I’ve praised IPUMS before. It’s great.
The census data in particular is vast and relatively comprehensive. But, it’s not all perfect.
Consider three variables:
- Labforce, which categorizes whether someone is employed
- Occ1950, which categorizes occupation types
- Edscor50, which imputes a relative education score based on occupation
These all seem like appropriate variables that a labor economist might want to control for when explaining any number of phenomena. There is a problem. Edscor50, and the several measures like it, are occupation based. Specifically, the scores use details about 1950 occupations to impute educational details. There are similar indices used for earnings, income, status, socioeconomic status, and prestige.
Cool.
But who has occupations? Apparently, historical census interviewers differed in opinion. Sometimes, people who didn’t work were categorized as having no occupation. Other times, they were considered to have an occupation, but simply not be employed. Whether one is in employed or has an occupational category can be reduced to binary cases, implying four possible cases. Inconveniently, the data do not reveal a standard for data recording.
Labforce is not truly a binary variable because it could also be missing a value. Regardless of employment status, the data lists some edscor50 observations as missing. See the table below.
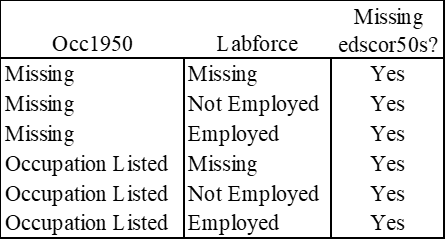
Why does this matter?
The issue of missing values matters because regressions can’t have missing values. There are some ways to get around missing values with regression analysis, but they are sketchy. What should one do here? It really depends on the purpose of the analysis, but some problems can be identified.
First, one could focus on only those people with occupations. As it turns out, missing an occupation category results in a missing edscor50 in 100% of cases. Unfortunately, in a year like 1850, that’s about 70% of all data. It would also exclude plenty of people who are gainfully employed and simply didn’t record a response for occupation. As with all things in life, there are trade-offs. Eliminating all individuals without a listed occupation only affects 0.003% of those who are employed. Biases are always introduced when we omit observations, but such a small amount of data is unlikely to throw off regression results much at all. It seems like a very tolerable rate of data loss to make this problem go away.
But the problem doesn’t go away. Even among people who have an occupation listed, there are still some missing education scores. We can start talking about dropping individuals with missing edscor50s. That’s only 0.15% of employed people, so NBD on that front. But, there are on the order of 28% of unemployed people who can be said to specialize in one occupation or another, who are also missing an educational score. That’s substantial. Similarly, though less jarring, about 9% of people with unknown employment status are missing an educational score. After that, we would really need to dig into the weeds. Like, does it matter that those missing values all occur for individuals who are under the age of 18?
What a big ol’ messy mess.
Why does the exercise matter? It matters because economists are employed by a plethora of for-profits, NGOs, and government agencies. We’re unique in that we have a useful overlap of valuable human capital. We can do stats, math, logic, and sometimes even communicate clearly. People depend on the work that economists do in order to make policy and important life decisions. We’re not oracles or superheroes. We’re just people. And people doing data analysis need to make many, many decisions when they are cleaning their data or specifying a model. Plenty of choices seem like a coin flip. Which is kind of awkward when so people depend on you. Like, what if you had made a different data cleaning decision? Would that have thrown the results in a different direction? It’s hard to say. We can check every case, but there are a whole lot of cases. I think most of us do what we can to make sense of the world. But there is plenty of lounging area for personal biases to assert themselves.
It’s understandable that so many people don’t care what the data says. Most of us seem to get along just fine with poor conceptions of reality. So why invest the effort? Especially when we can criticize each and every data cleaning decision. For most people, the cost-benefit analysis of caring just doesn’t make sense. I’m tempted to say ‘thank goodness we have nerdy economists who care!’. But, to be entirely honest, it’s not clear to me that all of our data work is used well. We could probably get similar policy results with many fewer resources invested into the statistical work.
