I provide a simple, clean panel dataset of the historical demographics of US stateshere.
I made this state-year level dataset from the individual-level responses in the Current Population Survey‘s Annual Social and Economic Supplement. It includes key demographic variables commonly used as controls in regressions: age, race, sex, marital status, income, education, health insurance.
This was no great feat, in that I’m sure hundreds of researchers have generated very similar datasets before- but as far as I can tell, none of them share it publicly like this. I hope that posting this will save the time of researchers who would otherwise spend a couple hours re-doing the same work themselves, and offer easy-to-use Stata and Excel files for students who might not be able to make one themselves.
I’ve often seen my own students start an empirical project where they have state-level data on their dependent and independent variables of interest, then realize they need some control variables and find that they are surprisingly hard to get. Census’ website is difficult to navigate and mostly offers its data one year at a time. IPUMS is great for getting individual-level responses; they have a tool that can export state-level data directly, but it is not built or advertised in a way that students end up actually using it for that, and it is limited to exporting 8000 cells of data at a time (the dataset I share has 53,856). The National Welfare Data is what I have been recommending to students for state-level controls, but its year coverage is more limited (1980-2023), and it contains welfare variables that are mostly extraneous for this. County-level data is available back to 1969, which could be aggregated to the state level, but it doesn’t have income or education.
Disclaimers: prior to 1977, some states are missing or are combined with nearby states (the data makes clear which ones). Some variables change how they are coded by Census / IPUMS over time. Age in particular sees several big changes to its universe and its top-coding, and race gets recoded in 2003. Therefore, this is not always a good dataset for measuring national trends in a variable over time, but it should still work well for making comparisons across states in a given year. If you are using this data in a regression, I strongly recommend controlling for year fixed effects to mitigate this issue. If you want to double-check my cleaning code, it is available here.
Once again, the state demographic data is available here. If you think there is a better source out there for historical state demographics, let us know below. See my data page for more cleaned-up versions of public datasets.
I found a new time series and panel data tool that I want to share. What does it do? It’s called xtbreak and it finds what are known as ‘structural breaks’ in the data. What does that mean? It means that the determinants of a dependent variable matter differently at different periods of time. In statistics we’d say that the regression coefficients are different during different periods of time. To elaborate, I’ll walk through the same example that the authors of the command use.
The data contains weekly US covid cases and deaths for 2020-2021. Here’s what it looks like:
So, what’s the data generating process? It stands to reason that the number of deaths is related to the number of cases one week prior. So, we can adopt the following model:
That seems reasonable. However, we suspect that δ is not the same across the entire sample period. Why not? Medical professionals learned how to better treat covid, and the public changed their behavior so that different types of people contracted covid. Further, once they contracted it, the public’s criteria for visiting the doctor changed. So, while the lagged number of cases is a reasonable determinant of deaths across the entire sample, we would expect it to predict a different number deaths at different times. In the model above, we are saying that δ changes over time and maybe at discrete points.
First, xtbreak allows us to test whether there are any structural breaks. Specifically, it can test whether there are S breaks rather than S-1 breaks. If the test statistic is greater than the critical statistics, then we can conclude that there are some number of breaks. Note that there being 5 breaks given that there are 4 depends on there also be at least 4 breaks. And since we can’t say that there are certainly 4 breaks rather than 3, it would be inappropriate to say that there are 4 or 5 breaks.
Great, so if there are three structural breaks, then when do they occur? xbtreak can answer that too (below). The three structural breaks are noted as the 20th week of 2020, the 51st week of 2020, and the 11th week of 2021. Conveniently, there is also a confidence interval. Note that the confidence intervals for 2020w11 and 2021w11 breaks are nice and precise with a 1-week confidence interval. The 2nd break, however, has a big 30-week confidence interval (nearly 7 months). So, while we suspect that there is a 3rdstructural break, we don’t know as precisely where it is.
Regardless, if there are three structural breaks, then that means that there are four time periods with different relationships between lagged covid cases and covid deaths. We can create a scatter plot of the raw data and run a regression to see the different slopes. Below we can see the different slopes that describe the impact of lagged covid cases on deaths. Sensibly, covid cases resulted in more deaths earlier during the pandemic. As time passed, the proportion of cases which resulted in death declined (as seen in the falling slope of the dots). It’s no wonder that people were freaking out at the start of the pandemic.
What’s nice about this method for finding breaks is that it is statistically determined. Of course, it’s important to have a theoretical motivation for why any breaks would occur in the first place. This method is more rigorous than eye-balling the data and provides opportunities to hypothesis test the number of breaks and their location. If you read the documentation, then there are other tests, such as breaks in the constant, that are also possible.
The Differences-in-Differences literature has blown up in the past several years. “Differences-in-Differences” refers to a statistical method that can be used to identify causal relationships (DID hereafter). If you’re interested in using the new methods in Stata, or just interested in what the big deal is, then this post is for you.
First, there’s the basic regression model where we have variables for time, treatment, and a variable that is the product of both. It looks like this:
The idea is that that there is that we can estimate the effect of time passing separately from the effect of the treatment. That allows us to ‘take out’ the effect of time’s passage and focus only on the effect of some treatment. Below is a common way of representing what’s going on in matrix form where the estimated y, yhat, is in each cell.
Each quadrant includes the estimated value for people who exist in each category. For the moment, let’s assume a one-time wave of treatment intervention that is applied to a subsample. That means that there is no one who is treated in the initial period. If the treatment was assigned randomly, then β=0 and we can simply use the differences between the two groups at time=1. But even if β≠0, then that difference between the treated and untreated groups at time=1 includes both the estimated effect of the treatment intervention and the effect of having already been treated prior to the intervention. In order to find the effect of the intervention, we need to take the 2nd difference. δ is the effect of the intervention. That’s what we want to know. We have δ and can start enacting policy and prescribing behavioral changes.
Easy Peasy Lemon Squeezy. Except… What if the treatment timing is different and those different treatment cohorts have different treatment effects (heterogeneous effects)?* What if the treatment effects change over time the longer an individual is treated (dynamic effects)**? Further, what if the there are non-parallel pre-existing time trends between the treated and untreated groups (non-parallel trends)?*** Are there design changes that allow us to estimate effects even if there are different time trends?**** There’re more problems, but these are enough for more than one blog post.
For the moment, I’ll focus on just the problem of non-parallel time trends.
What if untreated and the to-be-treated had different pre-treatment trends? Then, using the above design, the estimated δ doesn’t just measure the effect of the treatment intervention, it also detects the effect of the different time trend. In other words, if the treated group outcomes were already on a non-parallel trajectory with the untreated group, then it’s possible that the estimated δ is not at all the causal effect of the treatment, and that it’s partially or entirely detecting the different pre-existing trajectory.
Below are 3 figures. The first two show the causal interpretation of δ in which β=0 and β≠0. The 3rd illustrates how our estimated value of δ fails to be causal if there are non-parallel time trends between the treated and untreated groups. For ease, I’ve made β=0 in the 3rd graph (though it need not be – the graph is just messier). Note that the trends are not parallel and that the true δ differs from the estimated delta. Also important is that the direction of the bias is unknown without knowing the time trend for the treated group. It’s possible for the estimated δ to be positive or negative or zero, regardless of the true delta. This makes knowing the time trends really important.
STATA Implementation
If you’re worried about the problems that I mention above the short answer is that you want to install csdid2. This is the updated version of csdid & drdid. These allow us to address the first 3 asterisked threats to research design that I noted above (and more!). You can install these by running the below code:
program fra syntax anything, [all replace force] local from "https://friosavila.github.io/stpackages" tokenize `anything' if "`1'`2'"=="" net from `from' else if !inlist("`1'","describe", "install", "get") { display as error "`1' invalid subcommand" } else { net `1' `2', `all' `replace' from(`from') } qui:net from http://www.stata.com/ end fra install fra, replace fra install csdid2 ssc install coefplot
Once you have the methods installed, let’s examine an example by using the below code for a data set. The particulars of what we’re measuring aren’t important. I just want to get you started with the an application of the method.
local mixtape https://raw.githubusercontent.com/Mixtape-Sessions use `mixtape'/Advanced-DID/main/Exercises/Data/ehec_data.dta, clear qui sum year, meanonly replace yexp2 = cond(mi(yexp2), r(max) + 1, yexp2)
The csdid2 command is nice. You can use it to create an event study where stfips is the individual identifier, year is the time variable, and yexp2 denotes the times of treatment (the treatment cohorts).
The above output shows us many things, but I’ll address only a few of them. It shows us how treated individuals differ from not-yet treated individuals relative to the time just before the initial treatment. In the above table, we can see that the pre-treatment average effect is not statistically different from zero. We fail to reject the hypothesis that the treatment group pre-treatment average was identical to the not-yet treated average at the same time period. Hurrah! That’s good evidence for a significant effect of our treatment intervention. But… Those 8 preceding periods are all negative. That’s a little concerning. We can test the joint significance of those periods:
estat event, revent(-8/-1)
Uh oh. That small p-value means that the level of the 8 pretreatment periods significantly deviate from zero. Further, if you squint just a little, the coefficients appear to have a positive slope such that the post-treatment values would have been positive even without the treatment if the trend had continued. So, what now?
Wouldn’t it be cool if we knew the alternative scenario in which the treated individuals had not been treated? That’s the standard against which we’d test the observed post-treatment effects. Alas, we can’t see what didn’t happen. BUT, asserting some premises makes the job easier. Let’s say that the pre-treatment trend, whatever it is, would have continued had the treatment not been applied. That’s where the honestdid stata package comes in. Here’s the installation code:
local github https://raw.githubusercontent.com net install honestdid, from(`github'/mcaceresb/stata-honestdid/main) replace honestdid _plugin_check
What does this package do? It does exactly what we need. It assumes that the pre-treatment trend of the prior 8 periods continues, and then tests whether one or more post-treatment coefficients deviate from that trend. Further, as a matter of robustness, the trend that acts as the standard for comparison is allowed to deviate from the pre-treatment trend by a multiple, M, of the maximum pretreatment deviations from trend. If that’s kind of wonky – just imagine a cone that continues from the pre-treatment trend that plots the null hypotheses. Larger M’s imply larger cones. Let’s test to see whether the time-zero effect significantly differs from zero.
What does the above table tell us? It gives us several values of M and the confidence interval for the difference between the coefficient and the trend at the 95% level of confidence. The first CI is the original time-0 coefficient. When M is zero, then the null assumes the same linear trend as during the pretreatment. Again, M is the ratio by which maximum deviations from the trend during the pretreatment are used as the null hypothesis during the post-treatment period. So, above, we can see that the initial treatment effect deviates from the linear pretreatment trend. However, if our standard is the maximum deviation from trend that existed prior to the treatment, then we find that the alpha is just barely greater than 0.05 (because the CI just barely includes zero).
That’s the process. Of course, robustness checks are necessary and there are plenty of margins for kicking the tires. One can vary the pre-treatment periods which determine the pre-trend, which post-treatment coefficient(s) to test, and the value of M that should be the standard for inference. The creators of the honestdid seem to like the standard of identifying the minimum M at which the coefficient fails to be significant. I suspect that further updates to the program will come along that spits that specific number out by default.
I’ve left a lot out of the DID discussion and why it’s such a big deal. But I wanted to share some of what I’ve learned recently with an easy-to-implement example. Do you have questions, comments, or suggestions? Please let me know in the comments below.
The above code and description is heavily based on the original author’s support documentation and my own Statalist post. You can read more at the above links and the below references.
*Sun, Liyang, and Sarah Abraham. 2021. “Estimating Dynamic Treatment Effects in Event Studies with Heterogeneous Treatment Effects.” Journal of Econometrics, Themed Issue: Treatment Effect 1, 225 (2): 175–99. https://doi.org/10.1016/j.jeconom.2020.09.006.
**Sant’Anna, Pedro H. C., and Jun Zhao. 2020. “Doubly Robust Difference-in-Differences Estimators.” Journal of Econometrics 219 (1): 101–22. https://doi.org/10.1016/j.jeconom.2020.06.003.
***Callaway, Brantly, and Pedro H. C. Santa Anna. 2021. “Difference-in-Differences with Multiple Time Periods.” Journal of Econometrics, Themed Issue: Treatment Effect 1, 225 (2): 200–230. https://doi.org/10.1016/j.jeconom.2020.12.001.
****Rambachan, Ashesh, and Jonathan Roth. 2023. “A More Credible Approach to Parallel Trends.” The Review of Economic Studies 90 (5): 2555–91. https://doi.org/10.1093/restud/rdad018.
Lot’s of economists use FRED – that’s Federal Reserve Economic Data for the uninitiated. It’s super easy to use for basic queries, data transformations, graphs, and even maps. Downloading a single data series or even the same series for multiple geographic locations is also easy. But downloading distinct data series can be a hassle.
I’ve written previously about how the Excel add-on makes getting data more convenient. One of the problems with the Excel add-on is that locating the appropriate series can be difficult – I recommend using the FRED website to query data and then use the Excel add-on to obtain it. One major flaw is how the data is formatted in excel. A separate column of dates is downloaded for each series and the same dates aren’t aligned with one another. Further, re-downloading the data with small changes is almost impossible.
Only recently have I realized that there is an alternative that is better still! Stata has access to the FRED API and can import data sets directly in to its memory. There are no redundant date variables and the observations are all aligned by date.
In a May post I described a paper my student my student had written on how college majors predict the likelihood of being married and having children later in life.
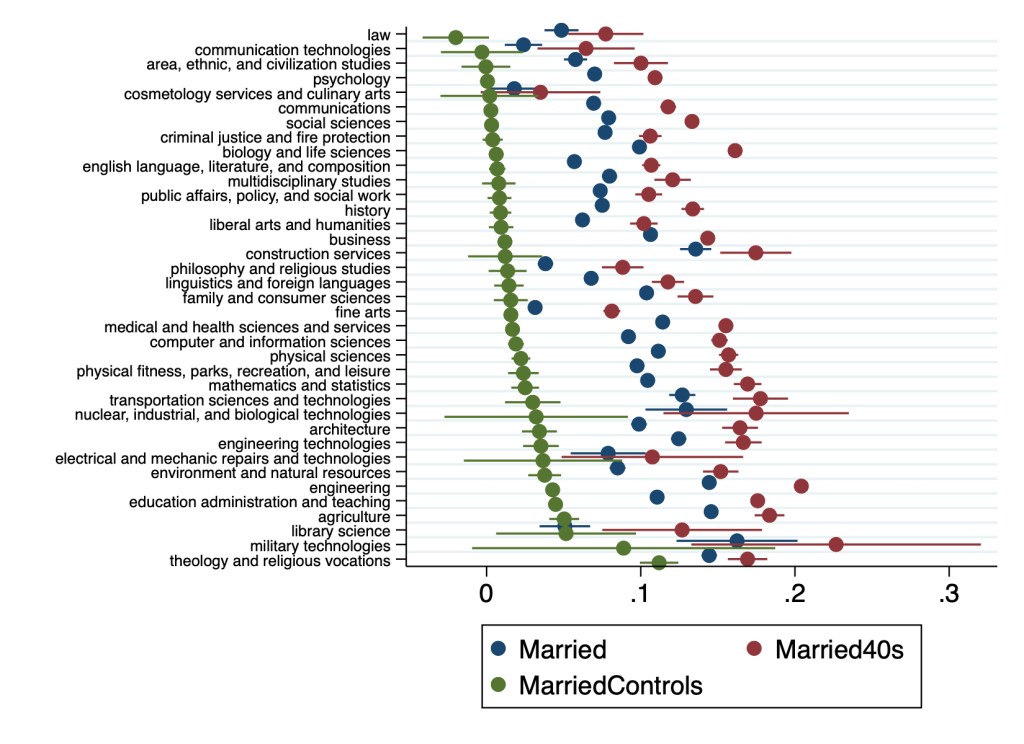
Since then I joined the paper as a coauthor and rewrote it to send to academic journals. I’m now revising it to resubmit to a journal after referee comments. The best referee suggestion was to move our huge tables to an appendix and replace them with figures. I just figured out how to do this in Stata using coefplot, and wanted to share some of the results:
Points represent marginal effects of coefficient estimates from Logit regressions estimating the effect of college major on marriage rates relative to non-college-graduates. All regressions control for sex, race, ethnicity, age, and state of residence. MarriedControls additionally controls for personal income, family income, employment status, and number of children. Married (blue points) includes all adults, others include only 40-49 year-olds. Lines through points represent 95% confidence intervals.Points represent coefficient estimates from Poisson regressions estimating the effect of college major on the number of children in the household relative to non-college-graduates. All regressions control for sex, race, ethnicity, age, and state of residence. ChildrenControls additionally controls for personal income, family income, employment status, and number of children. Children (blue points) includes all adults, others include only 40-49 year-olds. Lines through points represent 95% confidence intervals.
Many details have changed since Hannah’s original version, and a lot depends on the exact specification used. But 3 big points from the original paper still stand:
Almost all majors are more likely to be married than non-college-graduates
The association of college education with childbearing is more mixed than its almost-uniformly-positive association with marriage
College education is far from uniform; differences between some majors are larger than the average difference between college graduates and non-graduates