By now, everyone should consider using ChatGPT and be familiar with how it works. I’m going to highlight resources for that.
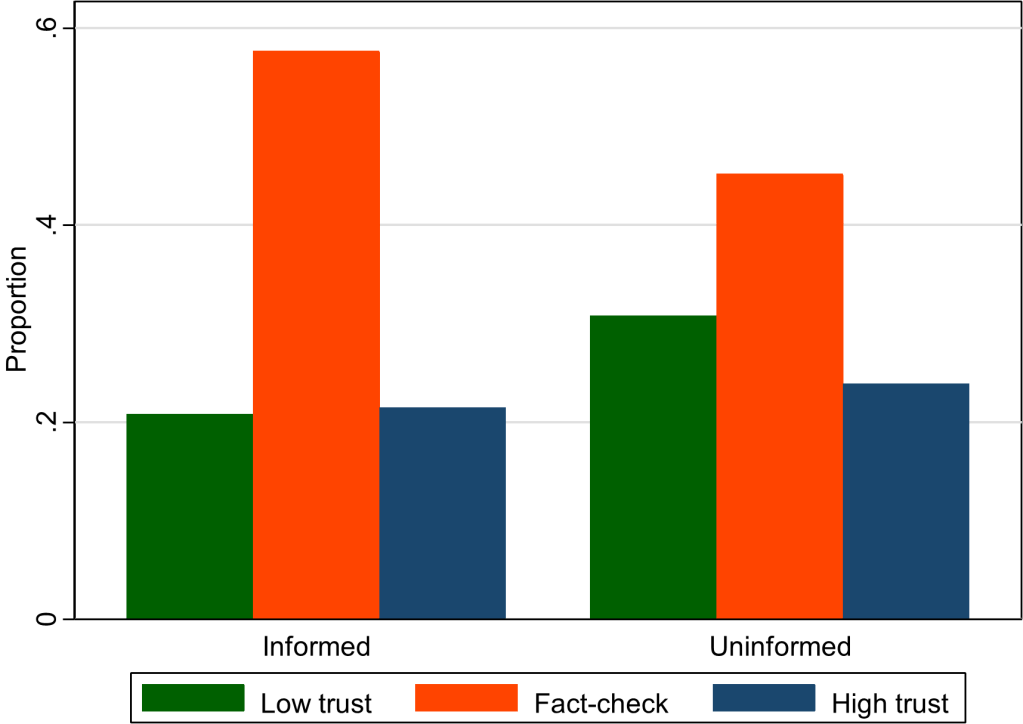
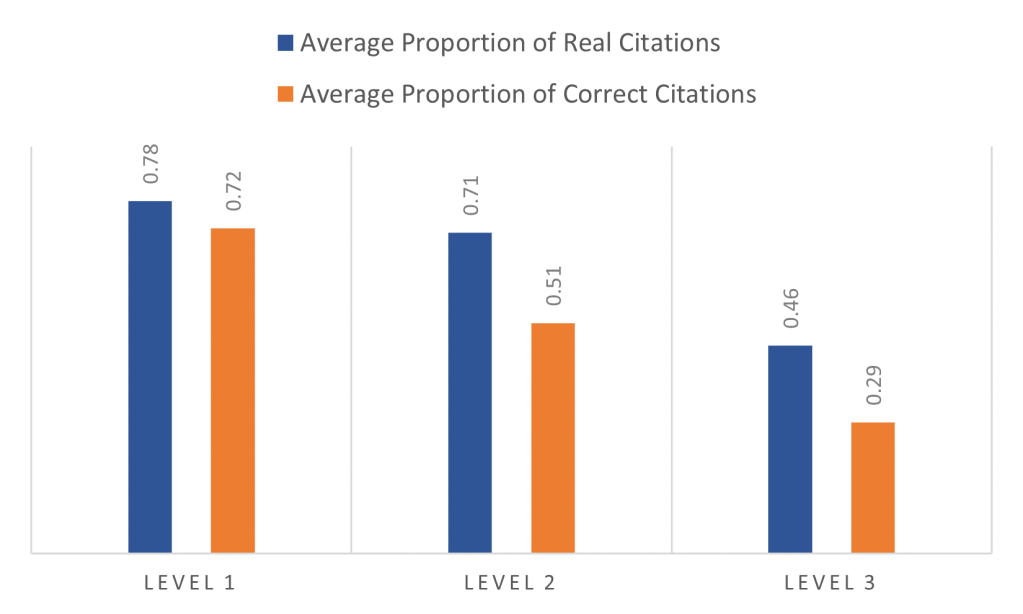
My paper about how ChatGPT generates academic citations should be useful to academics as a way to quickly grasp the strengths and weakness of ChatGPT. ChatGPT often works well, but sometimes fails. It’s important to anticipate how it fails. Our paper is so short and simple that your undergraduates could read it before using ChatGPT for their writing assignments.
A paper that does this in a different domain is “GPT4GEO: How a Language Model Sees the World’s Geography” (Again, consider showing it to your undergrads because of the neat pictures, but probably walk through it together in class instead of assigning it as reading.) They describe their project: “To characterise what GPT-4 knows about the world, we devise a set of progressively more challenging experiments… “
For example, they asked ChatGPT about the populations of countries and found that: “For populations, GPT-4 performs relatively well with a mean relative error (MRE) of 3.61%. However, significantly higher errors [occur] … for less populated countries.”
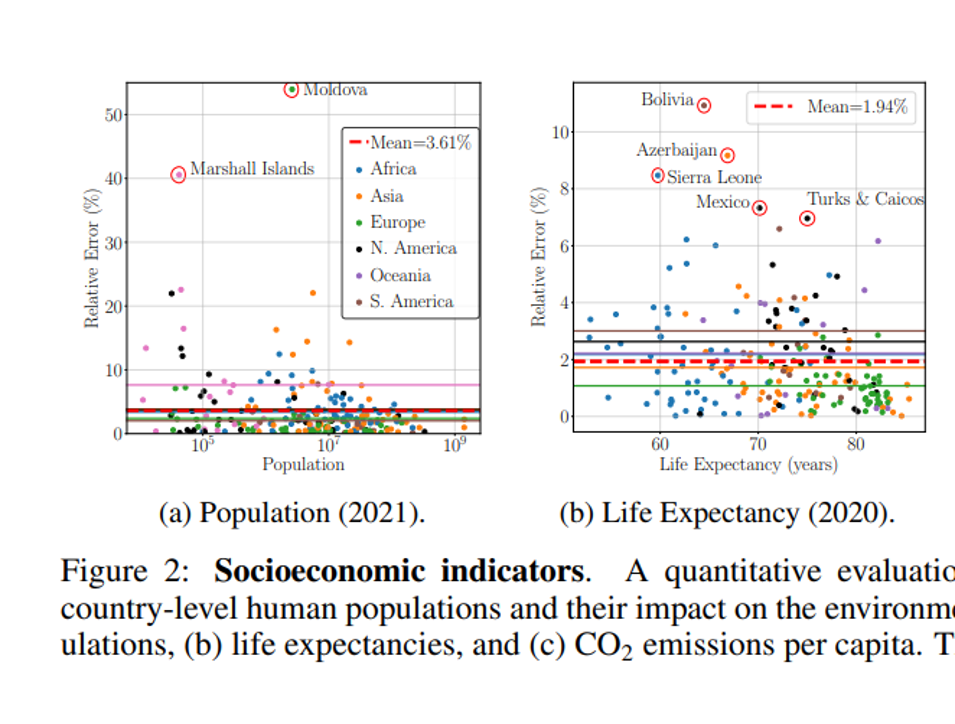
ChatGPT will often say SOMETHING, if prompted correctly. It is often, at least slightly, wrong. This graph shows that most estimates of national populations were not correct and the performance was worse on countries that are less well-known. That’s exactly what we found in our paper on citations. We found that very famous books are often cited correctly, because ChatGPT is mimicking other documents that correctly cite those books. However, if there are not many documents to train on, then ChatGPT will make things up.
I love this figure from the geography paper showing how ChatGPT estimates the elevations of mountains. This visual should be all over Twitter.
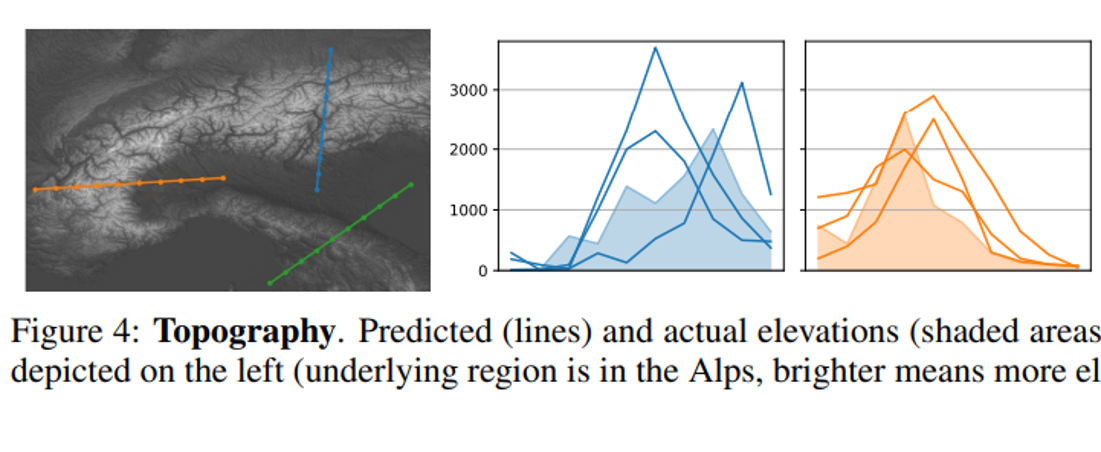
There are 3 lines because they did the prompt three times. ChatGPT threw out three different wrong mountains. Is that kind of work good enough for your tasks? Often it is. The shaded area in the graph is the actual topography of the earth in those places. ChatGPT “knows” that this area of the world is a mountain. But it will just put out incorrect estimates of the exact elevation, instead of stating that it does not know the exact elevation of those areas of the world.
Another free (long, advanced) resource with great pictures is Stephen Wolfram’s 2023 blog article “What Is ChatGPT Doing … and Why Does It Work?” (YouTube version)
The first thing to explain is that what ChatGPT is always fundamentally trying to do is to produce a “reasonable continuation” of whatever text it’s got so far, where by “reasonable” we mean “what one might expect someone to write after seeing what people have written on billions of webpages, etc.
If you feel like you already are proficient with using ChatGPT, then I would recommend Wolfram’s blog because you will learn a lot about math and computers.
Scott wrote “Generative AI Nano-Tutorial” here, which has the advantage of being much shorter than Wolfram’s blog.
EDIT: New 2023 overview paper (link from Lenny): “A Survey of Large Language Models“