Nvidia is a huge battleground stock – – some analysts predict its price will languish or crash, while others see it continuing its dramatic rise. It has become the world’s most valuable company by market capitalization. Here I will summarize the arguments of one bear and one bull from the investing site Seeking Alpha.
In this corner…semi-bear Lawrence Fuller. I respect his opinions in general. While the macro prospects have turned him more cautious in the past few months, for the past three years or so he has been relentlessly and correctly bullish (again based on macro), when many other voices were muttering doom/gloom.
Fuller’s article is titled Losing Speed On The AI Superhighway. This dramatic chart supports the case that NVDA is overvalued:
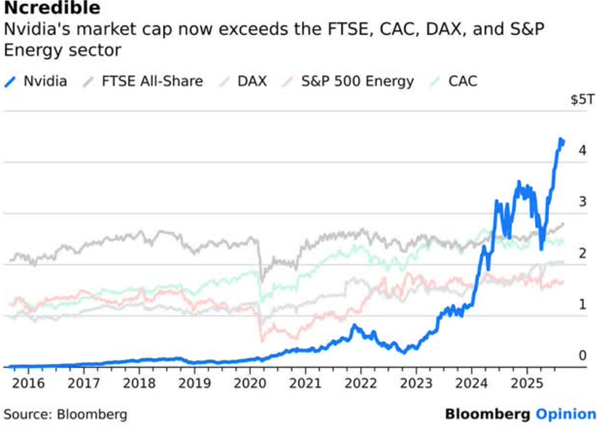
This chart shows that the stock value of Nvidia has soared past the value of the entire UK stock exchange or the entire value of US energy companies. Fuller reminds us of the parallel with Cisco in 2000. Back then, Cisco was a key supplier of gateway technology for all the companies scrambling to get into this hot new thing called the internet. Cisco valuation went to the moon, then crashed and burned when the mania around the internet subsided to a more sober set of applications. Cisco lost over 70% of its value in a year, and still has not regained the share price it had 25 years ago:
… [Nvidia] is riding a cycle in which investment becomes overinvestment, because that is what we do in every business cycle. It happened in the late 1990s and it will happen again this time.
…there are innumerable startups of all kinds, as well as existing companies, venturing into AI in a scramble to compete for any slice of market share. This is a huge source of Nvidia’s growth as the beating heart of the industry, similar to how Cisco Systems exploded during the internet infrastructure boom. Inevitably, there will be winners and losers. There will be far more losers than winners. When the losers go out of business or are acquired, Nvidia’s customer base will shrink and so will their revenue and earnings growth rates. That is what happened during the internet infrastructure booms of the late 1990s.
Fuller doesn’t quite say Nvidia is overvalued, just that it’s P/E is unlikely to expand further, hence any further stock price increases will have to be produced the old-fashioned way, by actual earnings growth. There are more bearish views than Fuller’s, I chose his because it was measured.
And on behalf of the bulls, here is noob Weebler Finance, telling us that Nvidia Will Never Be This Cheap Again: The AI Revolution Has Just Begun:
AI adoption isn’t happening in a single sequence; it’s actually unfolding across multiple industries and use cases simultaneously. Because of these parallel market build-outs, hyper-scalers, sovereign AI, enterprises, robotics, and physical AI are all independently contributing to the infrastructure surge.
…Overall, I believe there are clear signs that indicate current spending on AI infrastructure is similar to the early innings of prior technology buildouts like the internet or cloud computing. In both those cases, the first waves of investment were primarily about laying the foundation, while true value creation and exponential growth came years later as applications multiplied and usage scaled.
As a pure picks and shovels play, Nvidia stands to capture the lion’s share of this foundational build-out because its GPUs, networking systems, and software ecosystem have become the de facto standard for accelerated computing. Its GPUs lead in raw performance, energy efficiency, and scalability. We clearly see this with the GB300 delivering 50x per-token efficiency following its launch. Its networking stack has become indispensable, with the Spectrum-X Ethernet already hitting a $10b annualized run rate and NVLink enabling scaling beyond PCIe limits. Above all, Nvidia clearly shows a combined stack advantage, which positions it to become the dominant utility provider of AI compute.
… I believe that Nvidia at its current price of ~$182, is remarkably cheap given the value it offers. Add to this the strong secular tailwinds the company faces and its picks-and-shovels positioning, and the value proposition becomes all the more undeniable.
My view: Out of sheer FOMO, I hold a little NVDA stock directly, and much more by participating in various funds (e.g. QQQ, SPY), nearly all of which hold a bunch of NVDA. I have hedged some by selling puts and covered calls that net me about 20% in twelve months, even if stock price does not go up. Nvidia P/E (~ 40) is on the high side, but not really when considering the growth rate of the company. It seems to me that the bulk of the AI spend is by the four AI “hyperscalers” (Google, Meta, Amazon, Microsoft). They make bazillions of dollars on their regular (non-AI) businesses, and so they have plenty of money to burn in purchasing Nvidia chips. If they ever slow their spend, it’s time to reconsider Nvidia stock. But there should be plenty of warning of that, probably no near time crisis: last time I checked, Nvidia production was sold out for a full year ahead of time. I have no doubt that their sales revenue will continue to increase. But earnings will depend on how long they can continue to command their stupendous c. 50% net profit margin (if this were an oil company, imagine the howls of “price gouging”).
As usual, nothing here should be considered advice to buy or sell any security.