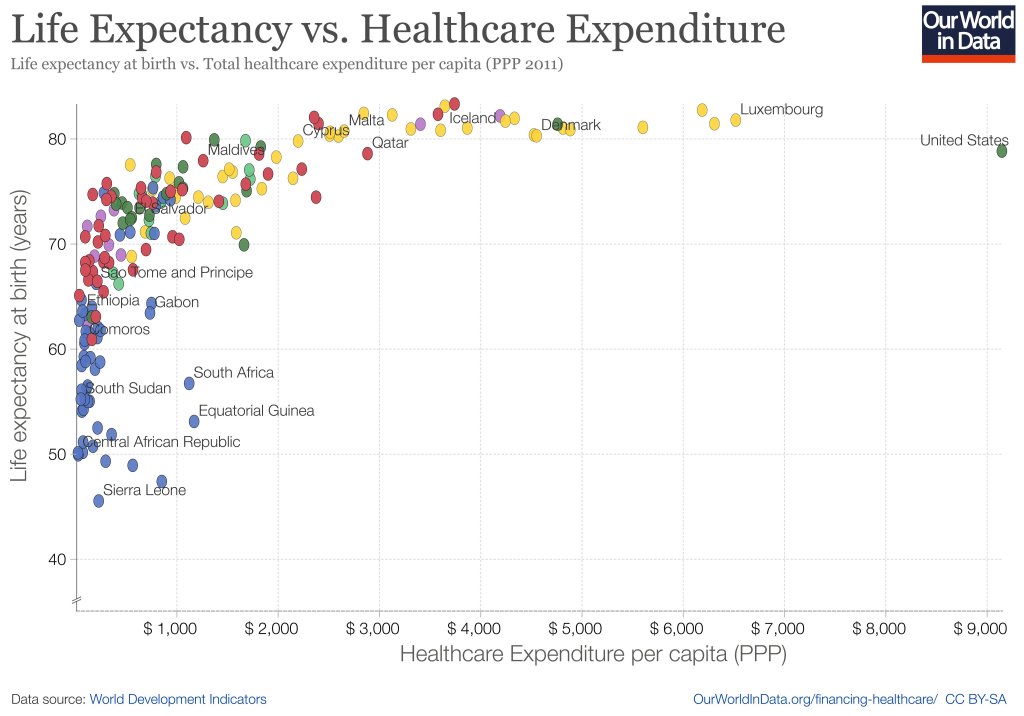
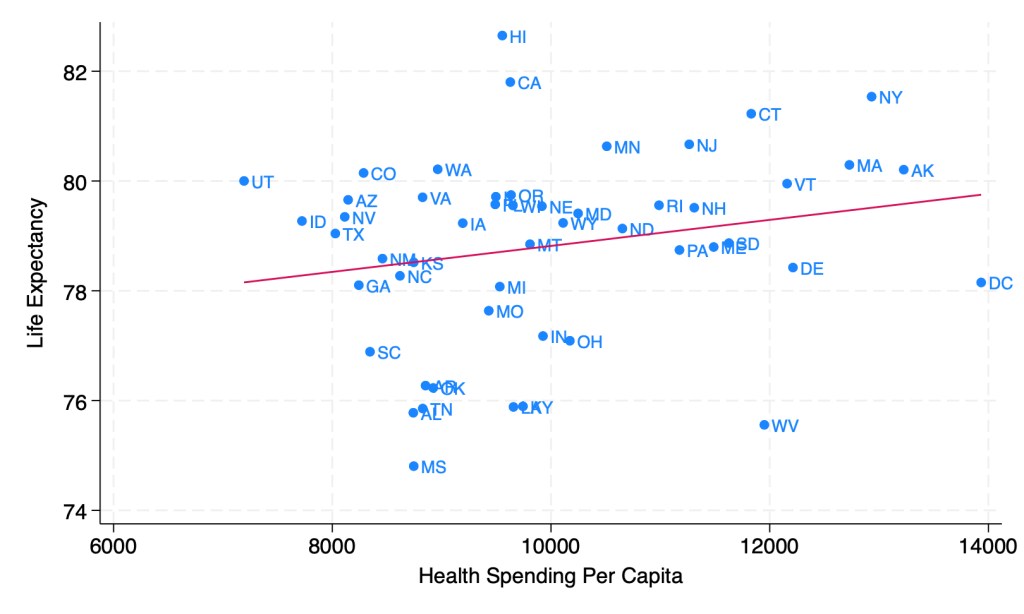
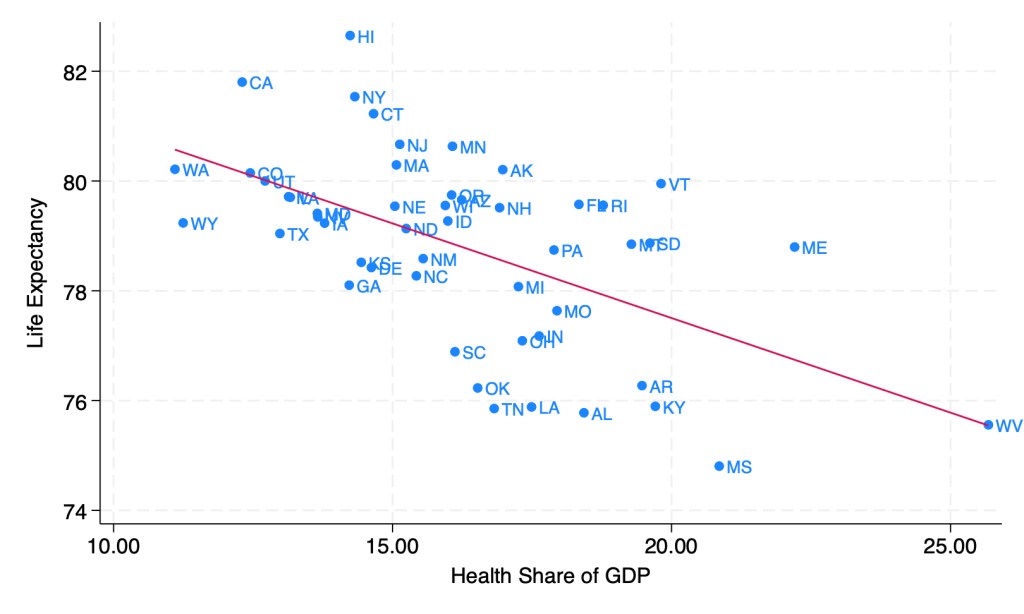
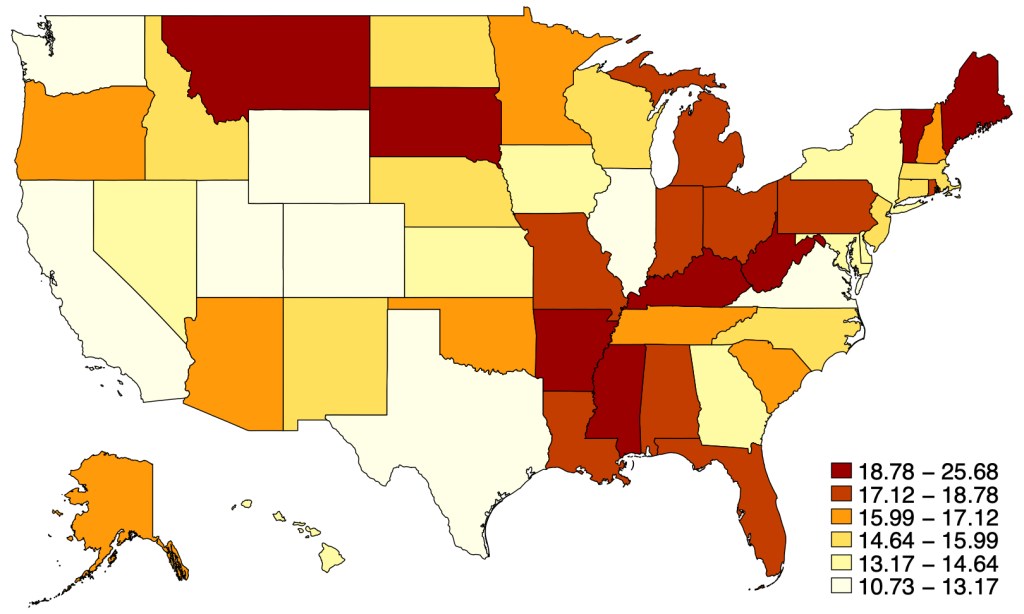
Everyone else keeps asking when the Fed will cut rates, and yesterday Chair Powell said they will likely cut this year. Either they are all crazy or I am, because almost every indicator I see indicates we are still above the Fed’s inflation target of 2% and are likely to remain there without some change in policy. Ideally that change would be a tightening of fiscal policy, but since there’s no way Congress substantially cuts the deficit this year, responsibility falls to the Federal Reserve.

Lets start with the direct measures of inflation: CPI is up 3.1% from a year ago. The Fed’s preferred measure, PCE, is up 2.4% from a year ago. Core PCE, which is more predictive of where inflation will be going forward, is up 2.8% over the past year. The TIPS spread indicates 2.4% annualized inflation over the next 5 years. The Fed’s own projections say that PCE and Core PCE won’t be back to 2.0% until 2026.
The labor market remains quite tight: the unemployment rate is 3.7%, payroll growth is strong (353,000 in January), and there are still substantially more job openings than there are unemployed workers. The chattering classes underrate this because they are in some of the few sectors, like software and journalism, where layoffs are actually rising. Real GDP growth is strong (3.2% last quarter), and nominal GDP growth is still well above its long-run trend, which is inflationary.
I do see a few contrary indicators: M2 is still down from a year ago (though only 1.4%, and it is up over the past 6 months). The Fed’s balance sheet continues to shrink, though it is still trillions above the pre-Covid level. Productivity rose 3.2% last quarter.
But overall I am still more worried about inflation than about a recession, as I was 6 months ago. Financial conditions have changed dramatically from a year ago, when the discussion was about bank runs and a near-certain recession. Today the financial headlines are about all time highs for Bitcoin, Gold, Japan, and US stocks, with an AI-fueled boom (bubble?) in tech pushing the valuation of a single company, Nvidia, above the combined valuation of the entire Chinese stock market. All of this screams inflation, though it could also indicate a recession in a year or so if the bubble pops.
At least over the past year I think fiscal policy is more responsible than monetary policy for persistent inflation. But I can’t see Congress doing a deficit-reducing grand bargain in an election year; the CBO projects the deficit will continue to run over 5% of GDP. That means our best chance for inflation to hit the target this year is for the Fed to tighten, or at least to not cut rates. If policy continues on its current inflationary path, our main hope is for a deus-ex-machina like a true tech-fueled productivity boom, or deflationary events abroad (recession in China?) lowering prices here.