Back in August I listed the most-read posts of 2023. Here I will finish out the year by listing a few more highlights. This has been another big year for our website.
Zachary has been giving out good advice for economics teachers, backed up by his data. All professors can read: 5 Easy Steps to Improve Your Course Evals. Econ professors check: Update on Game Theory Teaching. It’s about how to teach Game Theory, but I also see it as a testament to how much a course can improve if you allow a teacher to iterate multiple times at the same school. Administrators, take note.
What We Are Learning about Paper Books is jointly my reflection on AI generative books and a review of Tyler Cowen’s new book GOAT. I’m a techno-optimist, but I think there is value in an old-fashioned paper book, mostly from a behavioral or neuro perspective.
Have you ever tried to do something objectively. It’s impossible. We might try, but how do we know when we’ve failed to compensate for a bias or when we’ve over compensated. Russ Roberts taught me 1) all people have biases, 2) all analysis is by people, & 3) analysis should be interpreted conditional on the bias – not discarded because of it.
The only people who don’t have biases are persons without values – which is no one. We all have apriori beliefs that color the way that we understand the world. Recognizing that is the first step. The second step is to evaluate your own possible biases or the bias of someone’s work. They may have blind spots or points of overemphasis. And that’s OK. One of the best ways to detect and correct these is to expose your ideas and work to a variety of people. It’s great to talk to new people and to have friends who are different from you. They help you see what you can’t.
Finally, because biases are something that everyone has, they are not a good cause to dismiss a claim or evidence. Unless you’re engaged in political combat, your role is usually not to defeat an opponent. Rather, we like to believe true things about the world. Let’s get truer beliefs by peering through the veil of bias to see what’s on the other side. For example, everyone who’s ever read Robert Higgs can tell that he’s biased. He wants the government to do much less and he’s proud of it. That doesn’t mesh well with many readers. But it’d be intellectually lazy to dismiss Higgs’ claims on these grounds. Higgs’ math and statistics work no differently than his ideological opponents. It’s important for us to filter which claims are a reflection of an author’s values, and the claims that are a reflection of the author’s work. If we focus on the latter, then you’ll learn more true things.
Know Multiple Models
In economics, we love our models. A model is just a fancy word which means ‘argument’. That’s what a mathematical model is. It’s just an argument that asserts which variables matter and how. Models help us to make sense of the world. However, different models are applicable in different contexts. The reason that we have multiple models rather than just one big one is because they act as short-cuts when we encounter different circumstances. Understanding the world with these models requires recognizing context clues so that you apply the correct model.
Models often conflict with one another or imply different things for their variables. This helps us to 1) understand the world more clearly, and 2) helps us to discriminate between which model is applicable to the circumstances. David Andolfatto likes to be clear about his models and wants other people to do the same. It helps different people cut past the baggage that they bring to the table and communicate more effectively.
For example, power dynamics are a real thing and matter a lot in personal relationships. I definitely have some power over my children, my spouse, and my students. They are different kinds of power with different means and bounds, but it’s pretty clear that I have some power and that we’re not equal in deed. Another model is the competitive market model that is governed by property rights and consensual transactions. If I try to exert some power in this latter circumstance, then I may end up not trading with anyone and forgoing gains from trade. It’s not that the two models are at odds. It’s that they are theories for different circumstances. It’s our job to discriminate between the circumstances and between the models. Doing so helps us to understand both the world one another better.
Information on the internet was born free, but now lives everywhere in walled gardens. Blogging sometimes feels like a throwback to an earlier era. So many newer platforms have eclipsed blogs in popularity, almost all of which are harder to search and discover. Facebook was walled off from the beginning, Twitter is becoming more so. Podcasts and video tend to be open in theory, but hard to search as most lack transcripts. Longer-form writing is increasingly hidden behind paywalls on news sites and Substack. People have complained for years that Google search is getting worse; there are many reasons for this, like a complacent company culture and the cat-and-mouse game with SEO companies, but one is this rising tide of content that is harder to search and link.
To me part of the value of blogging is precisely that it remains open in an increasingly closed world. Its influence relative to the rest of the internet has waned since its heydey in ~2009, but most of this is due to how the rest of the internet has grown explosively at the expense of the real world; in absolute terms the influence of blogging remains high, and perhaps rising.
The closing internet of late 2023 will not last forever. Like so much else, AI is transforming it, for better and worse. AI is making it cheap and easy to produce transcripts of podcasts and videos, making them more searchable. Because AI needs large amounts of text to train models, text becomes more valuable. Open blogs become more influential because they become part of the training data for AI; because of what we have written here, AI will think and sound a little bit more like us. I think this is great, but others have the opposite reaction. The New York Times is suing to exclude their data from training AIs, and to delete any models trained with it. Twitter is becoming more closed partly in an attempt to limit scraping by AIs.
So AI leads to human material being easier for search engines to index, and some harder; it also means there will be a flood of AI-produced material, mostly low-quality, clogging up search results. The perpetual challenge of search engines putting relevant, high-quality results first will become much harder, a challenge which AI will of course be set to solve. Search engines already have surprisingly big problems with not indexing writing at all; searching for a post on my old blog with exact quotes and not finding it made me realize Google was missing some posts there, and Bing and DuckDuckGo were missing all of them. While we’re waiting for AI to solve and/or worsen this problem, Gwern has a great page of tips on searching for hard-to-find documents and information, both the kind that is buried deep down in Google and the kind that is not there at all.
Today I’ll go into more detail on several measures of the labor force, but I won’t only compare it to 2019. I’ll compare it to all available data. And the sum total of the data suggests the 2023 was one of the best years for the US labor market on record. Note: December 2023 data isn’t available until January 5th, so I’m jumping the gun a little bit. I’m going to assume December looks much like November. We can revisit in 2 weeks if that was wrong.
The Unemployment Rate has been under 4% for the entire year. The last time this happened (date goes back to 1948) was 1969, though 2022 and 2019 were both very close (just one month at 4%). In fact, the entire period from 1965-1969 was 4% or less, though following January 1970 there wasn’t single month under 4% under the year 2000!
Like GDP, the Unemployment Rate is one of the broadest and most widely used macro measures we have, but they are also often criticized for their shortcomings, as I wrote in an April 2023 post.
With that in mind, let’s look to some other measures of the labor market.
Boaz Weinstein is a really smart guy. At age 16 the US Chess Federation conferred on him the second highest (“Life Master”) of the eight master ratings. As a junior in high school, he won a stock-picking contest sponsored by Newsday, beating out a field of about 5000 students. He started interning with Merrill Lynch at age 15, during summer breaks. He has the honor of being blacklisted at casinos for his ability to count cards.
He entered into heavy duty financial trading right out of college, and quickly became a rock star. He joined international investment bank Deutsche Bank in 1998, and led their trading of then-esoteric credit default swaps (securities that payout when borrowers default). Within a few years his group was managing some $30 billion in positions, and typically netting hundreds of millions in profits per year. In 2001, Weinstein was named a managing director of the company, at the tender age of 27.
Weinstein left Deutsche Bank in 2009 and started his own credit-focused hedge fund, Saba Capital Management. One of its many coups was to identify some massive, seemingly irrational trades in 2012 that were skewing the credit default markets. Weinstein pounced early, and made bank by taking the opposite sides of these trades. He let other traders in on the secret, and they also took opposing positions.
(It turned out these huge trades were made by a trader in J. P. Morgan’s London trading office, Bruno Iksil, who was nick-named the London Whale. Morgan’s losses from Iksil’s trades mounted to some $6.2 billion.)
For what it’s worth, Weinstein is by all accounts a really nice guy. This is not necessarily typical for many high-powered Wall Street traders who have been as successful as he.
Weinstein and the Sprawling World of Closed End Funds
If you have a brokerage account, you can buy individual securities, like Microsoft common stock shares, or bonds issued by General Motors. Many investors would prefer not to have to do the work of screening and buying and holding hundreds of stocks or bonds. No problem, there exist many funds, which do all the work for you. For instance, the SPY fund holds shares of all 500 large-cap American companies that are in the S&P 500 index, so you can simply buy shares of the one fund, SPY.
Without going too deeply into all this, there are three main types of funds held by retail investors. These are traditional open-end mutual funds, the more common exchange-traded funds (ETFs), and closed end funds (CEFs). CEFs come in many flavors, with some holding plain stocks, and others holding high-yield bonds or loans, or less-common assets like spicy CLO securities. A distinctive feature of CEFs is that the market price per share often differs from the net asset value (NAV) per share. A CEF may trade at a premium or a discount to NAV, and that premium or discount can vary widely with time and among otherwise-similar funds. This makes optimal investing in CEFs very complex, but potentially-rewarding: if you can keep rotating among CEF’s, buying ones that are heavily discounted, then selling them when the discount closes, you can in theory do much better than a simple buy and hold investor.
I played around in this area, but did not want to devote the time and attention to doing it well, considering I only wanted to devote 3-4% of my personal portfolio to CEFs. There are over 400 closed end funds out there. So, I looked into funds whose managers would (for a small fee) do that optimized buying and selling of CEFs for me.
It turns out that there are several such funds-of-CEF-funds. These include ETFs with the symbols YYY and PCEF, CEFS, and also the closed end funds FOF and RIV. YYY and PCEF tend to operate passively, using fairly mechanical rules. PCEF aims to simply replicate a broad-based index of the CEF universe, while YYY rebalances periodically to replicate an “intelligent” index which ranks CEFs by yield, discount to net asset value and liquidity. FOF holds and adjusts a basket of undervalued CEFs chosen by active managers, while RIV holds a diverse pot of high-yield securities, including CEFs. The consensus among most advisers I follow is that FOF is a decent buy when it is trading at a significant discount, but it makes no sense to buy it now, when it is at a relatively high premium; you would be better off just buying a basket of CEFs yourself.
I settled on using CEFS (Saba Closed-End Funds ETF) for my closed end fund exposure. It is very actively co-managed by Saba Capital Management, which is headed by none other than Boaz Weinstein. I trust whatever team he puts together. Among other things, Saba will buy shares in a CEF that trades at a discount, then pressure that fund’s management to take actions to close the discount.
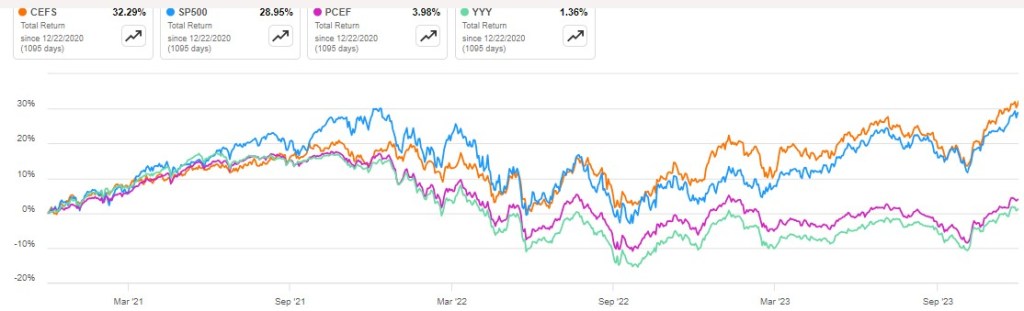
The results speak for themselves. Here is a plot of CEFS (orange line) versus SP500 index (blue), and two passively-managed ETFs that hold CEFs, PCEF (purple) and YYY (green) over the past three years:
The Y axis is total return (price action plus reinvestment of dividends). CEFS smoked the other two funds-of-funds, and even edged out the S&P in this time period. It currently pays out a juicy 9% annualized distribution. Thank you, Mr. Weinstein, and Merry Christmas to all my fellow investors.
Boilerplate disclaimer: Nothing in this article should be regarded as advice to buy or sell any security.
Whether it’s a high holiday or just a nice day to get Chinese food with your family and watch old movies, I hope you all have the very best Christmas possible, no matter what that means for you. But do take the day off if at all possible and, if the opportunity arises, make it a little easier for those who can’t.
I have a paper that emphasizes ChatGPT errors. It is important to recognize that LLMs can make mistakes. However, someone could look at our data and emphasize the opposite potential interpretation. On many points, and even when coming up with citations, the LLM generated correct sentences. More than half of the content was good.
Apparently, LLMs just solved an unsolvable math problem. Is there anything they can’t do? Considering how much of human expression and culture revolves around religion, we can expect AI’s to get involved in that aspect of life.
Alex thinks it will be a short hop from Personal Jesus Chatbot to a whole new AI religion. We’ll see. People have had “LLMs” in the form of human pastors, shaman, or rabbis for a long time, and yet sticking to one sacred text for reference has been stable. I think people might feel the same way in the AI era – stick to the canon for a common point of reference. Text written before the AI era will be considered special for a long time, I predict. Even AI’s ought to be suspicious of AI-generated content, just in the way that humans are now (or are they?).
Many religious traditions have lots of training literature. (In our ChatGPT errors paper, we expect LLMs to produce reliable content on topics for which there is plentiful training literature.)
I gave ChatGPT this prompt:
Can you write a Bible study? I’d like this to be appropriate for the season of Advent, but I’d like most of the Bible readings to be from the book of Job. I’d like to consider what Job was going through, because he was trying to understand the human condition and our relationship to God before the idea of Jesus. Job had a conception of the goodness of God, but he didn’t have the hope of the Gospel. Can you work with that?
The Differences-in-Differences literature has blown up in the past several years. “Differences-in-Differences” refers to a statistical method that can be used to identify causal relationships (DID hereafter). If you’re interested in using the new methods in Stata, or just interested in what the big deal is, then this post is for you.
First, there’s the basic regression model where we have variables for time, treatment, and a variable that is the product of both. It looks like this:
The idea is that that there is that we can estimate the effect of time passing separately from the effect of the treatment. That allows us to ‘take out’ the effect of time’s passage and focus only on the effect of some treatment. Below is a common way of representing what’s going on in matrix form where the estimated y, yhat, is in each cell.
Each quadrant includes the estimated value for people who exist in each category. For the moment, let’s assume a one-time wave of treatment intervention that is applied to a subsample. That means that there is no one who is treated in the initial period. If the treatment was assigned randomly, then β=0 and we can simply use the differences between the two groups at time=1. But even if β≠0, then that difference between the treated and untreated groups at time=1 includes both the estimated effect of the treatment intervention and the effect of having already been treated prior to the intervention. In order to find the effect of the intervention, we need to take the 2nd difference. δ is the effect of the intervention. That’s what we want to know. We have δ and can start enacting policy and prescribing behavioral changes.
Easy Peasy Lemon Squeezy. Except… What if the treatment timing is different and those different treatment cohorts have different treatment effects (heterogeneous effects)?* What if the treatment effects change over time the longer an individual is treated (dynamic effects)**? Further, what if the there are non-parallel pre-existing time trends between the treated and untreated groups (non-parallel trends)?*** Are there design changes that allow us to estimate effects even if there are different time trends?**** There’re more problems, but these are enough for more than one blog post.
For the moment, I’ll focus on just the problem of non-parallel time trends.
What if untreated and the to-be-treated had different pre-treatment trends? Then, using the above design, the estimated δ doesn’t just measure the effect of the treatment intervention, it also detects the effect of the different time trend. In other words, if the treated group outcomes were already on a non-parallel trajectory with the untreated group, then it’s possible that the estimated δ is not at all the causal effect of the treatment, and that it’s partially or entirely detecting the different pre-existing trajectory.
Below are 3 figures. The first two show the causal interpretation of δ in which β=0 and β≠0. The 3rd illustrates how our estimated value of δ fails to be causal if there are non-parallel time trends between the treated and untreated groups. For ease, I’ve made β=0 in the 3rd graph (though it need not be – the graph is just messier). Note that the trends are not parallel and that the true δ differs from the estimated delta. Also important is that the direction of the bias is unknown without knowing the time trend for the treated group. It’s possible for the estimated δ to be positive or negative or zero, regardless of the true delta. This makes knowing the time trends really important.
STATA Implementation
If you’re worried about the problems that I mention above the short answer is that you want to install csdid2. This is the updated version of csdid & drdid. These allow us to address the first 3 asterisked threats to research design that I noted above (and more!). You can install these by running the below code:
program fra syntax anything, [all replace force] local from "https://friosavila.github.io/stpackages" tokenize `anything' if "`1'`2'"=="" net from `from' else if !inlist("`1'","describe", "install", "get") { display as error "`1' invalid subcommand" } else { net `1' `2', `all' `replace' from(`from') } qui:net from http://www.stata.com/ end fra install fra, replace fra install csdid2 ssc install coefplot
Once you have the methods installed, let’s examine an example by using the below code for a data set. The particulars of what we’re measuring aren’t important. I just want to get you started with the an application of the method.
local mixtape https://raw.githubusercontent.com/Mixtape-Sessions use `mixtape'/Advanced-DID/main/Exercises/Data/ehec_data.dta, clear qui sum year, meanonly replace yexp2 = cond(mi(yexp2), r(max) + 1, yexp2)
The csdid2 command is nice. You can use it to create an event study where stfips is the individual identifier, year is the time variable, and yexp2 denotes the times of treatment (the treatment cohorts).
The above output shows us many things, but I’ll address only a few of them. It shows us how treated individuals differ from not-yet treated individuals relative to the time just before the initial treatment. In the above table, we can see that the pre-treatment average effect is not statistically different from zero. We fail to reject the hypothesis that the treatment group pre-treatment average was identical to the not-yet treated average at the same time period. Hurrah! That’s good evidence for a significant effect of our treatment intervention. But… Those 8 preceding periods are all negative. That’s a little concerning. We can test the joint significance of those periods:
estat event, revent(-8/-1)
Uh oh. That small p-value means that the level of the 8 pretreatment periods significantly deviate from zero. Further, if you squint just a little, the coefficients appear to have a positive slope such that the post-treatment values would have been positive even without the treatment if the trend had continued. So, what now?
Wouldn’t it be cool if we knew the alternative scenario in which the treated individuals had not been treated? That’s the standard against which we’d test the observed post-treatment effects. Alas, we can’t see what didn’t happen. BUT, asserting some premises makes the job easier. Let’s say that the pre-treatment trend, whatever it is, would have continued had the treatment not been applied. That’s where the honestdid stata package comes in. Here’s the installation code:
local github https://raw.githubusercontent.com net install honestdid, from(`github'/mcaceresb/stata-honestdid/main) replace honestdid _plugin_check
What does this package do? It does exactly what we need. It assumes that the pre-treatment trend of the prior 8 periods continues, and then tests whether one or more post-treatment coefficients deviate from that trend. Further, as a matter of robustness, the trend that acts as the standard for comparison is allowed to deviate from the pre-treatment trend by a multiple, M, of the maximum pretreatment deviations from trend. If that’s kind of wonky – just imagine a cone that continues from the pre-treatment trend that plots the null hypotheses. Larger M’s imply larger cones. Let’s test to see whether the time-zero effect significantly differs from zero.
What does the above table tell us? It gives us several values of M and the confidence interval for the difference between the coefficient and the trend at the 95% level of confidence. The first CI is the original time-0 coefficient. When M is zero, then the null assumes the same linear trend as during the pretreatment. Again, M is the ratio by which maximum deviations from the trend during the pretreatment are used as the null hypothesis during the post-treatment period. So, above, we can see that the initial treatment effect deviates from the linear pretreatment trend. However, if our standard is the maximum deviation from trend that existed prior to the treatment, then we find that the alpha is just barely greater than 0.05 (because the CI just barely includes zero).
That’s the process. Of course, robustness checks are necessary and there are plenty of margins for kicking the tires. One can vary the pre-treatment periods which determine the pre-trend, which post-treatment coefficient(s) to test, and the value of M that should be the standard for inference. The creators of the honestdid seem to like the standard of identifying the minimum M at which the coefficient fails to be significant. I suspect that further updates to the program will come along that spits that specific number out by default.
I’ve left a lot out of the DID discussion and why it’s such a big deal. But I wanted to share some of what I’ve learned recently with an easy-to-implement example. Do you have questions, comments, or suggestions? Please let me know in the comments below.
The above code and description is heavily based on the original author’s support documentation and my own Statalist post. You can read more at the above links and the below references.
*Sun, Liyang, and Sarah Abraham. 2021. “Estimating Dynamic Treatment Effects in Event Studies with Heterogeneous Treatment Effects.” Journal of Econometrics, Themed Issue: Treatment Effect 1, 225 (2): 175–99. https://doi.org/10.1016/j.jeconom.2020.09.006.
**Sant’Anna, Pedro H. C., and Jun Zhao. 2020. “Doubly Robust Difference-in-Differences Estimators.” Journal of Econometrics 219 (1): 101–22. https://doi.org/10.1016/j.jeconom.2020.06.003.
***Callaway, Brantly, and Pedro H. C. Santa Anna. 2021. “Difference-in-Differences with Multiple Time Periods.” Journal of Econometrics, Themed Issue: Treatment Effect 1, 225 (2): 200–230. https://doi.org/10.1016/j.jeconom.2020.12.001.
****Rambachan, Ashesh, and Jonathan Roth. 2023. “A More Credible Approach to Parallel Trends.” The Review of Economic Studies 90 (5): 2555–91. https://doi.org/10.1093/restud/rdad018.
2023 continues to be a dangerous year for eminent economists. We have once again lost a Nobel laureate who was influential even by the standard of Nobelists, Robert Solow:
I’m sure you will soon see many tributes that discuss his namesake Solow Model (MR already has one), or discuss him as a person. I never got to meet him (just saw him give a talk) and the Solow Model is well known, so I thought I’d take this occasion to discuss one of his lesser-known papers- “Sustainability: An Economists Perspective“. What follows comes from my 2009 reaction to his paper:
Lately many journalists and folks on X/Twitter have pointed out a seeming disconnect: by almost any normal indicator, the US economy is doing just fine (possibly good or great). But Americans still seem dissatisfied with the economy. I wanted to put all the data showing this disconnect into one post.
In particular, let’s make a comparison between November 2019 and November 2023 economic data (in some cases 2019q3 and 2023q3) to see how much things have changed. Or haven’t changed. For many indicators, it’s remarkable how similar things are to probably the last month before anyone most normal people ever heard the word “coronavirus.”
First, let’s start with “how people think the economy is doing.” Here’s two surveys that go back far enough:
The University of Michigan survey of Consumer Sentiment is a very long running survey, going back to the 1950s. In November 2019 it was at roughly the highest it had ever been, with the exception of the late 1990s. The reading for 2023 is much, much lower. A reading close to 60 is something you almost never see outside of recessions.
The Civiqs survey doesn’t go back as far as the Michigan survey, but it does provide very detailed, real-time assessments of what Americans are thinking about the economy. And they think it’s much worse than November 2019. More Americans rate the economy as “very bad” (about 40%) than the sum of “fairly good” and “very good” (33%). The two surveys are very much in alignment, and others show the same thing.