Tennis elbow (or these days, pickleball elbow) is a painful, debilitating condition that affects around 2% of adults at any given time. Active tennis players have about a 50% chance of being stricken at some point. If you give it a chance to heal, it usually goes away within a year, but that is a long time to be in pain or disabled.
The traditional technical name for this condition is “lateral epicondylitis.” That suffix “…itis” implies inflammation, but it is now known that typical inflammation markers are generally absent. So, the new jargon is the deliberately ambiguous “tendinosis” or even “tendinopathy.” It seems to be caused by accumulated damage to the very end of the tendon that anchors the muscles which are attached to the back of your hand. Those muscles that let you tilt your hand up; if you grip something hard and try to hold something steady, those muscles contract in a big way. The micro tears seem to occur right about where that tendon attaches to a little knob of bone at the very outside of your elbow joint:
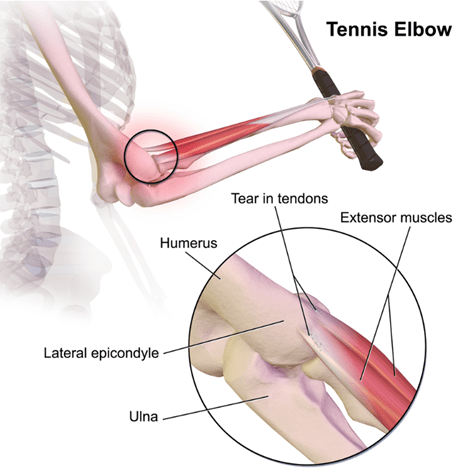
This condition is somewhat frustrating for doctors and for patients, since there’s not a single clear effective treatment. Although injecting Cortisone type anti-inflammatories gives short-term pain relief, it seems to adversely affect longer term outcomes, so those shots are less common than 20 years ago. Therapists throw all sorts of techniques at it, including NSAIDs, heat, cold, exercises, braces, shock waves, acupuncture, injections of blood extracts, and so on. All these may help, though for every study that shows positive results for a given treatment there seems to be one that doesn’t.
I have a personal interest in this subject, since I have a long-standing for propensity towards tennis elbow. I had to stop playing tennis many years ago because of it. More recently, I spent the day helping on a work project, installing sheet rock to repair flood damage in a someone’s home. After a day gripping a powered drill driver, the old tennis elbow flared up significantly.
In the course of my internet search, I ran across a very promising study that seems to have been largely neglected. It is also a sweet piece of science.
An orthopedist named Jerrold Gorski started reflecting on the common observation that tennis elbow often feels worst upon waking up in the morning. That made him wonder whether something was going on in the night that caused the condition to worsen. Which led him to hypothesize that tennis elbow might be helped by changing a patient’s sleep posture. Prior studies showed that people spend some 55% of the night sleeping with their arm crooked up overhead, something like this:

That position could keep stress on the tendon all night, and inhibit it from healing. Dr. Gorski also noted that in the literature there are other examples of sleep posture or waking postures making a difference in treating various orthopedic conditions.
And so, like a good scientist, he devised an experiment to test his hypothesis. He came up with a very simple technique of using a bathrobe belt, which is soft and wide, to restrain the arm during sleep. You simply tie a large loop at one end that goes around the thigh, and a smaller loop at the other that fits snuggly around the wrist. If all goes well, this rigging well prevent will keep the arm down close to the side all night, so it cannot get crunched under the head:
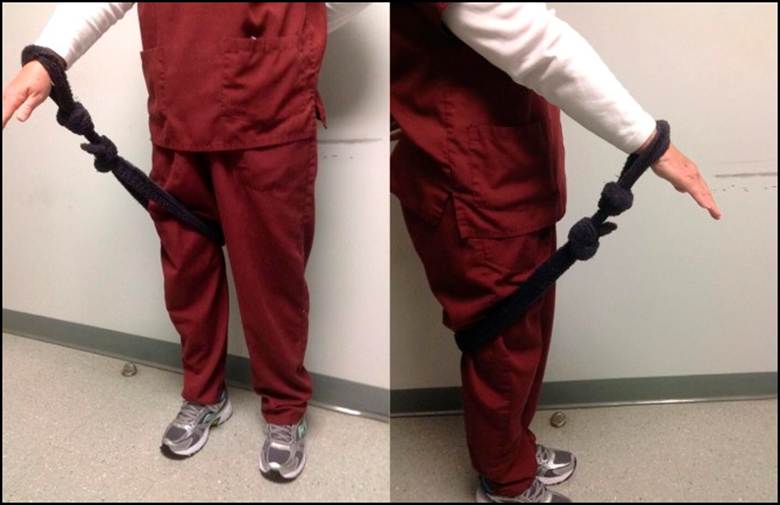
Dr. Gorski tried tried this out with 39 tennis elbow patients. Six of them apparently could not tolerate being roped for the night, so they were designated as “treatment failures”, or effectively a control group. The other 33 patients stuck with the protocol, although most of them, like the 6 “treatment failures”, complained about interference with going to sleep or staying asleep.
There was a fairly dramatic difference in outcomes. The six treatment failures had ongoing tennis elbow symptoms that persisted unchanged over the initial 3-month study period. Of the thirty-three patients who stuck with the protocol, 66% reported improvement within 1 month, and 100% of them improved within 3 months. Those are really good results.
Obviously, it’s not a perfect study. It only claims to be a prospective study. Nevertheless, the results were so promising, and the treatment was so inexpensive and harmless and noninvasive, I would’ve thought that it would get a lot of attention. But looking in Google Scholar for citations, I only saw seven articles that cited it. Two of those articles were letters to the editor by the author, Dr. Gorksi himself, seemingly trying to draw due attention to his promising study, and one citation was in an article that got retracted. This leaves only 4 independent citations in the medical literature all of which, as best I could tell, were about touting some other treatment, and just nodded in passing to Dr. Gorski’s work. So, essentially crickets. One can only speculate on why the medical profession has not paid more attention to a treatment which requires nothing more than an office visit and demo with a strip of cloth.
I want to give a shout-out to the UK-based “Sports Injury Physio” website, which, in a very helpful and comprehensive article on tennis elbow care, noted:
Sleeping with your elbow straight is usually a gamechanger. There is something about keeping the elbow bent for long periods that irritates tennis elbow and makes the pain worse. It can be a bit challenging to figure out how to keep your elbow straight while tossing and turning in bed, but my patients who manage this report big improvements in their pain.
That endorsement piqued my interest. The Wikipedia article on tennis elbow also mentions this treatment clearly. With my nascent tennis elbow, I decided to try it for myself. Using a bowline knot (which does not slip), I tied a loop at one end of a bathrobe belt just big enough to wriggle my hand through, and a larger loop at the bottom to go around my thigh:

It is somewhat awkward to sleep with this on, but it is entirely bearable if you set your mind to it and plan ahead, e.g., where to position your nighttime tissue box. After only two nights on this protocol, I am now waking up with no pain in my elbow. Thanks, doc.














































{kind=link}