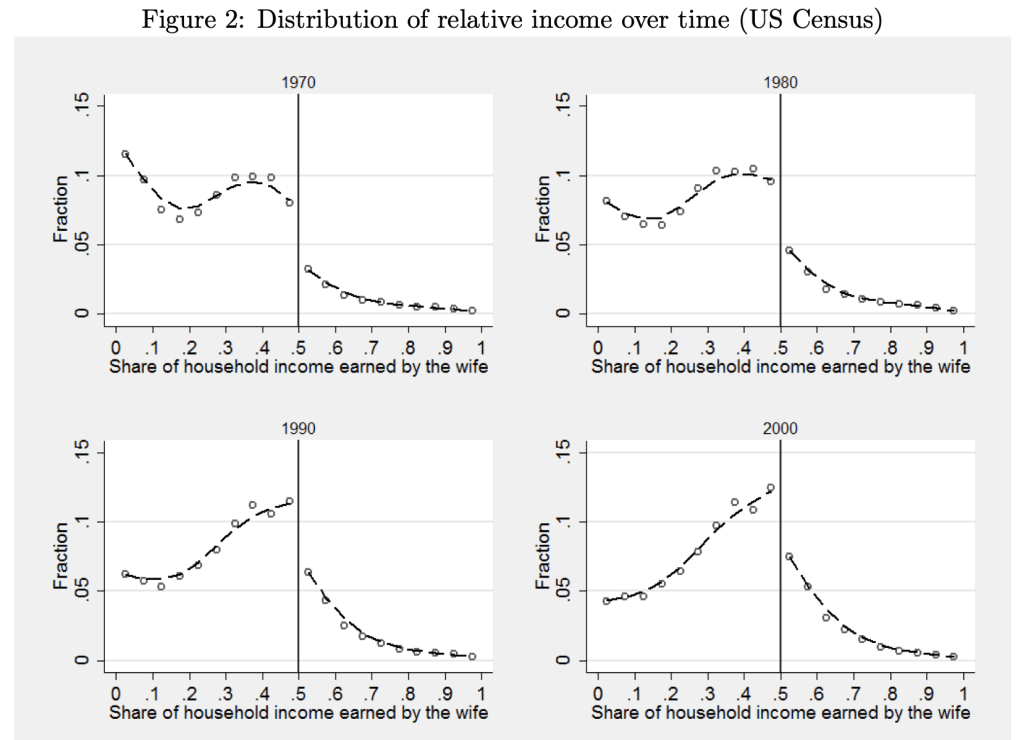
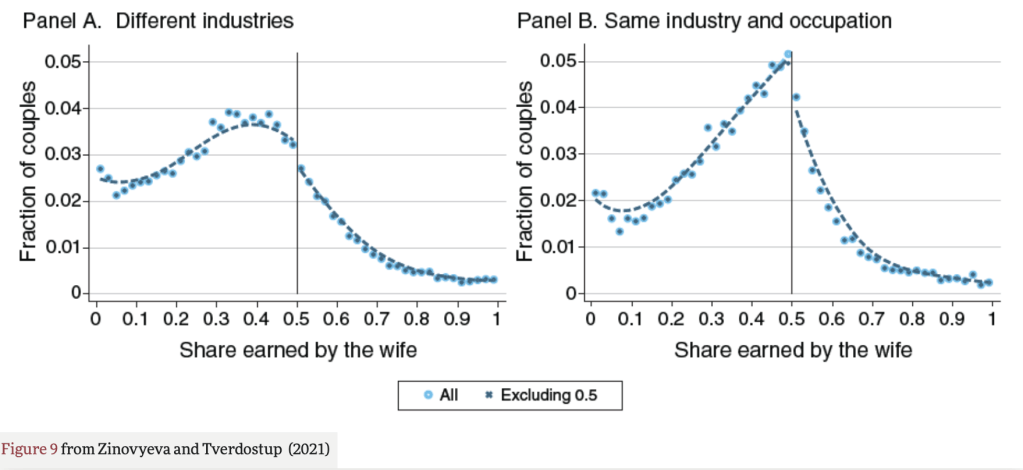
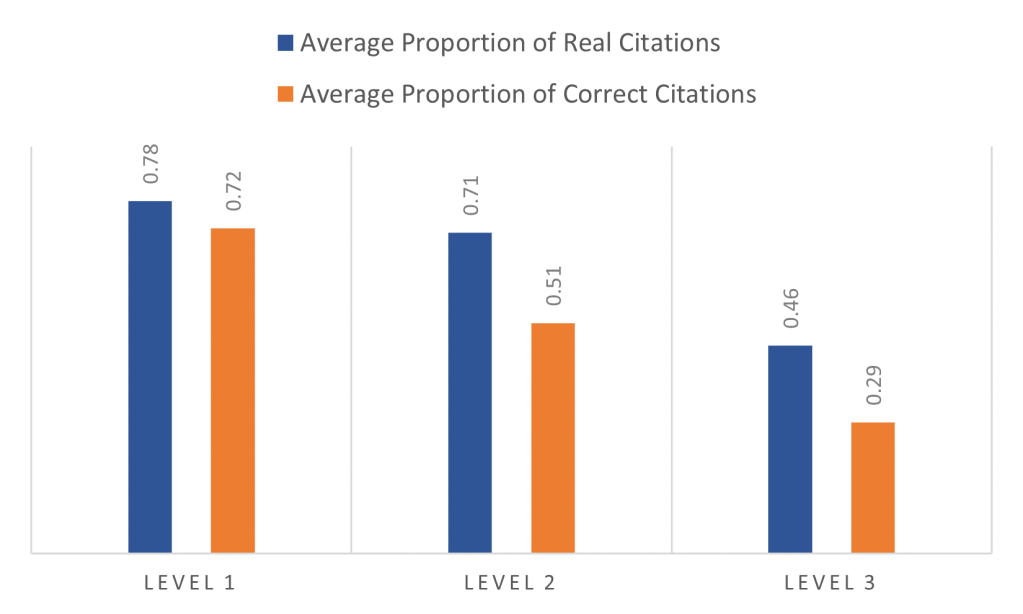
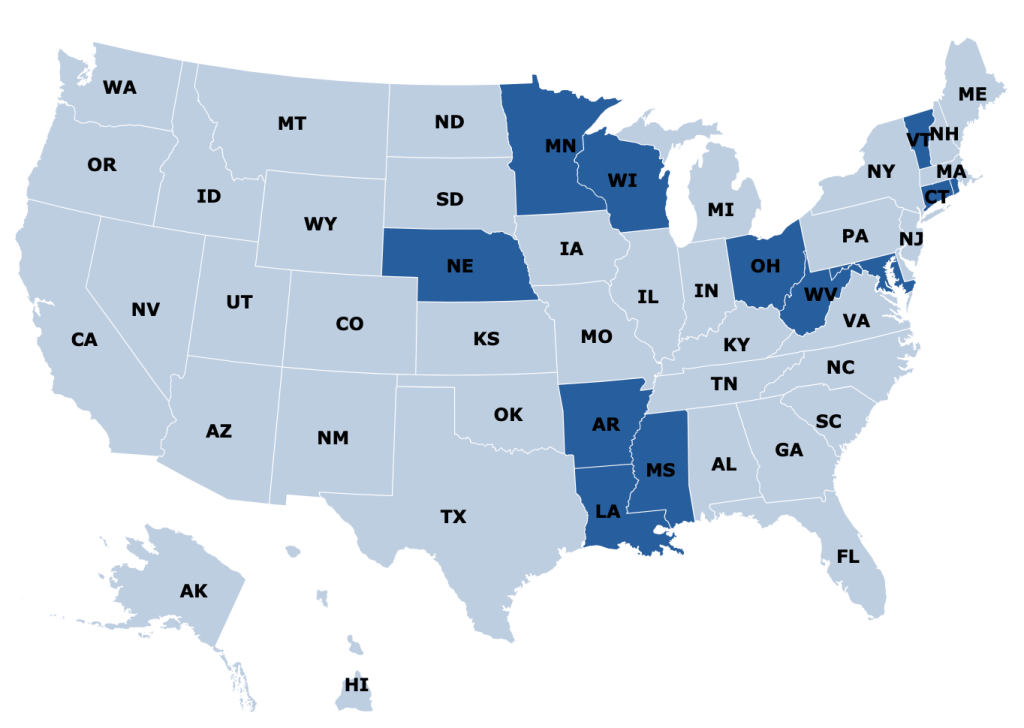
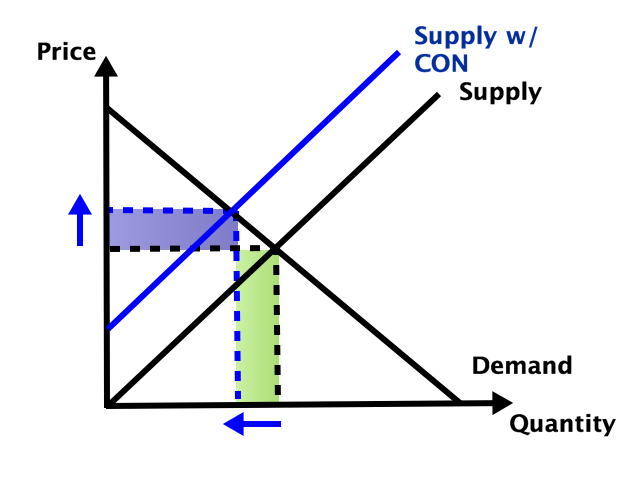
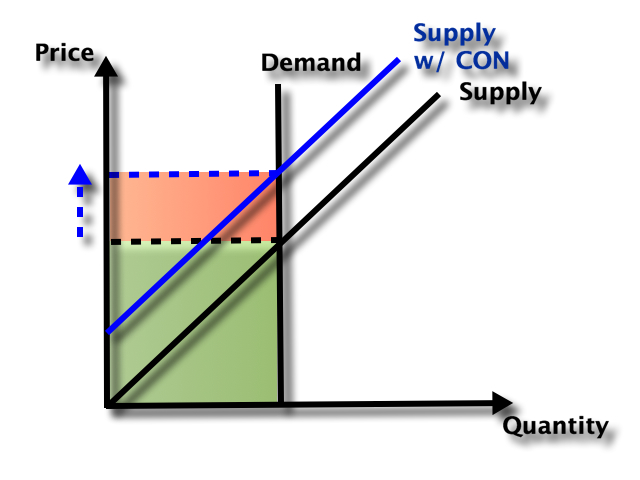
If a scientific finding is really true and important, we should be able to reproduce it- different researchers can investigate and confirm it, rather than just taking one researcher at their word.
Economics has not traditionally been very good at this, but we’re moving in the right direction. It is becoming increasingly common for researchers to voluntarily post their data and code, as well as for journals (like the AEA journals) to require them to:
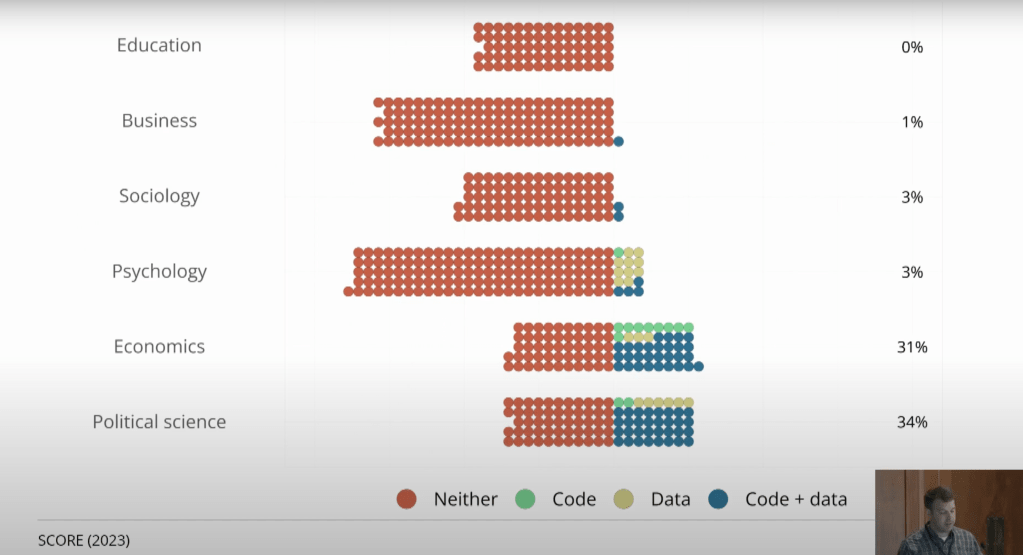
This has certainly been the trend with my own research; if you look at my first 10 papers (all published prior to 2018) I don’t currently share data for any of them, though I hope to go back and add it some day. But of my most recent 10 empirical papers, half share data.
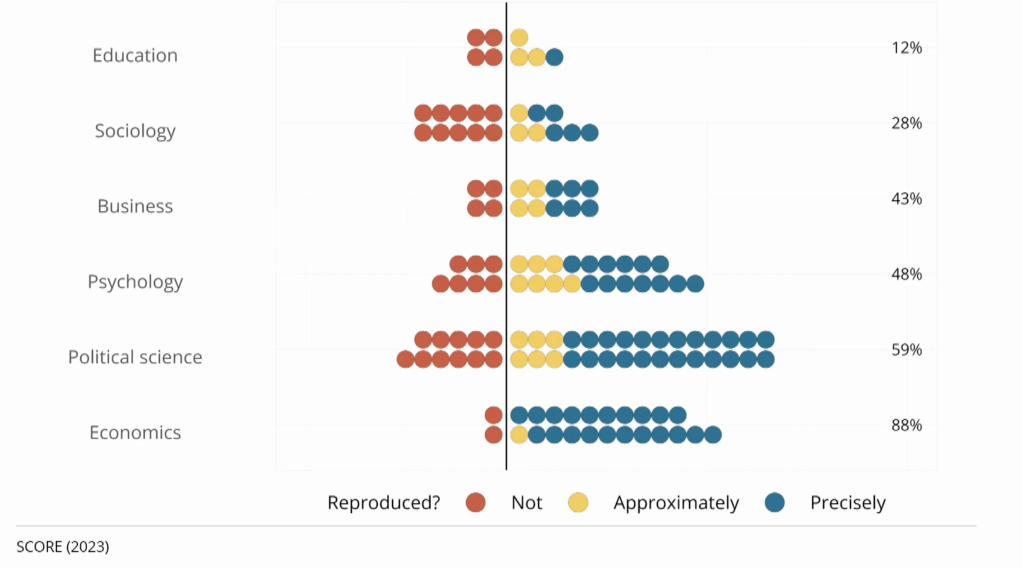
This sharing allows other researchers to easily go back and check that the work is accurate. This could mean simply checking that it is “reproducable”, i.e., that running the original code on the original data produces the results that the authors said. Or it could mean the more ambitious “replicability”, i.e., you could tackle the same question with different data and still find basically the same answer. Economics does generally does well at reproducability when code is shared, but just ok at replication.
Of course, even when data and code are shared, you still need people to actually do the double-checking research; this is still relatively rare because it is harder to publish replications than original research. But more replication journals are opening, and there are now several projects funding replications. The trends are all in the right direction to establish real, robust findings, with one exception- the rise of restricted data.
Traditionally most economics research has been done using publicly available datasets like the Current Population Survey. But an increasing proportion, perhaps a majority of research at top journals, is now done using restricted datasets (there’s a great graph on this I can’t find but see section 3.3 here). These datasets legally can’t be shared publicly, either due to privacy concerns,licensing agreements, or both. But journals almost always still publish these articles and give them an exemption to the data sharing requirement. One the one hand it makes sense not to ignore this potentially valuable research when there are solid legal reasons the data can’t be shared. But it does mean we can’t be as confident that the data has been analyzed correctly, or that it even really exists.
One potential solution is to find people who have access to the same restricted dataset and have them do a replication study. This is what the Institute for Replication just started doing. They posted a list of 100+ papers that use restricted data that they would like to replicate. They are offering $5000 for replications of most of the papers, so I think it is worthwhile for academics to look and see if you already have access to relevant datasets, or if you study similar enough things that it is worth jumping through the hoops to get data access.
For everyone else, this is just one more reason not put too much trust in any one paper you read now, but to recognize that the field as a whole is getting better and more trustworthy over time. We will be more likely to catch the mistakes, purge the frauds, and put forward more robust results that at least bear a passing resemblance to what science can and should be.