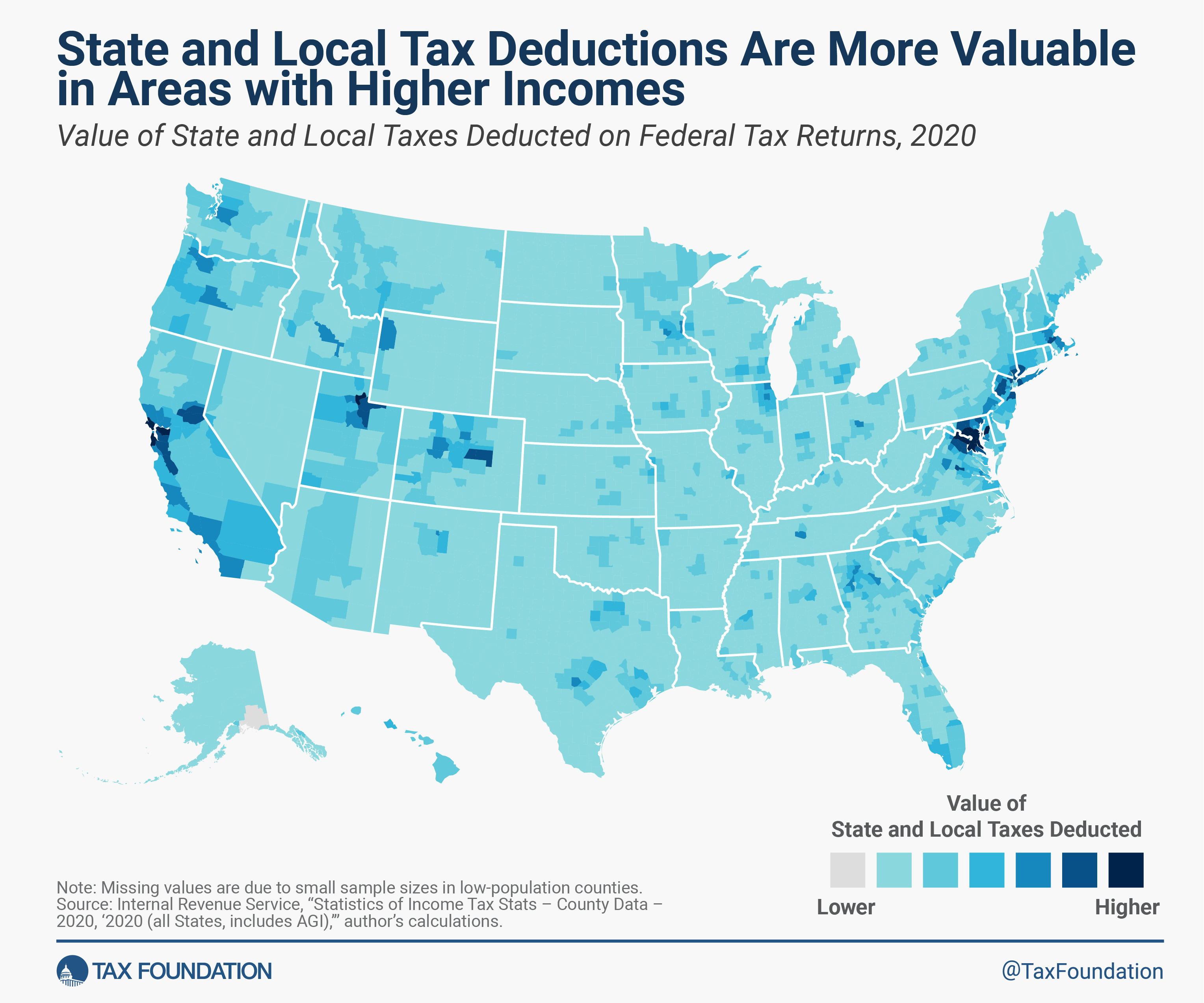
In macroeconomics we have basic tools to help us talk about economic growth, which is simply the percent change in RGDP per capita. What causes growth? Lot’s of things. All else constant, if more people are employed, then more will be produced. But the productivity of those workers matters too. That’s why we calculate average labor productivity (ALP), which is the GDP per worker. This tells us how much each worker produces. All else constant, more ALP means more GDP.*
What affects ALP? Nearly everything: Technology, demographics, health, culture, and public policy. Most of these have long-term effects. So, it’s better to think in terms of regimes. After all, incurring debt now can result in a lot of investment and production, but there’s no guarantee that it can be sustained year after year. This is why I don’t get terribly excited about individual good or bad policies at any moment. There’s a lot of ruin in a nation. I care more about the long-run policy regime that is fostered over time.
Given the variety of inputs to economic growth, there’s always plenty of room for complaint about policy – even if the economy is doing well. In this post, I’m inspired by a Youtube video that a student shared with me. The OP laments poor policy in Massachusetts. But compared to some other nearby states, MA is doing just fine economically. This is not the same as saying that the OP is wrong about poor policies. Rather, a regime of policy, technology, interests, etc. is built over time and there can be a lot wrong in growing economies.
In the interest of being comprehensive, this post includes basic growth stats for all states from 2005 through 2024 (the years of FRED-state GDP).** First, let’s start with the basic building blocks of population, employment, and RGDP. Institutions matter. Policy affects whether people migrate to/from the state, fertility, how many people are employed, and what they can produce.
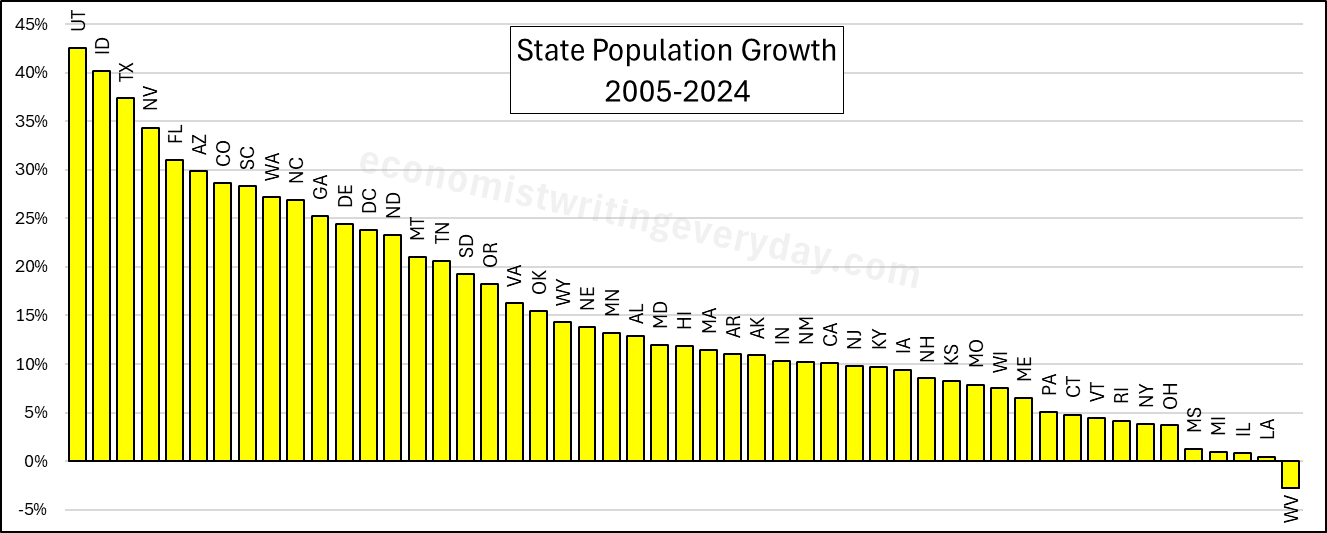
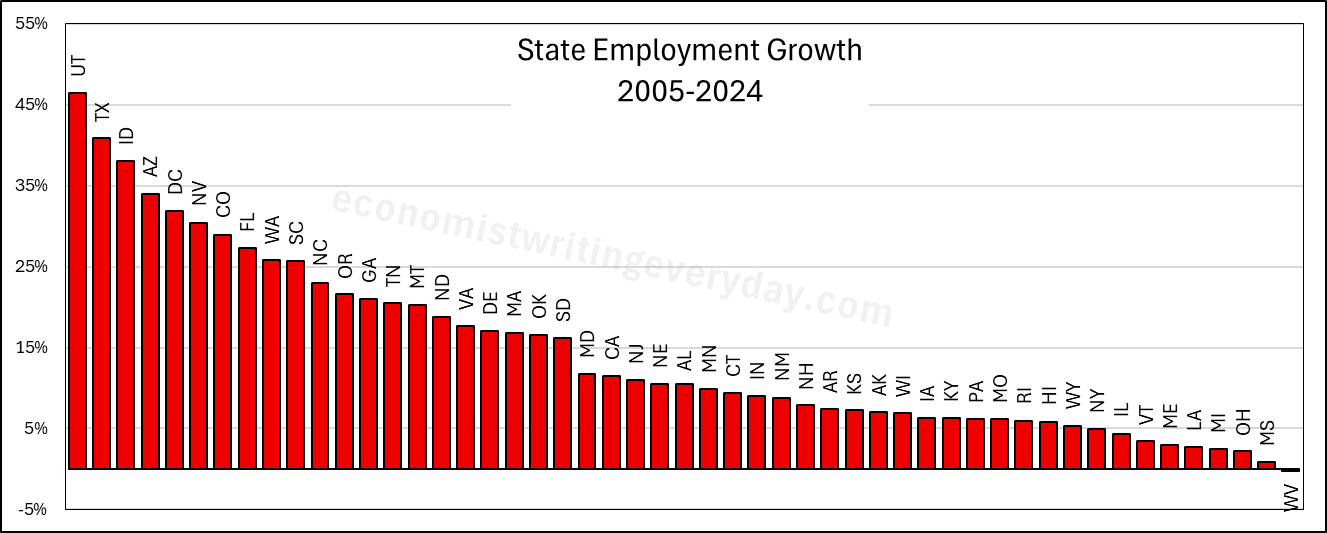
People like to talk about migration and the flocking to Texas & Florida. But that fails to catch the people who choose to stay in their state. Utah is 43% more populous than it was 20 years ago. But you don’t hear much clamoring for their state policies. Idaho and Nevada also beat Florida in terms of percent change. Where are the calls to be like Idaho? Employment largely tracks population, though not perfectly. The RGDP numbers can change quickly with commodity prices, reflected in the performance of North Dakota. But remember, these numbers cover a 20 year span. So, any one blockbuster or dower year won’t move the rankings much.

Of course, these figures just set the stage. What about the employment-population ratio, ALP, and RGDP per capita? Read on.
Continue reading