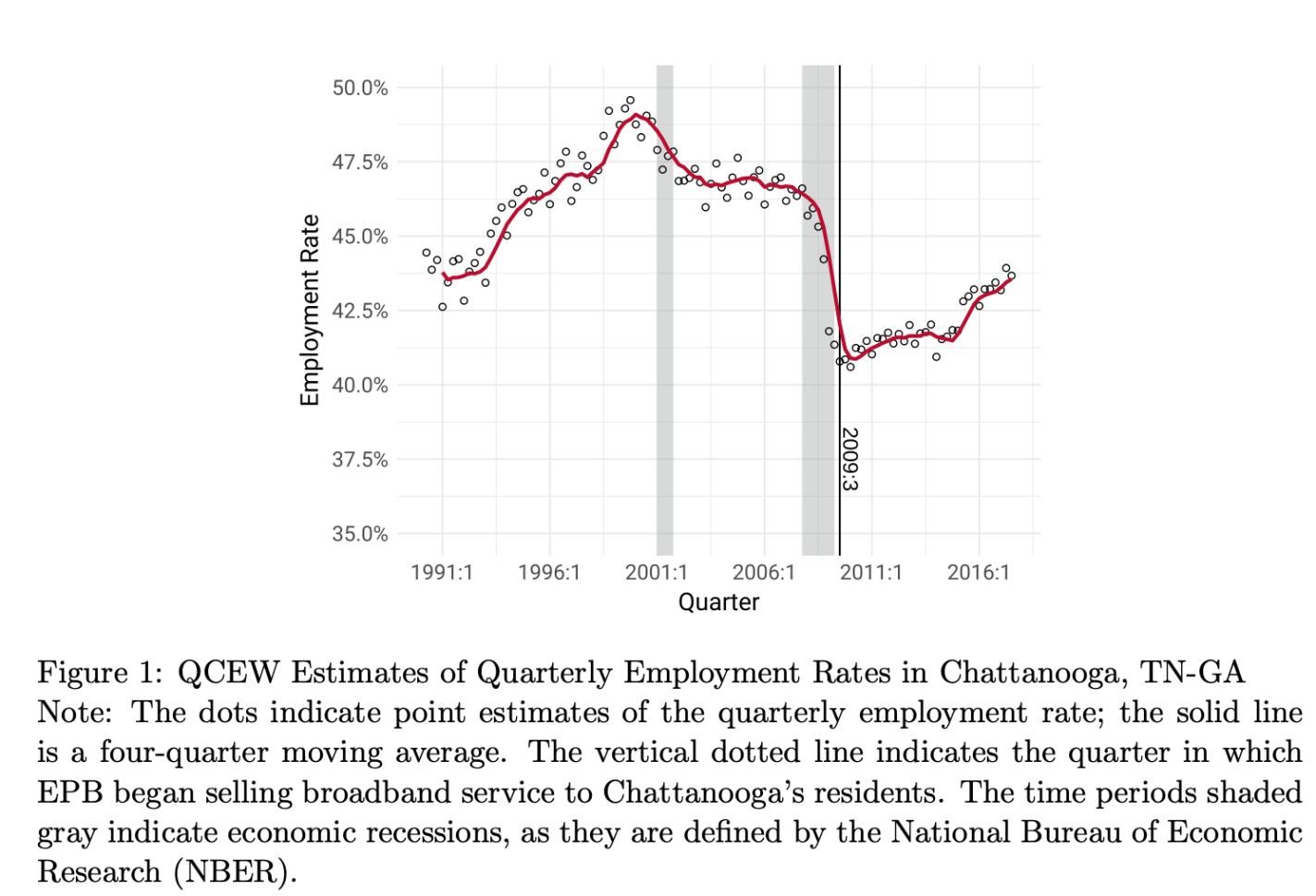
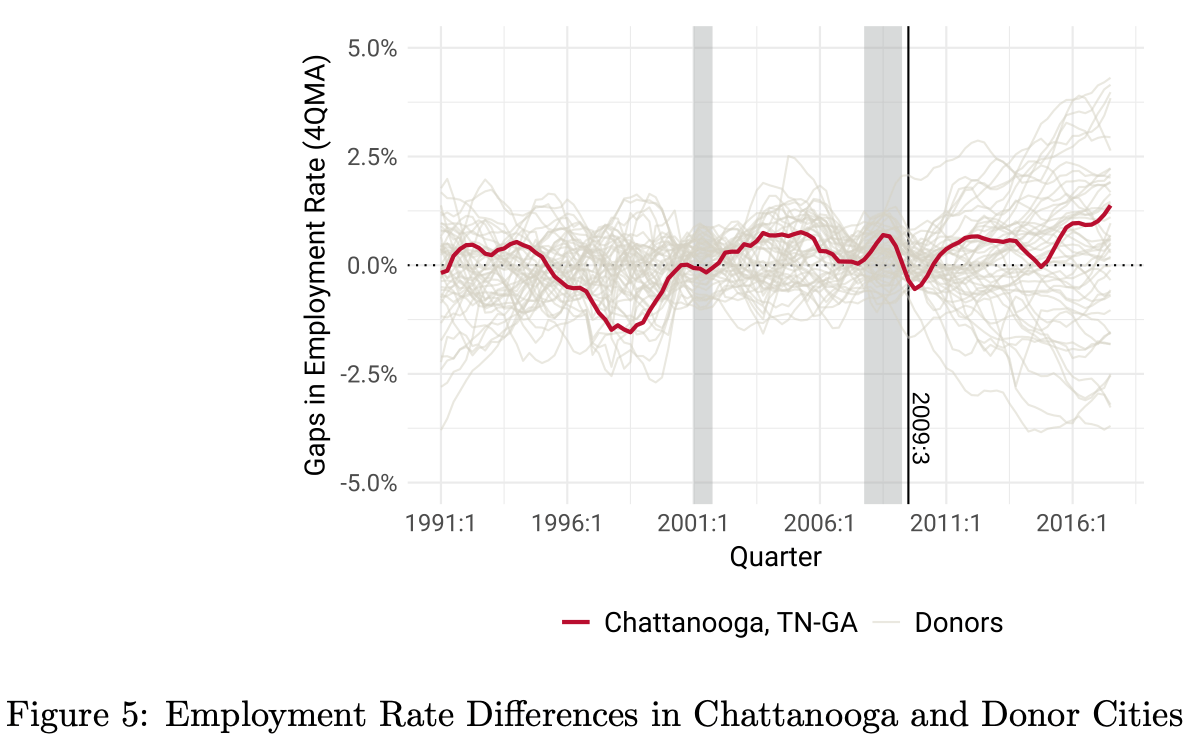
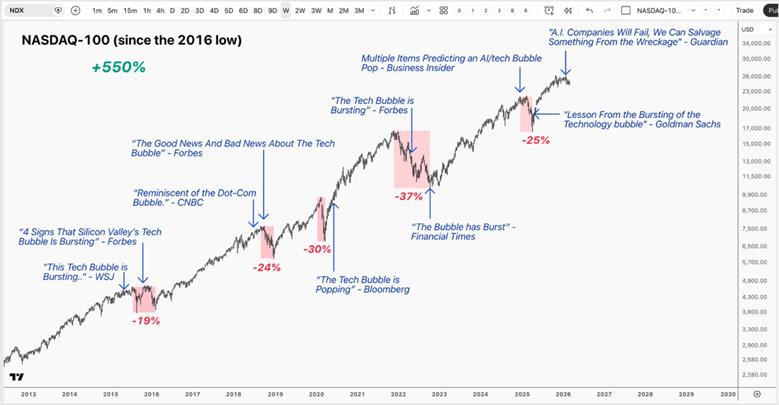
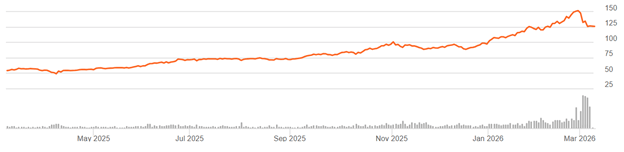
Nearly every interior wall and ceiling in every home in America is covered with sheetrock = drywall = gypsum board. Sheetrock (a brand name for drywall) consists of an interior layer of rigid gypsum (a mineral composed of calcium sulfate dihydrate) plus some additives, with outside layers of strong paper or fiberglass. It normally comes in 4 ft x 8 ft sheets.
Normal houses have a framework of mainly 2×4 or larger wood lumber. Each wall has vertical 2×4 studs, spaced every 16”. Sheetrock is trimmed to size, and nailed or (these days) screwed into the studs.
That is the theory, anyway.
I have never done this stuff at large scale before, other than clumsily patching occasional small dings in a wall. A little while ago, I got to experience the process, hands-on. I was part of a team that helped someone whose basement had flooded. We cut out the lower ~4 ft of drywall, and replaced it with fresh drywall.
First, how to you cut drywall? A long, straight cut is accomplished by drawing a straight line and cutting along it, all the way through one layer of the facing paper. Then you hang the drywall sheet on the edge of a table, and crack the interior gypsum layer. Then you cut the other side of the paper. The end result of such a cut is like this:

Typically, you install drywall on the ceiling first. Then the top 4 ft of the walls, then the bottom 4 ft of the walls. You butt the pieces close to each other. For the lowest piece of drywall, you insert a curved metal wedge under it, and step on the wedge with your foot to lift that drywall piece to butt its top edge up against the upper piece. If you look carefully near the middle of the following photo, you can see the red wedge I used to jack up that small lower piece of drywall. It’s OK to leave a gap between the floor and the lower edge of the bottom drywall, since that gap will be covered by baseboard.

This was in a bathroom. I cut the lower green pieces with a little hand power saw, and screwed them into the studs, using the green and black driver visible on the stand in the left foreground.
The next two photos are before and after of a bedroom wall, again showing the bottom course of sheetrock we installed.


Filling in Cracks and Holes
As you can see, at this stage, there are like ¼” cracks between the installed sheets of sheetrock, and the mounting screw holes are visible. These imperfections are filled in with goo called joint compound, or “mud.” The mud is applied with a “knife” like this:

Cracks are covered with paper or fiberglass tape, with mud smeared over the tape. Typically, three layers of mud are needed to achieve perfect, smooth coverage. Each layer must dry hard before applying the next layer. Each layer may be sanded lightly as needed.
A key technique is to tilt the knife so the mud is maybe 1/16” thick over the tape or over a screw, but taper the mud to zero thickness on the wall away from the tape or screw. This feathering is essential; if your mud layer ends with appreciable thickness instead of feathering, you have to do a lot of sanding to get a smooth blending into the plain drywall at that edge. Pro tip: carefully stir more water into the joint compound as needed to keep it wet and flowing, especially for overnight storage. This video from Vancouver Carpenter displays mudding technique.
That is mainly it. For perspective and confidence building, it is helpful to work with an expert, as I was able to do.