2023 continues to be a dangerous year for eminent economists. We have once again lost a Nobel laureate who was influential even by the standard of Nobelists, Robert Solow:
I’m sure you will soon see many tributes that discuss his namesake Solow Model (MR already has one), or discuss him as a person. I never got to meet him (just saw him give a talk) and the Solow Model is well known, so I thought I’d take this occasion to discuss one of his lesser-known papers- “Sustainability: An Economists Perspective“. What follows comes from my 2009 reaction to his paper:
We study whether people will pay for a fact-check on AI writing. ChatGPT can be very useful, but human readers should not trust every fact that it reports. Yesterday’s post was about ChatGPT writing false things that look real.
The reason participants in our experiment might pay for a fact-check is that they earn bonus payments based on whether they correctly identify errors in a paragraph. If participants believe that the paragraph does not contain any errors, they should not pay for a fact-check. However, if they have doubts, it is rational to pay for a fact-check and earn a smaller bonus, for certain.
Abstract: We explore whether people trust the accuracy of statements produced by large language models (LLMs) versus those written by humans. While LLMs have showcased impressive capabilities in generating text, concerns have been raised regarding the potential for misinformation, bias, or false responses. In this experiment, participants rate the accuracy of statements under different information conditions. Participants who are not explicitly informed of authorship tend to trust statements they believe are human-written more than those attributed to ChatGPT. However, when informed about authorship, participants show equal skepticism towards both human and AI writers. There is an increase in the rate of costly fact-checking by participants who are explicitly informed. These outcomes suggest that trust in AI-generated content is context-dependent.
Our original hypothesis was that people would be more trusting of human writers. That turned out to be only partially true. Participants who are not explicitly informed of authorship tend to trust statements they believe are human-written more than those attributed to ChatGPT.
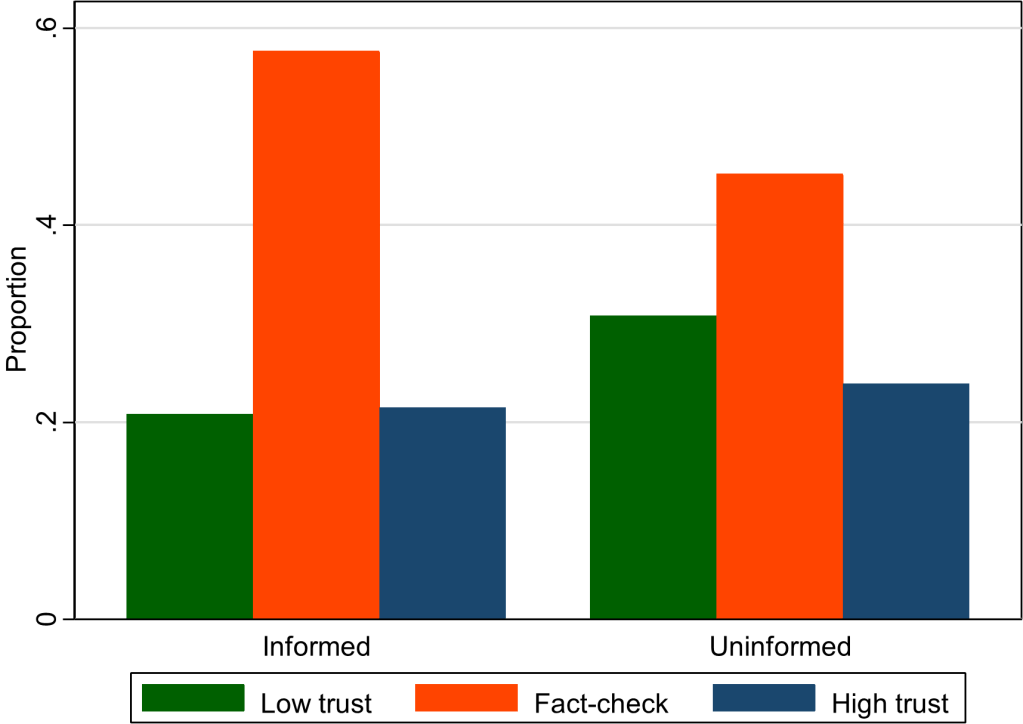
We presented information to participants in different ways. Sometimes we explicitly told them about authorship (informed treatment) and sometimes we asked them to guess about authorship (uninformed treatment).
This graph (figure 5 in our paper) shows that the overall rate of fact-checking increased when subjects were given more explicit information. Something about being told that a paragraph was written by a human might have aroused suspicion in our participants. (The kids today would say it is “sus.”) They became less confident in their own ability to rate accuracy and therefore more willing to pay for a fact-check. This effect is independent of whether participants trust humans more than AI.
We are thinking of fact-checking as often a good thing, in the context of our previous work on ChatGPT hallucinations. So, one policy implication is that certain types of labels can cause readers to think critically. For example, Twitter labels automated accounts so that readers know when content has been chosen or created by a bot.
Suggested Citation: Buchanan, Joy and Hickman, William, Do People Trust Humans More Than ChatGPT? (November 16, 2023). GMU Working Paper in Economics No. 23-38, Available at SSRN: https://ssrn.com/abstract=4635674
Citation: Buchanan, J., Hill, S., & Shapoval, O. (2024). ChatGPT Hallucinates Non-existent Citations: Evidence from Economics. The American Economist. 69(1), 80-87 https://doi.org/10.1177/05694345231218454
Blog followers will know that we reported this issue earlier with the free version of ChatGPT using GPT-3.5 (covered in the WSJ). We have updated this new article by running the same prompts through the paid version using GPT-4. Did the problems go away with the more powerful LLM?
The error rate went down slightly, but our two main results held up. It’s important that any fake citations at all are being presented as real. The proportion of nonexistent citations was over 30% with GPT-3.5, and it is over 20% with our trial of GPT-4 several months later. See figure 2 from our paper below for the average accuracy rates. The proportion of real citations is always under 90%. GPT-4, when asked about a very specific narrow topic, hallucinates almost half of the citations (57% are real for level 3, as shown in the graph).
The second result from our study is that the error rate of the LLM increases significantly when the prompt is more specific. If you ask GPT-4 about a niche topic for which there is less training data, then a higher proportion of the citations it produces are false. (This has been replicated in different domains, such as knowledge of geography.)
What does Joy Buchanan really think?: I expect that this problem with the fake citations will be solved quickly. It’s very brazen. When people understand this problem, they are shocked. Just… fake citations? Like… it printed out reference for papers that do not actually exist? Yes, it really did that. We were the only ones who quantified and reported it, but the phenomenon was noticed by millions of researchers around the world who experimented with ChatGPT in 2023. These errors are so easy to catch that I expect ChatGPT will clean up its own mess on this particular issue quickly. However, that does not mean that the more general issue of hallucinations is going away.
Not only can ChatGPT make mistakes, as any human worker can mess up, but it can make a different kind of mistake without meaning to. Hallucinations are not intentional lies (which is not to say that an LLM cannot lie). This paper will serve as bright clear evidence that GPT can hallucinate in ways that detract from the quality of the output or even pose safety concerns in some use cases. This generalizes far beyond academic citations. The error rate might decrease to the point where hallucinations are less of a problem than the errors that humans are prone to make; however, the errors made by LLMs will always be of a different quality than the errors made by a human. A human research assistant would not cite nonexistent citations. LLM doctors are going to make a type of mistake that would not be made by human doctors. We should be on the lookout for those mistakes.
ChatGPT is great for some of the inputs to research, but it is not as helpful for original scientific writing. As prolific writer Noah Smith says, “I still can’t use ChatGPT for writing, even with GPT-4, because the risk of inserting even a small number of fake facts… “
I still can't use ChatGPT for writing, even with GPT-4, because the risk of inserting even a small number of fake facts or bad interpretations into a blog post is unacceptable, meaning that it requires so much time to fact-check that it doesn't save effort.
Some economists love to write about sports because they love sports. Others love to write about sports because the data are so good compared to most other facets of the economy. What other industry constantly releases film of workers doing their jobs, and compiles and shares exhaustive statistics about worker performance?
To take an extreme example, suppose an average high-school athlete got thrown into a professional football or basketball game; a fan asked to evaluate them could probably figure out that they don’t belong there within minutes, or perhaps even just by glancing at them and seeing they are severely undersized. But what if an average high school coach were called up to coach at the professional level? How long would it take for a casual observer to realize they don’t belong? You might be able to observe them mismanaging games within a few weeks, but people criticize professional coaches for this all the time too; I think you couldn’t be sure until you see their record after a season or two. Even then it is much less certain than for a player- was their bad record due to their coaching, or were they just handed a bad roster to work with?
The sports economics literature seems to confirm my intuition that coaches are difficult to evaluate. This is especially true in football, where teams generally play fewer than 20 games in a season; a general rule of thumb in statistics is that you need at least 20 to 25 observations for statistical tests to start to work. This accords with general practice in the NFL, where it is considered poor form to fire a coach without giving him at least one full season. One recent article evaluating NFL coaches only tries to evaluate those with at least 3 seasons. If the article is to be believed, it wasn’t until 2020 that anyone published a statistical evaluation of NFL defensive coordinators, despite this being considered a vital position that is often paid over a million dollars a year:
This week the Nobel Foundation recognized Claudia Goldin “for having advanced our understanding of women’s labour market outcomes”. If you follow our blog you probably already know that each year Marginal Revolution quickly puts up a great explanation of the work that won the economics Prize. This year they kept things brief with a sort of victory lap pointing to their previous posts on Goldin and the videos and podcast they had recorded with her, along with a pointer to her latest paper. You might also remember our own review of her latest book, Career and Family.
But you may not know that Kevin Bryan at A Fine Theorem does a more thorough, and typically more theory-based explanation of the Nobel work most years; here is his main take from this year’s post on Goldin:
Goldin’s work helps us understand whose wages will rise, will fall, will equalize going forward. Not entirely unfairly, she will be described in much of today’s coverage as an economist who studies the gender gap. This description misses two critical pieces. The question of female wages is a direct implication of her earlier work on the return to different skills as the structure of the economy changes, and that structure is the subject of her earliest work on the development of the American economy. Further, her diagnosis of the gender gap is much more optimistic, and more subtle, than the majority of popular discourse on the topic.
He described my favorite Goldin paper, which calculates gender wage gaps by industry and shows that pharmacists moved from having one of the highest gaps to one of the lowest as one key feature of the job changed:
Alongside Larry Katz, Goldin gives the canonical example of the pharmacist, whose gender gap is smaller than almost every other high-wage profession. Why? Wages are largely “linear in hours”. Today, though not historically, pharmacists generally work in teams at offices where they can substitute for each other. No one is always “on call”. Hence a pharmacist who wants to work late nights while young, then shorter hours with a young kid at home, then a longer worker day when older can do so. If pharmacies were structured as independent contractors working for themselves, as they were historically, the marginal productivity of a worker who wanted this type of flexibility would be lower. The structure of the profession affects marginal productivity, hence wages and the gender gap, particularly given the different demand for steady and shorter hours among women. Now, not all jobs can be turned from ones with convex wages for long and unsteady hours to ones with linear wages, but as Goldin points out, it’s not at all obvious that academia or law or other high-wage professions can’t make this shift. Where these changes can be made, we all benefit from high-skilled women remaining in high-productivity jobs: Goldin calls this “the last chapter” of gender convergence.
There is much more to the post, particularly on economic history; it concludes:
When evaluating her work, I can think of no stronger commendation than that I have no idea what Goldin will show me when I begin reading a paper; rather, she is always thoughtful, follows the data, rectifies what she finds with theory, and feels no compunction about sacrificing some golden goose – again, the legacy of 1970s Chicago rears its head. Especially on a topic as politically loaded as gender, this intellectual honesty is the source of her influence and a delight to the reader trying to understand such an important topic.
This year also saw a great summary from Alice Evans, who to my eyes (admittedly as someone who doesn’t work in the subfield) seems like the next Claudia Goldin, the one taking her work worldwide:
Claudia Goldin has now done it all. With empirical rigor, she has theorised every major change in American women’s lives over the twentieth century. These dynamics are not necessarily true worldwide, but Goldin has provided the foundations.
I’ve seen two lines of criticism for this prize. One is the usual critique, generally from the left, that the Econ Nobel shouldn’t exist (or doesn’t exist), to which I say:
The critique from the right is that Goldin studied unimportant subjects and only got the prize because they were politically fashionable. But labor markets make up most of GDP, and women now make up almost half the labor force; this seems obviously important to me. Goldin has clearly been the dominant researcher on the topic, being recognized as a citation laureate in 2020 (i.e. someone likely to win a Nobel because of their citations). At most politics could explain why this was a solo prize (the first in Econ since Thaler in 2017), but even here this seems about as reasonable as the last few solo prizes. David Henderson writes a longer argument in the Wall Street Journal for why Claudia Goldin Deserves that Nobel Prize.
Best of all, Goldin maintains a page to share datasets she helped create here.
This week on Twitter (X.com), someone said it was their favorite graph. Upon replying I learned that he had used it for teaching. It’s fun when you know one of your ideas is out in the world helping people.
For real? I absolutely HOWLED when I found it on a google image search! Bravo! I taught HS Econ for many years and this was the kind of stuff that kept kids awake!
Blogger privilege is to manifest a new conversation on here. If one of my research articles were to achieve the same level of influence as the stuffed rat, then people might tweet something along the following lines:
This original project, both in terms of methodology and subject, is one of the first controlled experiments on intellectual property protection, which has inspired subsequent lab work on this issue. We present a color cube mechanism that provides a creative task for subjects to do in an experiment on creative output. The results indicate that IP protection alone does not cause people to become inventors, although entrepreneurs are encouraged to specialize by IP protection.
“Smile, Dictator, You’re On Camera,” (2017), with Matthew McMahon, Matthew Simpson and Bart Wilson. Southern Economic Journal, 84:1, 52-65.
The dictator game (DG) is attractive because of its simplicity. Out of thousands of replications of the DG, ours is probably the controlled experiment that has reduced “social distance” to the farthest extreme possible, while maintaining the key element of anonymity between the dictator and their receiver counterpart. In our experiment the dictator knows they are being watched, which is the opposite of the famous “double-blind” manipulation that removed even the view of the experimenter. As we predicted, people are more generous when they are being watched. Anyone teaching about DGs in the classroom should show our entertaining video of dictators making decisions in public: https://www.youtube.com/watch?v=vZHN8xyp6Y0&t=22s
There is a lot of talk about reference points. No matter how you feel about “behavioral” economics, I don’t think anyone would deny that reference-dependent behavior explains some choices, even very big ones like when to sell your house. Considering how important reference points are, can people conceive of the fact that different people have different reference points shaped by their different life experiences? Results of this study imply that I tend to assume that everyone else has my own reference point, which biases my beliefs about what others will do. Because this paper is short and simple, it would make a good assignment for students in either an experimental or econometrics class. I have a blog post on how to turn this paper into an assignment for students who are just learning about regression for the first time.
“If Wages Fell During a Recession,” (2022) with Daniel Houser, Journal of Economic Behavior and Organization. Vol. 200, 1141-1159.
The title comes from Truman Bewley’s book Why Wages Don’t Fall during a Recession. First, I’ll take some lines directly from his book summary:
A deep question in economics is why wages and salaries don’t fall during recessions. This is not true of other prices, which adjust relatively quickly to reflect changes in demand and supply. Although economists have posited many theories to account for wage rigidity, none is satisfactory. Eschewing “top-down” theorizing, Truman Bewley explored the puzzle by interviewing—during the recession of the early 1990s—over three hundred business executives and labor leaders as well as professional recruiters and advisors to the unemployed.
By taking this approach, gaining the confidence of his interlocutors and asking them detailed questions in a nonstructured way, he was able to uncover empirically the circumstances that give rise to wage rigidity. He found that the executives were averse to cutting wages of either current employees or new hires, even during the economic downturn when demand for their products fell sharply. They believed that cutting wages would hurt morale, which they felt was critical in gaining the cooperation of their employees and in convincing them to internalize the managers’ objectives for the company.
We are one of the first to take this important question to the laboratory. The nice thing about an experiment is that you can measure shirking precisely and you can get observations on wage cuts, which are rare in the naturally occurring American economy.
We find support for the morale theory, but a new puzzle got introduced along the way. Many of our subjects in the role of the employer cut the wages of their counterpart, which probably lowered their payment. Why didn’t they anticipate the retaliation against wage cuts? That question inspired the paper “My Reference Point, Not Yours.”
Andreoni & Miller (2002) have been cited over 2500 times for their experiment that shows demand curves for altruism slope down. Economic theory is not broken by generosity. We extend their work to show that demand curves for equality slope down. Individuals don’t love inequality, but they also don’t love parting with their own money. There is a higher demand for reducing inequality with other people’s money than with own income.
This is the last paper I’ll do here. At this point, readers probably would like a funny animal picture. Here’s a meme about the difficult life of computer programmers:
For decades, tech skills have had a high return in the labor market. There is very little empirical work on why more people do not try to become computer programmers, although there are policy discussions about confidence and encouragement.
I ran an experiment to measure something that is important and underexplored. One thing I found is that attempts to increase confidence, if not carefully evaluated, might backfire.
Would you predict it’s more important to have taken a class in programming or for a potential worker to report that they enjoy programming? My results imply that we should be doing more to understand both the causes and effects of subjective preferences (enjoyment) for tech work.
A few more decades to go here… I will try to top the stuffed rat picture.
Short post today because I’m busy watching my kids, who had their school canceled because of excessive heat, like many schools in Rhode Island today.
I thought this was a ridiculous decision until my son told me he heard from his teacher that his elementary school is the only one in town that has air conditioning for every classroom. Given that, the decision to cancel given the circumstances is at least reasonable, but the lack of AC is not.
It’s not just that hot classrooms are unpleasant for students and staff, or that sudden cancellations like this are a major burden for parents. Several economics papers have found that air conditioning significantly improves students’ learning as measured by test scores (though some find not). Park et al. (2020 AEJ: EP) find that:
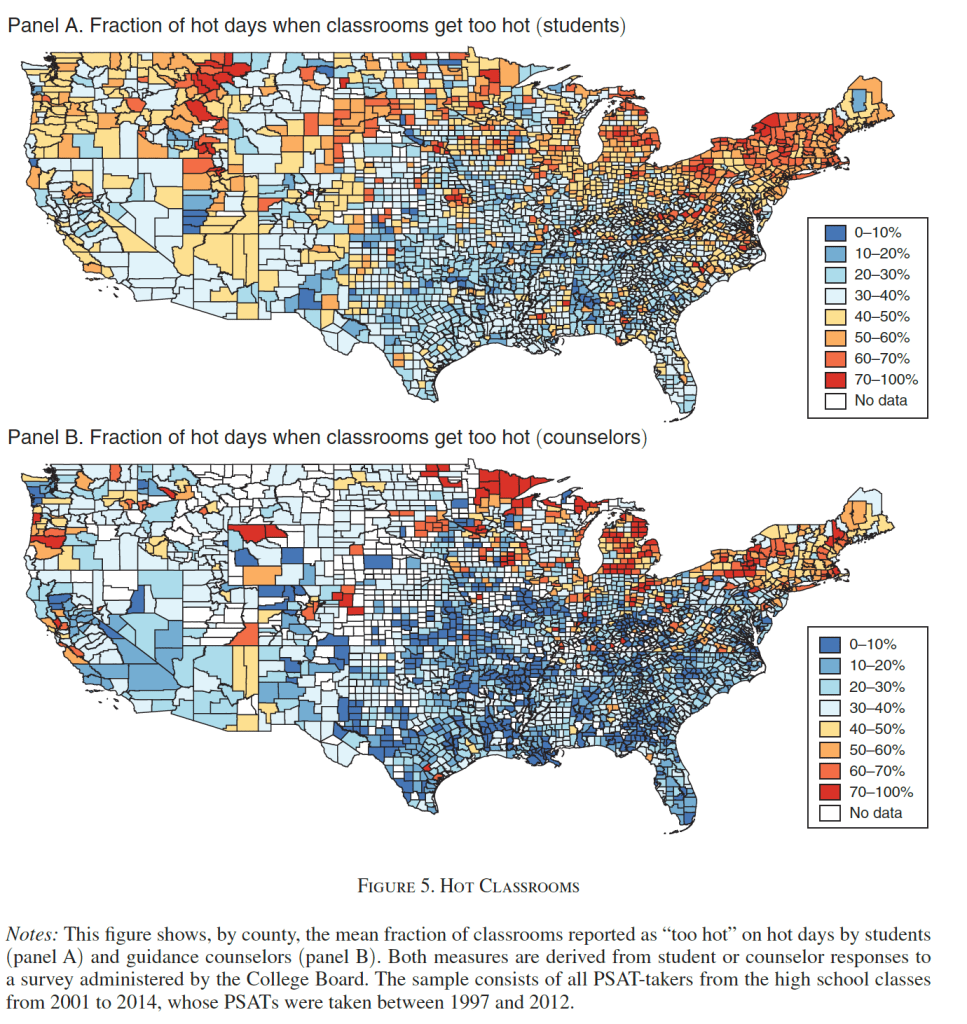
Student fixed effects models using 10 million students who retook the PSATs show that hotter school days in the years before the test was taken reduce scores, with extreme heat being particularly damaging. Weekend and summer temperatures have little impact, suggesting heat directly disrupts learning time. New nationwide, school-level measures of air conditioning penetration suggest patterns consistent with such infrastructure largely offsetting heat’s effects. Without air conditioning, a 1°F hotter school year reduces that year’s learning by 1 percent.
This can actually be a bigger issue in somewhat Northern places like Rhode Island- we’re South enough to get some quite hot days, but North enough that AC is not ubiquitous. Data from the Park paper shows that New York and New England are actually some of the worst places for hot schools:
This is because of the lack of AC in the North:
The days are only getting hotter…. it’s time to cool the schools.
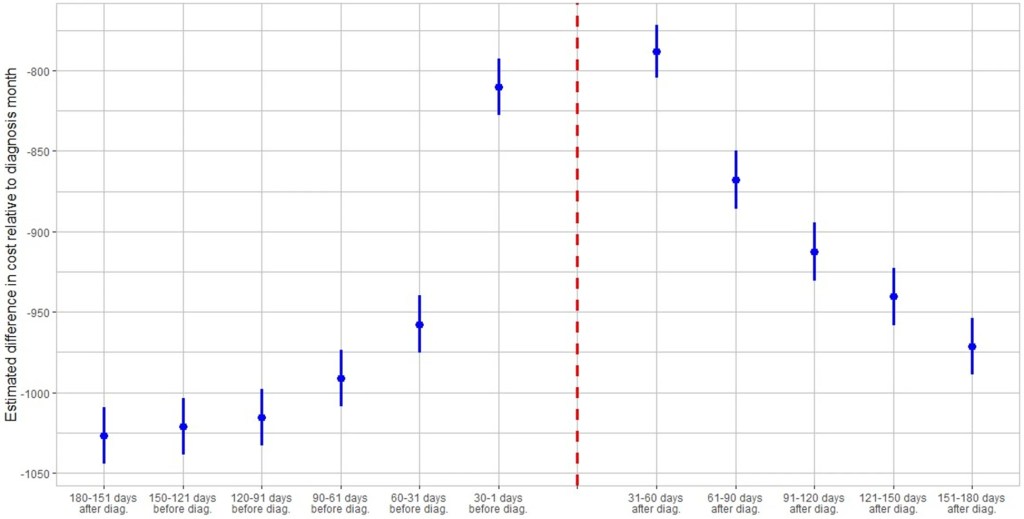
I’ve seen plenty of investigations of “Long Covid” based on surveys (ask people about their symptoms) or labs (x-ray the lungs, test the blood). But I just ran across a paper that uses insurance claims data instead, to test what happens to people’s use of medical care and their health spending in the months following a Covid diagnosis. The authors create some nice graphics showing that Long Covid is real and significant, in the sense that on average people use more health care for at least 6 months post-Covid compared to their pre-Covid baseline:
The graph is a bit odd in that its scales health spending relative to the month after people are diagnosed with Covid. Their spending that month is obviously high, so every other month winds up being negative, meaning just that they spent less than the month they had Covid. But the key is, how much less? At baseline 6 months prior it was over $1000/month less. The second month after the Covid diagnosis it was about $800 less- a big drop from the Covid month but still spending $200+/month more than baseline. Each month afterwards the “recovery” continues but even by month 6 its not quite back to baseline. I’m not posting it because it looks the same, but Figure 4 of the paper shows the same pattern for usage of health care services. By these measures, Long Covid is both statistically and economically significant and it can last at least 6 months, though worried people should know that it tends to get better each month.
I was somewhat surprised at the size of this “post Covid” effect, but much more surprised at the size of the “pre Covid” or “early Covid” effect- the run-up in spending in the months before a Covid diagnosis. For the month immediately before, the authors have a good explanation, the same one I had thought of- people are often sick with Covid a couple days before they get tested and diagnosed:
There is a lead-up of healthcare utilization to the diagnosis date as illustrated by the relatively high utilization levels 30–1 days before diagnosis. This may be attributed to healthcare visits only days prior to the lab-confirmed infection to assess symptoms before the manifestation or clinical detection of COVID-19.
But what about the second month prior to diagnosis? People are spending almost $150/month more than at the 6-month-prior baseline and it is clearly statistically significant (confidence intervals of months t-6 and t-2 don’t overlap). The authors appear not to discuss this at all in the paper, but to me ignoring this lead-up is burying the lede. What is going on here that looks like “Early Covid”?
My guess is that people were getting sick with other conditions, and something about those illnesses (weakened immune system, more time in hospitals near Covid patients) made them more likely to catch Covid. But I’d love to hear actual evidence about this or other theories. The authors, or someone else using the same data, could test whether the types of health care people are using more of 2 months pre-diagnosis are different from the ones they use more of 2 months post-diagnosis. Doctors could weigh in on the immunological plausibility of the “weakened immune system” idea. Researchers could test whether they see similar pre-trends / “Early Covid” in other claims/utilization data; probably they have but if these pre-trends hold up they seem worthy of a full paper.
Inpatient costs were 27% higher (95% CI 0.252, 0.285), but length of stay was 12% shorter (95% CI −0.131, −0.100), in Comprehensive Cancer Centers relative to community hospitals.
In other words, these cutting-edge hospitals that tend to treat complex cases are more expensive, as you would expect; but despite getting tough cases they actually manage a shorter average length of stay. We can’t nail down the mechanism for this but our guess is that they simply provide higher-quality care and make fewer errors, which lets people get well faster.
The NCI Cancer Centers Program was created as part of the National Cancer Act of 1971 and is one of the anchors of the nation’s cancer research effort. Through this program, NCI recognizes centers around the country that meet rigorous standards for transdisciplinary, state-of-the-art research focused on developing new and better approaches to preventing, diagnosing, and treating cancer.
Our paper focuses on New York state because of their excellent data, the New York State Statewide Planning and Research Cooperative System Hospital Inpatient Discharges dataset, which lets us track essentially all hospital patients in the state:
We use data on patient demographics, total treatment costs, and lengths of stay for patients discharged from New York hospitals with cancer-related diagnoses between 2017 and 2019.
You know I’m all about sharing data; you can find our data and code for the paper on my OSF page here.
My coauthor on this paper is Ryan Fodero, who wrote the initial draft of this paper in my Economics Senior Capstone class last Fall. He is deservedly first author- he had the idea, found the data, and wrote the first draft; I just offered comments, cleaned things up for publication, and dealt with the journal. I’ve published with undergraduates several times before but this is the first time I’ve seen one of my undergrads hit anything close to a top field journal. You can find a profile of Ryan here; I suspect it won’t be the last you hear of him.
That is the conclusion of a recent Philadelphia Fed working paper by Ronel Elul, Aaron Payne, and Sebastian Tilson. The fraud is that investors are buying properties to flip or rent out, but claim they are buying them to live there in order to get cheaper mortgages:
We identify occupancy fraud — borrowers who misrepresent their occupancy status as owner-occupants rather than investors — in residential mortgage originations. Unlike previous work, we show that fraud was prevalent in originations not just during the housing bubble, but also persists through more recent times. We also demonstrate that fraud is broad-based and appears in government-sponsored enterprise and bank portfolio loans, not just in private securitization; these fraudulent borrowers make up one-third of the effective investor population. Occupancy fraud allows riskier borrowers to obtain credit at lower interest rates.
One third of all investors is a lot of fraud! The flip side of this is that real estate investors are much more prevalent than the official data says:
We argue that the fraudulent purchasers that we identify are very likely to be investors and that accounting for fraud increases the size of the effective investor population by nearly 50 percent.
Many people blame investors for making housing unaffordable for regular people. Economists tend to disagree, and one of our arguments has been to point out that investors are still a small fraction of home buyers. However, official statistics recently showed the investor share over 25% (though dropping fast), and apparently that may still be an understatement. If investors are a problem, there are enough of them to be a big problem.
Of course, there are other reasons economists aren’t so concerned about real estate investors. One is that they can provide the valuable service of renting out homes to people who couldn’t qualify for a mortgage themselves (especially after 2010, when Dodd Frank made it difficult for people without great credit to qualify). Another is that many investors seem to be surprisingly bad at flipping homes for higher prices. The panic over “ibuyers” that would buy houses sight unseen based on algorithms abated when it turned out those those companies lost a ton of money, saw their stock prices plunge, and gave up.
The mortgage fraud paper also provides evidence of investors losing money. In particular, rather than fraudulent investors crowding out the good ones, they are actually more likely to end up defaulting on their purchases:
These fraudulent borrowers perform substantially worse than similar declared investors, defaulting at a 75 percent higher rate.
Still, such widespread fraud is concerning, and I hope lenders (especially the subsidized GSEs) find a way to crack down on it. Based on things I see people bragging about on social media, I’m guessing that tax fraud is also widespread in real estate investing, though I haven’t looked into the literature on it.
This mortgage fraud paper seems like a bombshell to me and I’m surprised it seems to have received no media attention; journalists take note. For everyone else, I suppose you read obscure econ blogs precisely to find out about the things that haven’t yet made the papers.