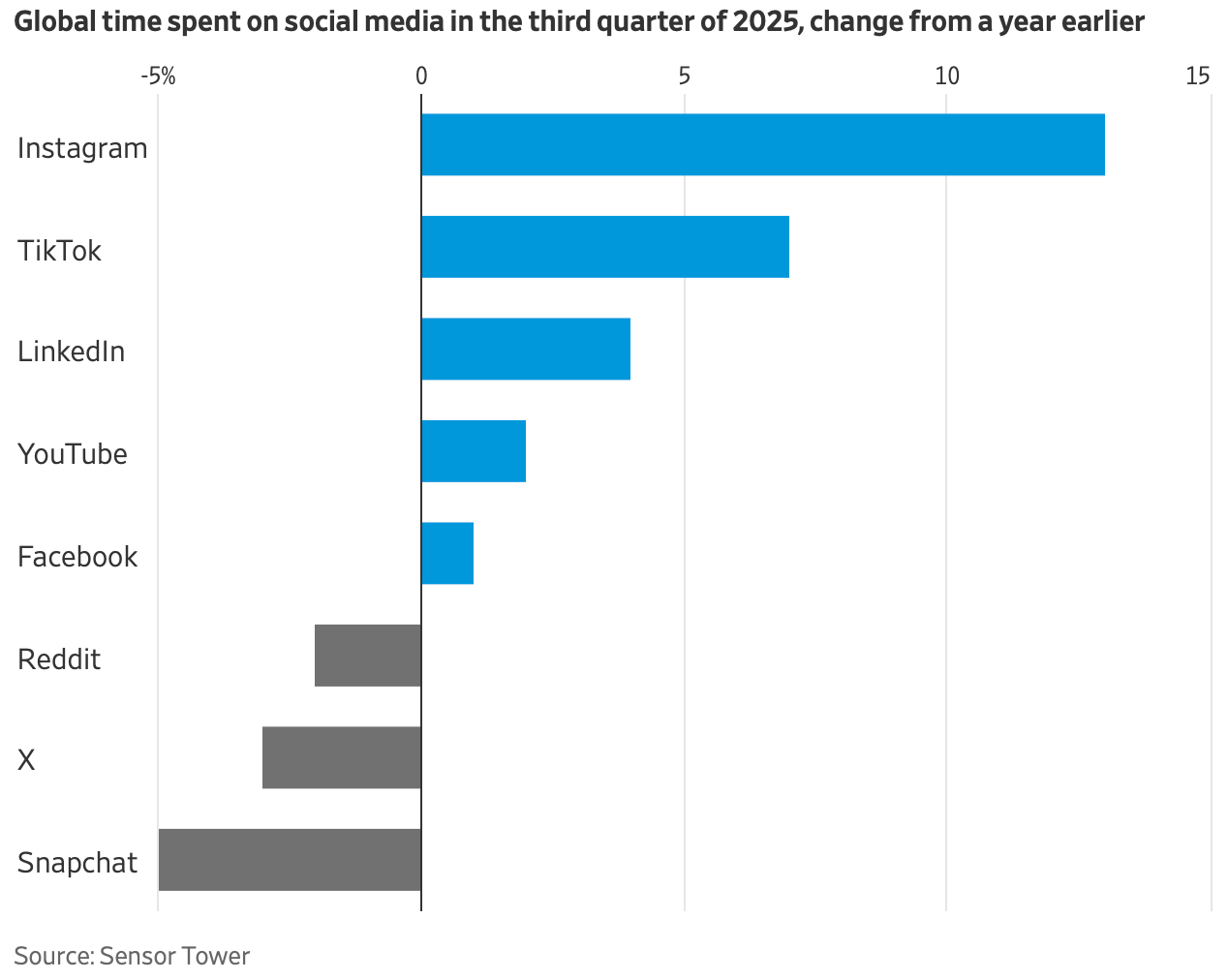“Who serves in secret police forces? Throughout history, units such as Hitler’s Gestapo, Stalin’s NKVD, or Assad’s Air Force Intelligence Directorate have been at the core of state repression. Secret police agents surveil, torture, and even kill potential enemies within the elite and society at large. Why would anyone do such dirty work for the regime? Are these people sadistic psychopaths, sectarian fanatics, or forced by the regime to terrorize the population? While this may be the case for some individuals, we believe that the typical profile of secret police agents is shaped by the logic of bureaucratic careers.”
The details and history in the paper are illuminating. The economic logic is simple, but it remains fascinating to be reminded of how far the reinforcing incentives of shame, power, and labor market demand can go when trying to understand the world. To recap the obvious
For some the opportunity for cruelty is benefit and others a cost, no doubt heterogeneous across context for many (but not all). The selection effects into ICE officers is obvious.
Shame selects as well. The larger the fraction of the American public that view ICE behavior as shameful and cruel, the fewer and more specific the individuals who will select in.
Labor demand for individuals is heterogeneous in multiple dimension, but it always weaker for those who are broadly incompetent.
Combine those three and you get what we are observing: those with the weakest opportunities in the labor market are selecting into ICE service because they face the lowest opportunity cost. If there is a positive correlation between enjoying cruelty and weak labor market opportunties (which I am willing to believe there is. Few enjoy working with ill-adjusted, cruel people), then the broad incompetence selected into ICE ranks will be stronger. If being ill-adjusted and cruel limits the scale of your social network, leaving you isolated and lonely, then the expected shame of ICE services is lower, selecting for still greater cruelty within officers. Through this mechanism cruelty and incompetence don’t just correlate, they reinforce, until you are left with a very specific set of individuals exercising violent discretion.
To be clear this isn’t a complex or profound model. The individual insights are obvious, but it remains useful to consider them within the framework of a toy model because they emphasize how mutually-reinforcing incentives can create shocking institutional outcomes.
Efforts to establish the death toll in the Iranian protests are confounded by the regime’s internet blockade, but even the most conservative estimates take the tally way beyond some of the most brutal political crackdowns in modern history.
Even the lowest estimates—between 2,000 and 3,000—have surged past the death tolls in unrest during protests in 2019 and 2022.
I have sadly seen much higher estimates circulating which may be confirmed eventually.
I’m writing because I am catching up on the backlog of The Answer is Transaction Costs (TAITC), a podcast hosted by Michael Munger. Specifically, in an episode published August 27, 2024, a listener writes asking about what seems to be the extremely costly practice of interviewing college applicants prior to acceptance.
As it turns out, I work at a private university that enacted an interview policy in a quasi-random way and the university president gave me permission to share.
Initially, my university did not interview standard applicants. Our aid packages were poorly designed because applicants tend to look similar on paper. There was a pooling equilibrium at the application stage. As a result, we accepted a high proportion and offered some generous aid packages to students who were not good mission fits and we neglected some who were. Aid packages are scarce resources, and we didn’t have enough information to economize on them well.
The situation was impossible for the admissions team. The amount of aid that they could award was endogenous to the number of applicant deposits because student attendance drives revenue. But, the deposits were endogenous to the aid packages offered! There was a separating equilibrium where some good students attended along with some students who were a poor fit and were over-awarded aid. The latter attended one or two semesters before departing the university, harming retention and revenues. Great but under-awarded students tended not to attend our university. Student morale was also low due to poor fits and their friends leaving.
Even before Elon Musk gutted X’s content moderation, James Bailey was tired of the shouting. “It’s like a cursed artifact that gives you great power to keep up with what’s going on, but at the cost of subtly corrupting your soul,” said the 38-year-old Providence College economics professor.
He retreated. This year, he realized he was spending five to 10 minutes a day on a site he used to ignore.
The WSJ reporter contacted me after seeing my previous post about LinkedIn here, explaining how I think LinkedIn has improved as a way to share and read articles, and was always good as a way to keep up with former students. Just in the short time since the WSJ article came out, I finally used LinkedIn for one of its official purposes, hiring, where it worked wonders helping to fill a last-minute vacancy.
If you don’t trust me or the WSJ to identify the hot social network, lets see what the actual cool kids are up to
One of the major goals of the new Trump administration, particularly the DOGE unit, was to shrink the size of the federal government’s budget. Did they achieve this goal?
Last spring both my co-blogger Zachary and I pointed to a tool from the Brookings Institution to track federal spending, pulling in data directly from the US Treasury in a convenient format. Back in March I said “this will be a useful tool to follow going forward.” Now we have a full year of spending data for 2025.
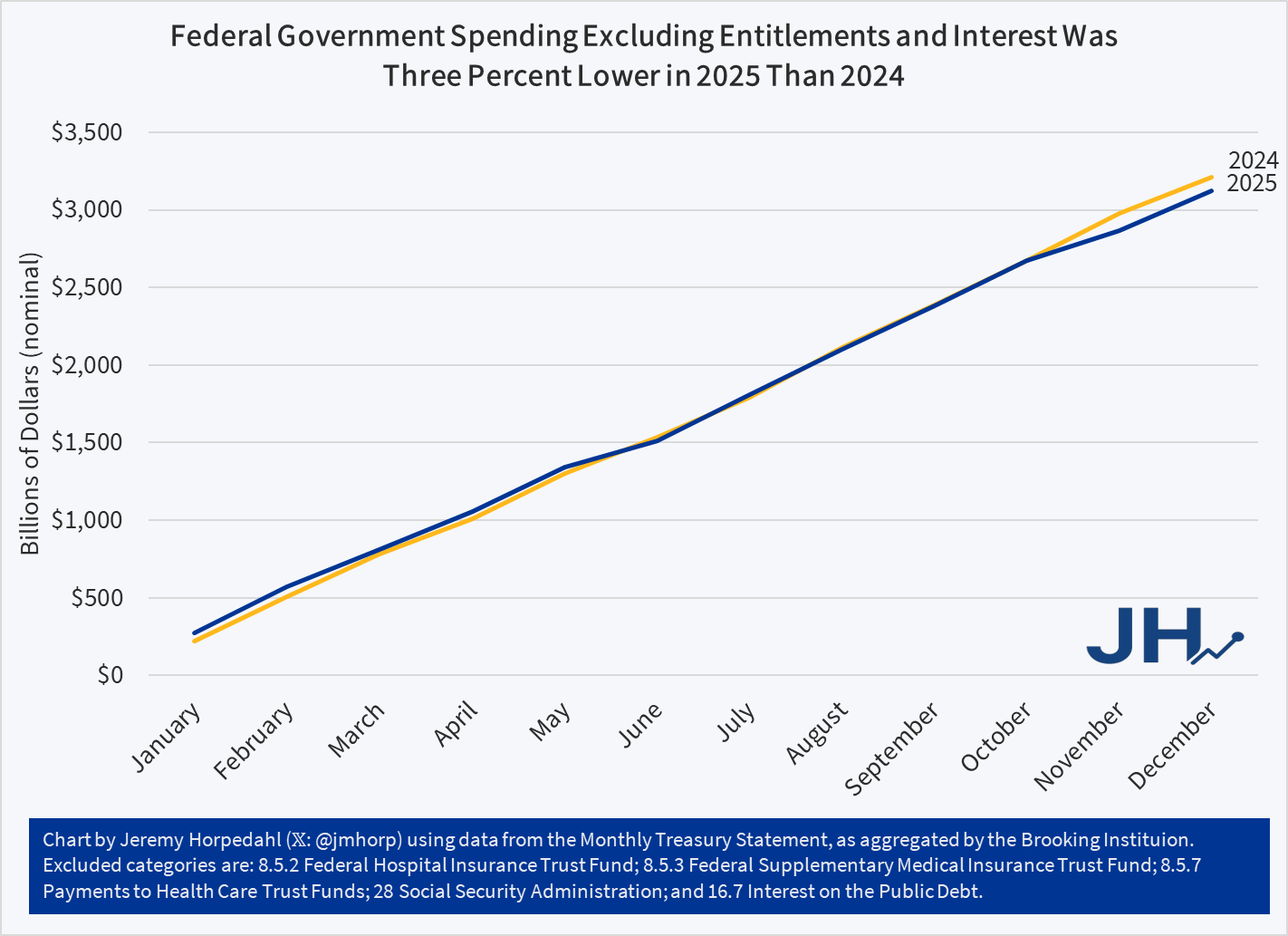
When we look at total spending for Calendar Year 2025, it was about $318 billion higher than 2024, or about 4 percent higher. So, it seems that by that measure, the cuts that the Trump administration made were too small to overcome the other areas that grew.
But…
It may be more useful to remove some spending from the equation. In particular, entitlement programs and interest spending are very large spending categories that aren’t subject to the annual budgeting process. Of course, any program is ultimately under the control of Congress, so it’s a little bit of a cheat to remove Social Security and Medicare, but those programs are on autopilot with respect to the annual federal budget process. They are worth talking about, but they are probably worth talking about separately (especially because they have their own funding mechanisms). And interest on the debt isn’t something a President can control directly: it can only be reduced in future years by closing the budget gap today.
Removing those programs — which constitute about $4.8 trillion of the $7.9 trillion in 2025 spending (so a lot!) — gives you this chart (note: figures have been slightly updated with more complete data since I originally posted this chart):
Federal spending by this measure was about $85 Billion lower in 2025 than the prior year, or about 5 percent. And that’s in nominal terms: it is an even bigger cut if we adjust for inflation. Notice too that the pattern fits what we might expect: spending was slightly higher in the first half of the year (before any Trump changes could have had much of an effect), almost exactly equal for most of the second half, and then slightly below once we get to November and December (after the Deferred Resignation Program layoffs in October). If we ignore the first two months of the year (when it would have been really hard for Trump to have an effect), the drop in spending is about 8 percent.
What were the biggest cuts that led to the $85 billion drop? Keep in mind that some programs increased spending, such as military spending, so there are more than $85 billion in cuts. Using the Daily Treasury Statement categories, here are the big ones:
Federal Financing Bank (Treasury): $59 billion
Department of Education: $46.8 billion
USAID: $30.2 billion
EPA: $17 billion (though EPA seems to have gone on a spending binge at the end of 2024. Compared with 2023, the first Trump year was 50% higher!)
Federal Employee Insurance Payment (OPM): $16.3 billion
Those are all the programs I could find that declined by at least $1 billion, totaling a little over $200 billion. There were some other highly salient cuts that were under a billion dollars (such as the Corporation for Public Broadcasting, which was completely eliminated). Looking at that list I don’t think there is an easy way to sum up a “theme,” but I think the real theme is that if the Trump administration wants 2026 discretionary spending to be even lower than 2025, they will really need some major action from Congress. These cuts are mostly low-hanging fruit, and some are long-running goals of the GOP (such as Dept. of Education, foreign aid, and public television).
Of course, to really get federal spending under control, Congress will have to tackle entitlement reform and shrink the budget deficit to lower interest costs. Social Security, Medicare, and interest payments — the bulk of federal spending, over 60% of the total — increase by 9% in 2025. Again, it was probably unreasonable to expect Trump and Congress to have done anything major with them in a single year, but something must be done soon: the Social Security Old Age trust fund will be depleted in about 8 years, and the Medicare Part A trust fund will be depleted in about 10 years.
This will be a longer-than-usual post, since I will try to include all the steps I used to grow salad ingredients in a compact (AeroGarden-type) hydroponics system. I hope this encourages readers to try this for themselves. See my previous post for an introduction to the hardware, including small modifications I made to it. I used a less-expensive ($45), reliable 18-hole MUGFA model here, but all the AeroGardens and its many knockoffs should work similarly. Most plant roots need access to oxygen as well as to water; these hydroponic units allow the upper few inches of the root to sit in a (moist) “grow sponge” up out of the water to help with aerobic metabolism.
Step 1. Unbox the hydroponics unit, set up per instructions near a power outlet. Fill tank close to upper volume marking.
Step 2. Add nutrients to the water in the tank: usually there are two small plastic bottles, one with nutrient mix “A” and the other with nutrient mix “B”, initially as dry granules. Add water to the fill lines of each of these bottles with the granules, shake till dissolved. (You can’t mix the A and B solutions directly together without dilution, because some components would precipitate out as solids. So, you must add first one solution, then the other, to the large amount of water in the tank.)
There is more than one way to do this. I pulled the deck off the tank, used a large measuring cup to get water from my sink into the tank, a little below the full line. For say 5 liters of water, I add about 25 ml of nutrient Solution A, stir well, then add 25 ml of Solution B and stir. You could also keep the deck on, have the circulation pump running, and slowly pour the nutrient solutions in through the fill hole (frontmost center hole in the deck). You don’t have to be precise on amounts.
Step 3. Put the plastic baskets (sponge supports) in their holes in the deck, and put the conical porous planting sponges/plugs in the baskets. Let the sponges soak up water and swell. (This pre-wetting may not be necessary; it just worked for me).
Step 4. Plant the seeds: Each sponge has a narrow hole in its top. You need to get your seed down to the bottom of the hole. I pulled one moist sponge out at a time and propped it upright in a little holder on a table where I could work on it. I used the end of plastic bread tie to pick up seeds from a little plate and poke them down to the bottom of the hole. You have to make a judgment call how many seeds to plant in each hole. Lettuce seeds are large and pretty reliable, so I used two lettuce seeds for each lettuce sponge. Same for arugula (turns out that it was better to NOT pre-soak the arugula seeds, contrary to popular wisdom). If both seeds sprout, it’s OK to have two lettuce plants per hole, though you may not get much more production than from one plant per hole. For parsley*, where I wanted 2-3 plants per hole, I used three seeds each. For the tiny thyme seeds, I used about 5 seeds, figuring I could thin if they all came up. For cilantro, I used two pre-soaked seeds. I really wanted chives, but they are hard to sprout in these hydroponics units. I used five chive seeds each in two holes, but they never really sprouted, so I ended up planting something else in their holes.
I chose all fairly low-growing plants, no basil or tomatoes. Larger plants such as micro-dwarf tomatoes can be grown in these hydroponics units; also basil, though need to aggressively keep cutting it back. It may be best to choose all low or all high plants for a given grow campaign. See this Reddit thread for more discussion of growing things in a MUGFA unit.
Once all the plugs are back in their holders, you stick a light-blocking sticker on top of each basket. Each sticker has a hole in the middle where the plants can grow up through, but they block most of the light from hitting the grow sponge, to prevent algae growth. Then pop a clear plastic seeding cover dome on top of each hole, and you are done. The cover domes keep the seeds extra moist for sprouting; remove the domes after sprouting. Make sure the circulation pump is running and the grow lights are on (typically cycling on 16 hours/off 8 hours). This seems like a lot of work describing it here, but it goes fast once you have the rhythm. Once this setup stage is done, you can just sit back and let everything unfold, no muss, no fuss. Here is the seeded, covered state of affairs:
Picture: Seeds placed in grow sponges on Jan 14. Note green light-blocking stickers, and clear cover domes to keep seeds moist for germination. The overhead sunlamp has a lot of blue and red LEDs (which the plants use for photosynthesis), which gives all these photos a purple cast.
Jan 28 (Two weeks after planting): seedlings. Note some unused holes are covered, to keep light out of the nutrient solution in the tank. The center hole in front is used for refilling the tank.
Feb 6. Showing roots of an arugula plant, 23 days after planting.
Step 5. Maintenance during 2-4 month grow cycle. Monitor water level via viewing port in front. Top up as needed. Add nutrients as you add water (approx. 5 ml of Solution A and 5 ml Solution B, per liter of added water). The water will not go down very fast during the first month, but once plants get established, water will likely be needed every 5-10 days. If you keep trimming outside leaves every several days, you can get away with having densely planted greens, whereas if you only harvest say every two weeks, the plants get so big they would crowd each other if you plant in every hole on the deck.
Optional: Supposedly it helps to keep the acidity (pH) of the nutrient solution in the range of 5.5-6.5. I think most users don’t bother checking this, since the nutrient solutions are buffered to try to keep pH in balance. Being a retired chemical engineer, I got this General Hydroponics kit for measuring and adjusting pH. On several occasions, the pH in the tank was about 6.5. That was probably perfectly fine, but I went ahead and added about 1/8 teaspoon of the pH lowering solution, to bring it down to about 6.0. I also got a meter for measuring Electrical Conductivity/Total Dissolved Solids to monitor that parameter, but it was not necessary.
Feb 16: After a month, some greens are ready to snip the outer leaves. Lettuces (buttercrunch, red oak, romaine) on the right, herbs on the left.
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Feb 17: Harvesting a small salad or sandwich filler every 2-3 days now.
March 6: Full sized, regular small harvests. All the lettuces worked great, buttercrunch is especially soft and sweet. Arugula (from the mustard plant family) gave a spicy edge. Italian parsley and thyme added flavor. The cilantro was slower growing, and only gave a few sprigs total.
Closeup March 16 (three months), just before closing out the grow cycle. Arugula foreground, lettuce top and right, thyme on left, Italian parsley upper left corner.
Step 6. Close out grow cycle. At some point, typically 2-4 months, it is time to bring a grow cycle to a close. I suppose with something like dwarf tomatoes, you could keep going longer, though you might need to pull the deck up and trim the roots periodically. In my case, after three months, the arugula and cilantro were starting to bolt, though the lettuce, thyme, and parsley were still going strong. As of mid-March, my focus turned to outside planting, so I harvested all the remaining crops on the MUGFA, turned off the power, and gently pulled the deck off the tank. The whole space under the deck was a tangled mass of roots. I used kitchen shears to cut roots loose, enough to pull all the grow sponges and baskets out. The sponges got discarded, and the baskets saved for next time. I peeled off and saved the round green light-blocking stickers for re-use. I cleared all the rootlets from the filter sponge on the pump inlet. Then I washed out the tank per instructions. It took maybe 45 minutes for all this clean-out, to leave the unit ready for a next round of growing.
Stay tuned for a future blog post on growing watercress, which went really well this past fall. Looking to the future: In Jan 2026 I plan to do a replant of this 18-hole (blocked down to 14-holes) MUGFA device, sowing less lettuce (since we buy that anyway) but more arugula/Italian parsley/thyme for nutritious flavorings. For replacement nutrients and grow sponges, I got a Haligo hydroponics kit like this (about $12).
Growing these salad/sandwich ingredients in the kitchen under a built-in sunlamp provided good cheer and a bit of healthy food during the dark winter months. The clean hydroponic setup removed concerns about insect pests or under/overwatering. It was a hobby; at this toy scale it did not “save money”, though from these learnings I could probably rig a larger homemade hydroponics setup which might reduce grocery costs. This exercise led to fun conversations with visitors and children, and was a reminder that nearly everything we eat comes from water, nutrients, and light, directly or indirectly.
*Pro tips on germinating parsley seeds – – Parsley seeds have a tough coating, and can take weeks to germinate. Some techniques to speed things up:
( 1 ) Lightly abrade the seeds by gently rubbing between sheets of sandpaper.
( 2 ) Soak in warmish water for 24-48 hours.
( 3 ) For older seeds, cold stratification (1–2 weeks in a damp paper towel in the fridge) may help break dormancy.
The confluence of politics, recent interest in agent-based computational modeling, and Pluribus have convinced me now is the time to write about the “Cooperative Corridor”. At one point I thought about making this the theme of a book, but my research has become overwhelmingly about criminal justice, so it got permanently sidelined. But hey, a blog post floating in the primordial ether of the internet is better than a book that never actually gets written.
It’s cooperation all the way down
Economic policy discussions are riddled with “Theories of Everything”. Two of my favorites are the “Housing” and “Insurance” theories of everything. Housing concerns such huge fractions of household wealth, expenditures, and risk exposure that the political climate at any moment in time can be reduced to what policy or leader voters think is the most expedient route to paying their mortgage or lowering their rent. Similarly, the decision making of economic agents can, through a surprisingly modest number of logical contortions, always be reduced to efforts to acquire, produce, or exchange insurance against risk. These aren’t “monocausal” theories of history so much as attempts to distill a conversation to a one or two variable model. They’re rhetorical tools as much as anything.
My mental model of the world is that it is cooperation all the way down. Everything humans do within the social space i.e. external to themselves, is about coping with obstacles to cooperating with others. It is a fundamental truth that humans are, relative to most other species, useless on our own. There are whole genres of “survival” reality television predicated on this concept. If you drop a human sans tools or support in the wilderness, they will likely die within a matter of days. This makes for bad television, so they are typically equipped with a fundamental tool (e.g. firestarting flint, steel knife, cooking pot, composite bow, etc) after months of planning and training for this specific moment (along with a crew trained to intervene if/when the individual is on the precipice of actual death). Even then, it is considered quite the achievement to survive 30 days, by the end of which even the most accomplished are teetering on entering the great beyond. No, I’m afraid there is no way around the fact that humans are squishy, nutritious, and desperately in need of each other. Loneliness is death.
Counterintuitive as it may be, this absolute and unqualified dependence on others doesn’t make cooperation with others all that much easier. This is the lesson of the Prisoner’s Dilemma, that our cooperation and coordination isn’t pre-ordained by need or even optimality. Within a given singular moment it is often in each of our’s best interest to defect on the other, serving our own interests at their expense.
Which isn’t to say that we don’t overcome the Prisoner’s Dilemma every day, constantly, without even thinking about it. Our lived experience, hell, our very survival, is evidence that we have manifested myriad ways to cooperate with others despite our immediate incentives. What distinguishes the different spaces within which we carry out our lives is the manner in which we facilitate these daily acts of cooperation.
Kin
The first and fundamental way to solve the prisoner’s dilemma is to change the payoffs so that each player’s dominant strategy is no longer to defect but instead to cooperate. If you look at the payoff matrix below, the classic problem is that no matter what one player does (Cooperate or Defect), the optimal self-interested response is always to Defect. Before we get into strategies to elicit cooperation, we should start with the most obvious mechanism to evade the dilemma: to care about the outcome experienced by the other. Yes, strong pro-social preferences can eliminate the Prisoner’s Dilemma, but that is a big assumption amongst strangers. Among kin, however, it’s much easier. Family has always been the first and foremost solution. Parents don’t have a prisoner’s dilemma with their children. It doesn’t take a large leap of imagination to see how kin relationships would help familial groups coordinate hunting and foraging or il Cosa Nostra ensuring no one squeals to the cops.
Kinship remains the first solution, but it doesn’t scale. Blood relations dilute fast. I’m confident my brother won’t defect on me. My third-cousin twice removed? Not so much. The reality is that family can only take you so far. If you want to achieve cooperation at scale, if you want to achieve something like the wealth and grandeur of the modern world, you’re going to need strategies and institutions.
Strategies
There are many, if not countless, ways to support cooperation among non-kin. Rather than give an entire course in game theory, I’ll instead just enumerate a few core strategies.
Tit-for-Tat = always copy your opponent’s previous strategy
Grim Trigger = always cooperate until your opponent defects, then never cooperate again
Walk Away = always cooperate, but migrate away from prior defectors to minimize future interaction
The Prisoner’s Dilemma is far, far easier to solve amongst players who can reasonably expect to interact again in the future. The logic underlying all of these strategies is commonly known as The Folk Theorem, which is the broad observation that all cooperation games are far easier to solve, with a multitude of cooperation solutions, if there is i) repeated interaction and ii) an indeterminate end point of future cooperation.
Strategies can facilitate cooperation with strangers, which means we can achieve far greater scale. But not as much as we observe in the modern world, with millions of people contributing to the survival of strangers over vast landscapes and across oceans. For that we’re going to need institutions.
Institutions
Leviathan is simply Thomas Hobbes’ framework for how government solves the Prisoner’s Dilemma. We concentrate power and authority within a singular institution that we happily allow to coerce us into cooperation on the understanding that our fellow citizens will be coerced into cooperating as well. That coercion can force cooperation at scales not previously achievable. It can build roads and raise armies. This scale of cooperation is the wellspring for both some of the greatest human achievements and our absolutely darkest and most heinous sins. Sometimes both at same time.
Governments can achieve tremendous scale, but there remain limits. My mental framing has always been that individual strategies scale linearly (4 people is twice as good as 2 people) and governments scale geometrically (i.e. an infantry’s power is always thrice its number). Geometric scaling is better, but governments always eventually run into the limits of their reach. Coercion becomes clumsy and sclerotic at scale. There’s a reason there has never been a global government, why empires collapse.
Markets can achieve scale unthinkable by governments because their reach is untethered to geography. Markets are networks. They scale exponentially. They solve the prisoner’s dilemma through repeated interaction and reputation. The information contained in prices supports search and discovery processes that both support forming new relationships while also creating sufficient uncertainty about future interactions. Cooperation is a dominant strategy. This scale of cooperation, of course, is not without critical limitations. Absent coercion there is no hope for uniformity or unanimity. No completeness. Public goods requiring uniform commitment or sacrifice are never possible within markets. The welfare of individuals outside of individual acts of cooperation (i.e. externalities) is not weighed in the balance.
There are other institutions that solve the prisoner’s dilemma. Religions, military units, sororities…the list goes forever. This article is already going to be too long, so I’ll start getting to the point. Much of the fundamental disagreement within politics and society at large is what comprises our preferred balance of institutions for supporting and maintaining cooperation, who we want to cooperate with, and the myths we want to tell ourselves about who we are or aren’t dependent on.
The Cooperative Corridor
Wealth depends on cooperation at scale. Wealth brings health and prosperity, but it also brings power. The “cooperation game” might be the common or important game, but it isn’t the only game being played. Wealth can be brought to bear by one individual on another to extract their resources. This is colloquially referred to as “being a jerk”. Perhaps more importantly, groups can bring their wealth to bear to extract the resources from another group. This is colloquially referred to as “warfare”.
Governments are an excellent mechanism for warfare. All due respect to the mercenary armies of history (Landsknechts, Condottieri, etc.), but markets are not well-suited to coordinate attack and defense. Which isn’t to say markets aren’t necessary inputs to warfare. This is, in fact, the rub: governments are good at coordinating resources in warfare, but markets are far better at generating those resources. A pure government society may defeat a pure market society in a war game, but a government-controlled society whose resources are produced via market-coordinated cooperation dominates any society dominated by a singular institution.
This all adds up to what I refer to as the Cooperative Corridor. A society of individuals needs to cooperate to grow and thrive. A culture of cooperation can be exploited, however, by both individuals who take advantage of cooperative members and aggressive (extractive) rival groups. Institutions and individual strategies have to converge on a solution that threads this needle. One answer might appear to be to simply cooperate with fellow in-group members while not cooperating with out-group individuals. This is no doubt the origin of so many bigotries—the belief that you can solve the paradox of cooperation by explicitly defining out-group individuals. Throw in the explicit purging of prior members who fail to cooperate, and you’ve got what might seem a viable cultural solution. The thing about bigotry, besides being morally repugnant, is that it doesn’t scale. The in-group will, by definition, always be smaller than the out-group. Bigotry is a trap. Your group will never benefit from the economies of scale as much as other groups that manage to foster cooperation between as many individuals as possible, including those outside the group.
[SPOILERS AHEAD if you haven’t watched through Episode 6]
You’ve been warned, so here’s the spoilers. An RNA code was received through space, spread across the human species, and now all but a handful of humans are part of a collective hive mind whose consciousnesses have been fully merged. That’s the basic part. The bit that is relevant to our discussion is the revelation that members of the hive mind 1) Can’t harm any other living creature. Literally. They cannot harvest crops, let alone eat meat. 2) They cannot be aggressive towards other creatures, cannot lie to them, cannot it seems even rival them for resources. 3) The human race is going to experience mass starvation as a result of this. Billions will die.
In other words, a cooperation strategy has emerged that spreads biologically at a scale it cannot support. It is also highly vulnerable to predation. If a rival species were to emerge in parallel, it would undermine, exploit, enslave, and eventually destroy it. The whole story borders on a parable of how a species like Homo sapiens could destroy and replace a rival like Homo neanderthalensis.
Cultural strategies are selected within corridors of success. Too independent, you die alone. Too cooperative, you die exploited. Too bigoted, you are overwhelmed by the wealth and power of more cosmopolitan rivals. Too cosmopolitan, you starve to death for failure to produce and consume resources. Don’t make the mistake of thinking the “corridor of success” is narrow or even remotely symmetric, though. On the “infinitely bigoted” to “infinitely cosmopolitan” parameter space, a society is likely to dominate it’s more bigoted rivals with almost any value less than “infinitely cosmopolitan.” So long as members of society are willing to harvest and consume legumes, you’re probably going to be fine (no, this isn’t a screed against vegetarianism, which is highly scalable. Veganism, conversely does have a much higher hurdle to get over…). So long as a group is willing to defend itself from violent expropriation by outsiders, they’re probably going to be fine. Only a sociopathic fool would see empathy as an inherent societal weakness. Empathy, in the long run, is how you win.
How this relates to political arguments
I almost wrote “current political arguments”, but I tend to think disagreements about institutions of cooperation are pretty much all of politics and comparative governance. We’re arguing about instititutions of in-group, out-group, and collective cooperation when we argue about the merits of property rights, regulation, immigration, trade, annexing territory, war. When we confront racism, nationalism, and bigotry, we we are fighting against forces that want to shrink the sphere of cooperation and leverage the resources of the collective to expropriate resources of those confined or exiled to the out-group. These are very old arguments.
The good news is that inclusiveness and cosmopolitanism are economically dominant. They will always produce more resources. But being economically and morally superior doesn’t mean they are necessarily going to prevail. The world is a complex and chaotic system. The pull towards entropy is unrelenting. And, in the case of cultural institutions and human cooperation, the purely entropic state is a Hobbesian jungle of independent and isolated familial tribes living short, brutish lives. Avoiding such outcomes requires active resistance.
In 2025, after mostly feeling too busy for great literature for a few years, I picked up two books that come highly recommended by people with good taste: Middlemarch and Anna Karenina. They are excellent, and they are long. I propose two reasons why they need to be long.
My second reason for long novels:
The second powerful thing about a long novel, if they are written by geniuses like Eliot or Tolstoy, is that you have enough time to see how choices play out over years. You have space to even see the consequences of the consequences. You will experience moral formation from these novels in a way that you just cannot from a 2-hour movie or social media post.
Quick bio of Henry: Henry Oliver writes the popular literary SubstackThe Common Reader, which has been quoted in theAtlantic and elsewhere. His book Second Act, a study of late-blooming talent, was released in 2024.
Lastly, I must thank my sister for engaging me in literature discussion over the Christmas break. She is reading Proust.
Have you ever looked up and wondered where the time went? One moment you’re living your life, and the next moment you realize that you’ve just lost time that you’ll never get back? That’s what happened to Japan’s economy at the turn of the century in an episode that’s known as ‘the lost decades’. It was a period of slow or null economic growth. Economists differ with their explanations. One cause was the prevalence of ‘zombie firms’.
Japan’s Economy
Japan had a current account surplus from 1980-2020, which means that they had more savings than they effectively utilized domestically. Metaphorically, they were so full of savings that they exhausted productive domestic investment opportunities and their savings spilled out into other counties in the form of foreign investments. This was driven by high household savings and slow growth in domestic investment demand. The result was the Japanese firms had easy access to credit. Maybe a little too easy…
Private corporate debt ballooned throughout the 1980s. That’s not intrinsically a problem. In the 1990s, households began saving somewhat less, and most firms began to drastically deleverage… But not all firms. The net effect of the mass deleveraging was that interest rates fell. The firms that remained in debt were the ones that risked insolvency. Less productive firms had slim profits and their Earnings Before Interest, Taxes, Depreciation, and amortization (EBITDA) was slim. So slim, that they couldn’t pay their debts. Faced with the prospect of insolvency, firms did what was sensible. They refinanced at the lower interest rates. Firms went to their banks and to bond markets and rolled over their debt, which they couldn’t afford, and replaced it with debt that had a lower interest rate. This occurred across industries, but especially in non-tradable goods and services that were insulated from international competition. Crisis averted.
Except this process of refinancing, while avoiding acute defaults and a potential financial crises, ensured that the less productive firms would survive. Not exactly failing and not exactly thriving, they could sort of just hold on to something that looks like life. Well, high debt and low profits aren’t much of a life for a firm. It’s more like being undead – like a zombie. Between 1991 and 1996, the share of non-finance firm assets held by zombie firms ballooned from 3% to 16%. The run-up differed by industry: Manufacturing zombie assets rose from 2% to 12%, from 5% to 33% in real estate, and from 11% to 39% in services. These zombie firms linger on, tying up valuable resources with low-productivity activities and drag on the economy.
China’s Economy
I’m not prone to China hysteria generally. However, I do have uncertainty about the plans and actions of the Chinese government because I don’t know that domestic economic welfare is its priority. That makes forecasting more political and less economic and outside my expertise. Regardless, the Chinese economy is a constraint on the government, whether they like it or not. And there are some echoes of the Japanese economy’s lost decades.
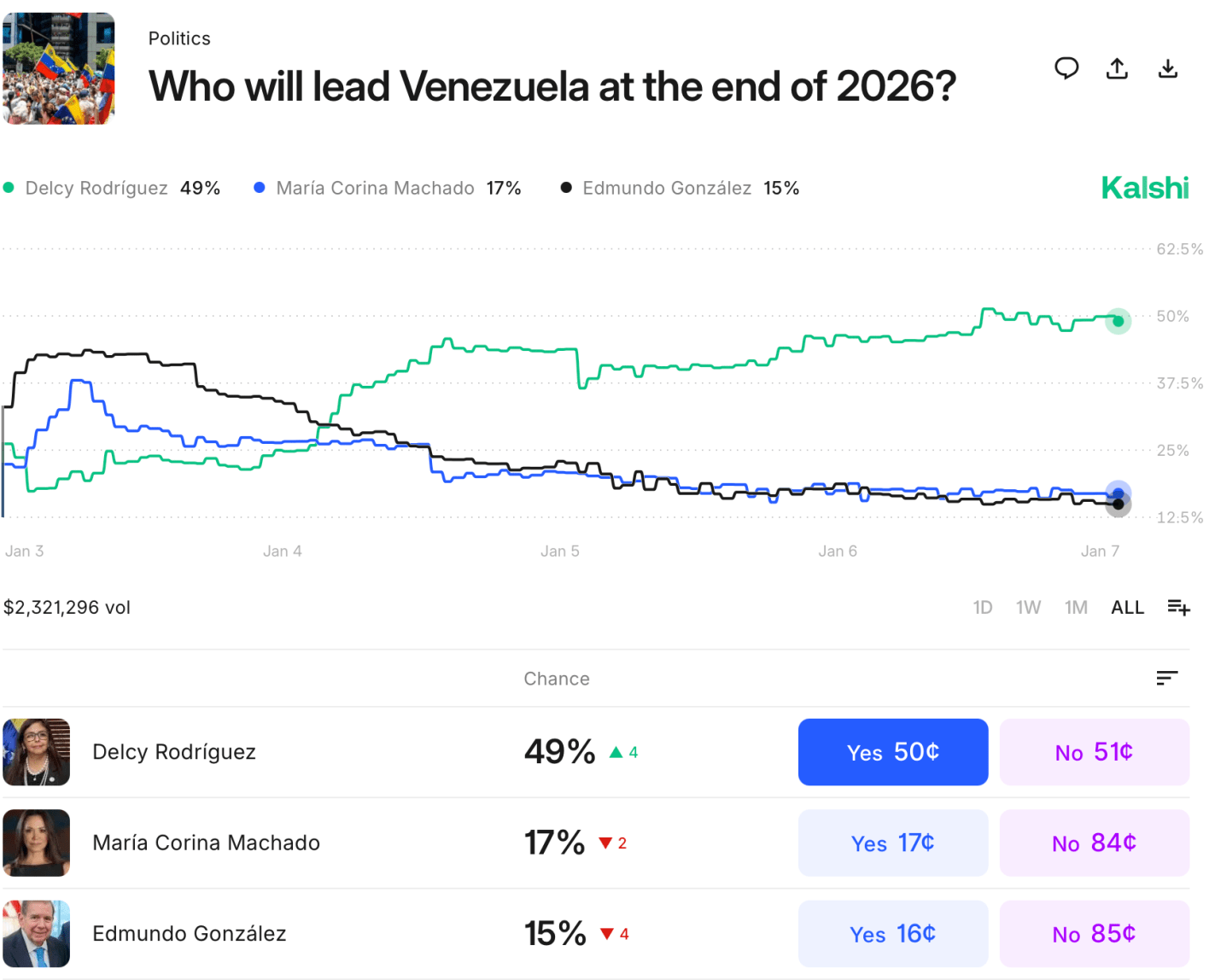
Venezuela held an election this week; President Maduro says he won, while the opposition and independent observers say he lost. Disputed elections like this are fairly common across the world, but where Venezuela really stands out is not how people vote at the ballot box- it is how they vote with their feet.
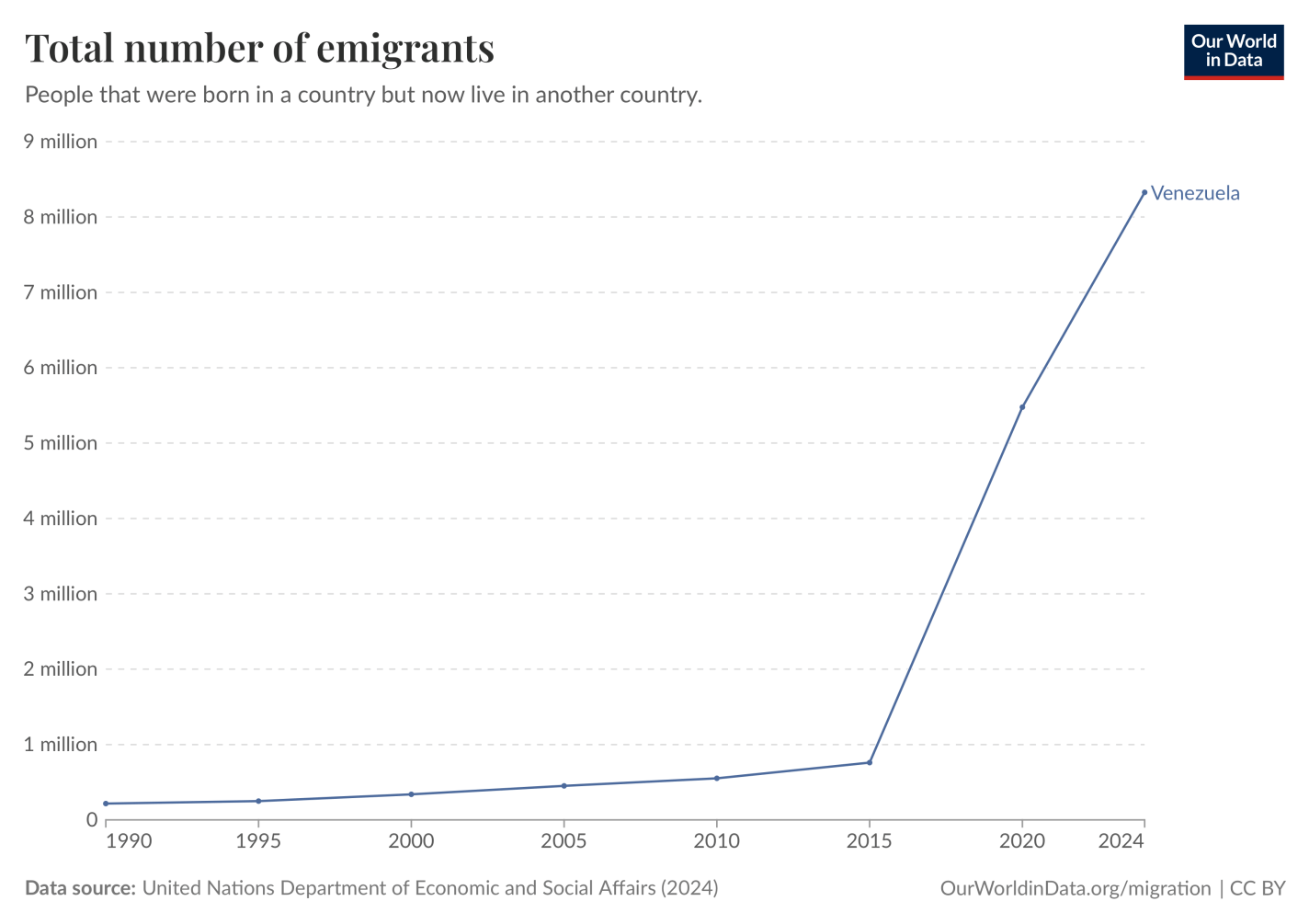
Reuters notes that “A Maduro win could spur more migration from Venezuela, once the continent’s wealthiest country, which in recent years has seen a third of its population leave.”
This makes Venezuela the largestrefugee crisis in the history of the Americas, and depending on how you count the partition of India, perhaps the largest refugee crisis in human history that was not triggered by an invasion or civil war.
Instead, it has been triggered by the Maduro regime choosing terrible policies that have needlessly and dramatically impoverished the country
Plus some foreshadowing:
I hope that the Venezuelan government will soon come to represent the will of its people. I’m not sure how that is likely to happen, though I guess positive change is mostly likely to come from Venezuelans themselves (perhaps with help from Colombia and Brazil); when the US tries to play a bigger role we often make things worse. But what has happened in Venezuela for the past 10 years is clearly much worse than the “normal” bad economic policies and even democratic backsliding that we see elsewhere.
Here’s an update on the chart I shared then, showing that the diaspora has continued to swell:
I hope that Venezuela will soon become the sort of country people don’t want to flee. I don’t necessarily expect that it will, but it’s not now a crazy hope: