covid tech over-hiring spree. Other people take this as a sign that AI reduces the need for human programmers and otherwise “high-skill” humans, while some refute that claim.
10. Other “I, Pencils” It was fun for several dozen of us economists when everyone else in the world suddenly re-discovered the value of international exchange.
11. The Best Investments of the 1970s James considers “what were the best investments of the 1970’s?” Interesting to consider the performance of gold in retrospect considering stagflation.
15. Salty SALT in the OBBB Zachary explains. “Economically, the SALT makes it cheaper for individuals to live in high-tax jurisdictions. That’s distortionary.”
Reflections: We’ve been doing this for 5 years now, as of August 2025. From the analytics I can see, our posts have been the answer to a stranger’s Google query hundreds of thousands of times. Having been the beneficiary of so many other posts from strangers online, I’m happy about that.
Reminder: You can subscribe to our WordPress site to get posts sent to your email. The widget for putting your email in should be on the right side of your screen on a computer, or you can find it by scrolling to the bottom of the home page on a mobile device. WordPress will let you customize your preferences so that you get emails batched once a week if you prefer that to Every Day.
Based on my crude analytics from WordPress, “traffic” to our site from LLMs is low but increasing. It appears that readers occasionally click over from chatgpt.com or perplexity.ai What we can’t see is if and when our writing is re-molded as part of an LLM answer without attribution. In one sense, writing online is more important than ever, to feed the beast and help get good quality answers to LLM users. On the other hand, old systems in place like upvotes and view counts that used to motivate people to write for free might crumble in the new world.
From me in 2024: “AI companies have money. Could we be headed toward a world where OpenAI has some paid writers on staff? Replenishing the commons is relatively cheap if done strategically, in relation to the money being raised for AI companies.”
If anyone knows Mark Zuckerberg, please tell him that I’ll write for a fraction of what he’s paying these new engineers. What if he gave out a writing fellowship on the understanding the person never publishes (else the other bots would scrape it) and just exclusively lets Llama train off of original work?
In our case, anyway, we enjoy writing and learn from the process, so we are looking forward to being here every day.
I posted See New York City for Free in 2022 and See New York City for Cheap in 2024. In summer 2025, we spent 4 nights in Midtown. I will post general reflections about kids and New York here. Last week, l posted a short itinerary for our half-week in Manhattan with elementary-aged kids, as suggestions for other parents: NYC Family Summer Trip Itinerary
1. Assuming a middle-income family with 1-3 kids, when it comes to travel, I propose Do Less for Preschool. Save money by staying close to home when the kids are under the age of 6. I know people who do international trips with babies, usually because they are visiting family. I have not.
2. A mentor encouraged me to have kids early. One of my objections in 2014 was that I hadn’t traveled the world yet. Everyone I knew was posting selfies in Thailand. How could I have kids if I haven’t even posted from Thailand yet? He told me that you can travel with your kids when they are older. Now it’s 2025. Did that time go by fast? It’s a blur at this point. I remember the time when I read in a book that your kids will potty train themselves if you let them walk around with no diaper. When I tried that, my folks just went on the floor. That’s the stage of life when you might want to put unnecessary travel on hold.
3. Someone had told us that the NYC Subway is not safe and we should not take our kids on it. We used the Subway every day and it was fine. I saw one young man jump the turnstile. The elevator smelled bad. One night when I was checking routes, I noticed a warning on the map reading, “trains are delayed while we request NYPD for someone being disruptive on train…” So, people who rely on the Subway at all times might still have some complaints.
We enjoyed peace and safety in touristy areas between the hours of 8am and 9pm. Were we the beneficiaries of the crime decrease? I saw a bus ad celebrating the decrease in murders in NYC. Before I left Birmingham, Mayor Woodfin announce a big decrease in murders. The trend seems to be real.
Last year was the largest one-year percentage point decline in murder ever recorded. This year is on track to do so again. In fact, nearly every category of crime is down sharply, with many at multi-decade lows or even the lowest per-capita rates ever recorded. pic.twitter.com/5ZLsNVwyhO
4. The Observation Deck of the Empire State Building trip is almost more meta than the MOMA. You are inside the building looking at pictures of the outside of the building. You are posting pictures of yourself next to 50-year-old pictures of the outside of the building. People appear to go to the real thing in order to poast.
You can just do things, as they say, or at least you could in 1930.
Both kids voted that the Empire State Building was more “wow” than the MOMA. Maybe they like constructing more than deconstructing.
5. I vote the Museum of Modern Art (MOMA) as more “wow” because the permanent installations include many famous pieces including Starry Night by Van Gogh.
I had booked a day at MOMA without knowing exactly what was inside. My kids got to see me going around saying things like, “Wow. They have a real Picasso!” Instead of acting as a docent through a world I’ve already explored, my kids get to discover a lot along with me. We discussed what counts as “art” and “how did that get on the wall of a museum?”
6. If you are going to Lower Manhattan to see the New York Stock Exchange and the World Trade Center, don’t miss a free tour of Trinity Church. (Hamilton’s tomb is in the churchyard.) It is an example of progress to see the cathedral dwarfed by the surrounding skyscrapers considering that: “With its 281-foot steeple, the third Trinity Church became the tallest building in the United States.”
Here at EWED, Jeremy has often pointed out that people are richer today than in the past. The maligned Boomers would have seen a shorter New York skyline as children. Many of the supertall glass structures you see today were built after 2001, meaning it’s Gen Z who gets to live with them. (I learned that on our harbor boat tour.)
7. The 7-year-old got Lion King and the M&M store in Times Square. The tour of the United Nations headquarters was for the older people. The 10yo and I learned a lot from an excellent tour guide.
The 7yo had to be carried. She did not understand why they were calling “an emergency meeting on Syria.” The next day I asked her what she remembered from touring the UN. She sincerely replied, “What United Nations?” If you are wondering if she remembers anything from the trip, the answer is yes. The Empire State Building and the Chrysler building, among many other things, are newly part of the family vocabulary.
After the UN tour, I took the family back across 1st Avenue to see the Isaiah Wall. Scaffolding blocked our view, which is not encouraging for the hope of peace. The idea is that: “They shall beat their swords into plowshares, and their spears into pruning hooks; nation shall not lift up sword against nation, neither shall they learn war any more.”
Imagine a child named Johnny trying to form a model of the universe from the journey I set up for my kids this summer. In New York, Johnny embarked on a cultural safari that began at the MoMA, where he stood wide-eyed before melted clocks and soup cans, absorbing the idea that the world might be an absurd, fragmented collage. Then came The Lion King as a dazzling counterpoint, suggesting that the world is imbued with cosmic purpose. Every giraffe, ghost-dad, and blade of savannah grass existed in service of a divine, eternal monarchy. Finally, at the United Nations, he was led past flags and translation booths, where no one bowed to anyone and the world’s contradictions were negotiated over coffee. By the end of the day, Johnny wondered: is meaning a myth, a fact taught by the Spirit, or a matter of committee?
I noticed that they serve Starbucks coffee in the basement of the UN and in the Empire State Building. As long as we can get coffee before and dinner after, no one seems to care if the message is coherent.
This is a condensed list of what we did with elementary-aged kids for three fun days in Manhattan in July.
Like a camping trip, NYC with kids depends on the weather. In good walking weather you can occupy many hours exploring free outdoor attractions. In bad weather, you might feel the need to constantly buy admission tickets, retail, taxis and sit-down restaurant meals.
Our hotel was a 5-minute walk from Grand Central Station. We had a good view from our room on the 28th floor. We could even look down on an interesting active construction site. When traveling with kids, or any group larger than a couple, you’ll probably be stuck in the hotel sometimes, so paying extra for a good view might be worth it.
In the hotel lounge, adults could drink a free glass of wine and listen to a guy playing calm piano songs from memory like “My Heart Will Go On.” When my ten-year-old (10yo) asked for “Seven Nation Army” by The White Stripes, the request was denied.
Tuesday
We walked to The Empire State Building. Passing the Public Library was a highlight although it was not open yet. I had booked entry tickets to the Empire State building online months ahead of time for a 9:30am time on a Tuesday. We spent no time waiting in line.
Next, we took the Subway to the Museum of Modern Art (MOMA). I had reserved tickets for the day. If your kids need a break from quietly appreciating art on the wall, there is a garden courtyard and kid’s craft area.
It was hot but we were lucky to not be in the middle of a genuine heat wave. We got to-go food from a shop and walked north to Central Park for a picnic on rocks in the shade. Playgrounds and fun statues provide points of interest for kids.
We walked up to the Chess pavilion where my kids dropped in on chess games with friendly strangers (a nice man provided the pieces). You could bring your own chess or checkers pieces if you want to guarantee a game.
Note: Even though many places claim to have bag polices online, you can almost always get a regular sized backpack and/or metal water bottle through security.
Wednesday
This might sound like a planned itinerary, but the only thing we locked in ahead of time for Wednesday was an afternoon Broadway show. By the time we got back to our hotel at night, my phone had counted over 14,000 steps for the day. Our first stop was Clinton Castle on the southern edge of the island. Benefits to children include bathrooms and a museum display of how Manhattan was expanded through land reclamation. I’m not including all the places we stopped to eat in this blog but we especially liked discovering Liberty Bagels.
We saw the bull statue and the New York Stock Exchange (from the outside). A great stop in Lower Manhattan is a free self-guided tour of Trinity Church. We walked to the 9/11 memorial and then back to the subway so we could rest in our hotel during the hottest part of the day.
Lion King on Broadway was fun (and expensive). Afterwards, we were in Time Square, and it was finally time to do what my kids had been talking about all year: return to the M&M store. Kids love the M&M store.
Then we walked to Hell’s Kitchen for dinner. We went back east to Rockefeller Center and bought books for the kids at McNally Jackson. From there, with a “we can make it” attitude, we walked back to the hotel in the dark. This is where the “safe streets” matter as much as the weather.
Thursday
This morning had not been planned ahead of time, so we spent some of our time figuring things out. We walked to the United Nations headquarters. I was able to get visitor passes and a guided tour. We had a great guide who explained the building and the aims of the UN for 45 minutes. I learned a lot and my 10yo was engaged.
Should you take your children on a tour of the UN? I had to carry my 7yo most of the time. The next day, I asked her what she remembered. She sincerely replied, “What United Nations?” If you don’t think your younger child will be outright disruptive, then you might take a younger kid along with an older kid who can appreciate it.
We had an appointment to enter the USS Intrepid Museum at 2:30. We didn’t make it until 3:30 and it closes at 5pm. The place deserves more than 90 minutes. It has a big kids’ activity area that is fully indoors.
Our last scheduled event was a Circle Line Harbor Lights Cruise from 7pm to 9pm. In the summer, this is a sunset cruise of lower Manhattan and the Statue of Liberty. Just at the end you see the city lights against the night sky. The tour guide was entertaining and smart! I learned interesting NYC facts and history. They have enclosed areas with windows for bad weather but that would not be as fun. Being able to sit up on the open-air top deck made the view amazing for everyone.
Tyler suggested that a “smarter” LLM could not master the unconquered intellectual territory of integrating general relatively and quantum mechanics.
Forget passing Ph.D. level qualifying exams. (j/k James) Are the AI’s going to significantly surpass human efforts in generating new knowledge?
What exactly is the barrier to solving the fundamental mysteries of physics? How do we experimentally confirm that all matter breaks down to vibrating strings?
In a podcast episode of Within Reason, Brian Greene says that we can imagine an experiment that would test the proposed unifying String Theory. The Large Hadron Collider is not big enough (17 miles in circumference is too small). We would need a particle accelerator as big as a galaxy.
ChatGPT isn’t going to get us there. However, Brian Greene did suggest that there is a possibility that an advance in mathematics could get us closer to being able to work with the data we have.
Beh Yeoh summarized what he heard from Tyler et al. at a live event on how fast the acceleration in our knowledge will get boosted from AI. They warned that some areas will hit bottlenecks and therefore not advance very fast. Anything that require clinical trials, for example, isn’t going to proceed at breakneck speed. Ben warns that “Protein folding was a rare success” so we shouldn’t get too too excited about acceleration in biotech. If advances in physics require bigger and better physical tools to do more advanced experimental observations, then new AI might not get us far.
However, one of the categories that made Yeoh’s list of where new AI might accelerate progress is “mathematics,” because developing new theories does not face the same kind of physical constraints.
So, we are unlikely to obtain new definitive tests of String Theory to the extent that it is a capital-intensive field. The scenario for AI advances to bring a solution to this empirical question in my lifetime is probably if the solution comes from advances in mathematics so that we can reduce our reliance on new observational data.
Related links: my article for the Gospel Coalition – We are not “building God,” despite some claims. my article for EconLog – AI will be constrained by the same problem that David Hume faced. AI can predict what is likely to occur in the future based on what it has observed in the past.
“The big upward trend in Generative AI/LLM tool use in 2025 continues but may be slowing.” Have we reached a plataue, at least temporarily? Have we experienced the big upswing already in productivity, and it’s going to level out now? At least programming will be less painful forever after?
“LLM Hallucination of Citations in Economics Persists with Web-Enabled Models” I realize that, as of today, you can pay for yet-better models than what we tested. But if web-enabled 4o can’t cite Krugman properly, you do wonder if “6o” will be integrating general relatively and quantum mechanics. A slightly longer context window probably isn’t going to do it.
Unexpectedly, Chesterton on Patriotism from 2021 is one of my all-time top performing posts due to a slow but steady drip of Google Search hits.
In 1908, G.K. Chesterton published the following line in Orthodoxy,
This, as a fact, is how cities did grow great. Go back to the darkest roots of civilization and you will find them knotted round some sacred stone or encircling some sacred well.
By 1908, Chesterton had likely been exposed to Victorian early anthropological thinkers like Tylor and Frazer. Maybe I shouldn’t be impressed that he’d get it right, but I don’t think of Chesterton as having access to the best and latest evidence for how human civilization evolved.
I was browsing the book Sapiens (2011) this week and came across:
In the conventional picture, pioneers first built a village, and when it prospered, they set up a temple in the middle. But Göbekli Tepe suggests that the temple may have been built first, and that a village later grew up around it. (pg 102)
Today’s post is dedicated to congratulating Chesterton on making a conjecture that turns out to line up with the best we now know and archeological evidence that was only discovered in 1995.
Chesterton wrote,
The only way out of it seems to be for somebody to love Pimlico; to love it with a transcendental tie and without any earthly reason. If there arose a man who loved Pimlico, then Pimlico would rise into ivory towers and golden pinnacles… If men loved Pimlico as mothers love children, arbitrarily, because it is theirs, Pimlico in a year or two might be fairer than Florence.
Also this month I witnessed Americans celebrating the 4th of July. People here love this country “because it is theirs.”
I’ve heard a lot of panicking in the past 10 years about the fate of the nation, and I think we should always be in a partial state of paranoia. But, if love of country is needed in the recipe, we’ve still got it. (you might need an Instagram account to view Mark Zuckerberg Zuck wakeboarding in a bald eagle suit)
that paper only tested 4o (which arguably is a bad enough model that i almost never use it). I also don't know how they used web-search, because it's not native iirc and you have to implement it yourself which means that your implementation could be bad
Since the scope and frequency of hallucinations came as a surprise to many LLM users, they have often been used as a ‘gotcha’ to criticize AI optimists. People, myself included, have sounded the alarm that hallucinations could infiltrate articles, emails, and medical diagnoses.
The feedback I got from power users on Twitter this week made me think that there might be a cultural shift in the medium term. (Yes, we are always looking for someone to blame.) Hallucinations will be considered the fault of the human user who should have:
Used a better model (learn your tools)
Written a better prompt (learn how to use your tools)
Assigned the wrong task to LLMs (it’s been known for over 2 years that general LLM models hallucinate citations). What did you expect from “generative” AI? LLMs are telling you what literature ought to exist as opposed to what does exist.