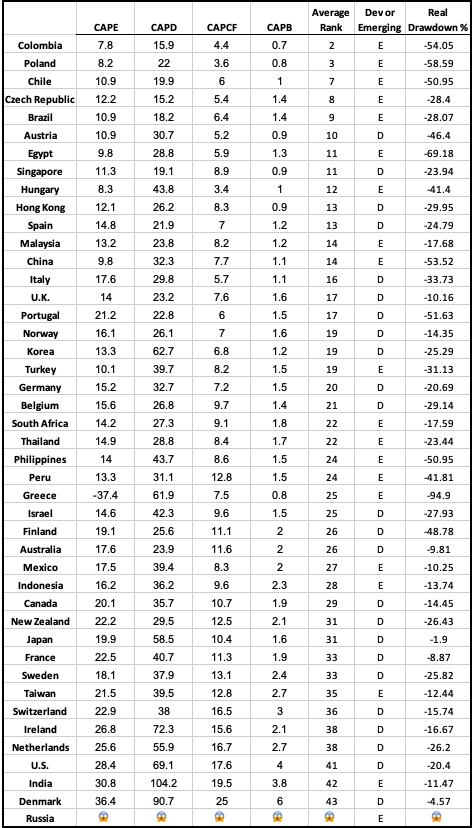
The latest Global Valuation update this week shows that Poland (along with Colombia) has some of the world’s cheapest stocks. Their overall Price to Earnings ratio is 8, compared to 28 for the US:

Does this mean Polish stocks are a good deal, or that investors are rationally discounting them as being risky or slow-growing? After all, they had a low P/E ratio last time I wrote about them too.
Stocks can rise either based on higher investor expectations (higher P/Es) or improved fundamentals (earnings rise, investors see this and bid up the price, but only enough to keep the P/E ratio roughly constant). Over the past year Polish stocks have done the latter; I bought EPOL (the only ETF I know of that focuses Poland) a year ago because its P/E was about 6. Since then its up 70% and the P/E is still… about 6.
Why haven’t investors been excited enough about this earnings growth to bid up the valuation? I think the biggest concern has been political risk, given that the ruling Law and Justice party has been alienating the EU and arguably undermining the rule of law and finding pretexts to arrest businessmen critical of the government.
The recent Polish election promises to change all this. A coalition of ‘centrist’ opposition parties won enough votes to oust the current government, and Washington, the EU, and business seem relieved:
As Europe’s sixth-largest economy, a revitalised pro-EU attitude in Poland would be particularly welcome.
“It will be a positive development for sure because it will unlock the (EU) money that has been withheld and reduce a lot of the tension that has been created with Brussels,” said Daniel Moreno, head of emerging markets debt at investment firm Mirabaud.
Some 110 billion euros ($116 billion) earmarked for Poland from the EU’s long-term budget and the post-pandemic Recovery and Resilience Facility (RRF) remain frozen due to PiS’ record of undercutting liberal democratic rules.
The case for optimism is an influx of EU funds, less risk for business, and an appetite for higher valuations among Western investors who no longer dislike the government.
Being an economist I also have to give you the “other hand”, the case for pessimism: the new government hasn’t actually formed yet, meaning the current one still has the chance for shenanigans; population growth has been strong recently with the influx of Ukrainian refugees, but it is likely to go negative again soon; and EPOL is almost half financial services, which have relatively low P/E even in the US right now.
Nothing is guaranteed but this is my favorite bet right now. I find it amusing that this “risky” emerging market has had a great year while “safe” US Treasury bonds are having a record drawdown (easy to be amused when I don’t own any long bonds and they have done surprisingly little damage in terms of blowing up financial institutions so far). I emphasize the investing angle here but hopefully this signals a bright future for the Polish people.
Disclaimers: Not investment advice, I’m talking my book (long EPOL), I’ve never been to Poland and I’m judging their politics based on Western media reports