This morning the Bureau of Labor Statistics released the latest quarterly data for their Quarterly Census of Employment and Wages for the first quarter of 2024. Along with this release is the announcement of their preliminary “benchmark estimate” for March 2024, which will eventually (next year) be used to revise employment data for the Current Employment Statistics program. To keep all of the alphabet soup of programs clear in year head, CES is the more familiar “nonfarm jobs” data that is released each month, usually with some media fanfare.
Benchmarking is an important part of the process for many data releases, because the monthly CES data is based on a survey of employers, a subset of the total. But the QCEW data is the universe of employees — at least the universe of the those covered by Unemployment Insurance law, which is something like 97-98% of workers in the US. So the numbers will never match exactly (CES is supposed to be measuring all workers, not just the 97-98% covered by UI), but they should be pretty close. The media reports the CES monthly data more prominently, because it is more timely and usually pretty close to correct — but benchmarking is the process to see just how correct those initial surveys were.
That brings us to the release today, which is the preliminary estimate of the benchmark adjustment for March 2024 (it will be finalized early in 2025). And that preliminary estimate was a big number, with a downward revision projected of 818,000 jobs. To put this in perspective, the current CES data shows 2.9 million jobs were added between March 2023 and March 2024, so this estimate suggest that the job growth was overstated by perhaps 40 percent. That’s a big revision, though large revisions are not unheard of: the same figure for March 2022 was an estimated 468,000 jobs higher, while March 2019 was 501,000 jobs lower. But this year is a big one (largest absolute number since 2009). Here’s a chart summarizing recent years revisions from Bloomberg:
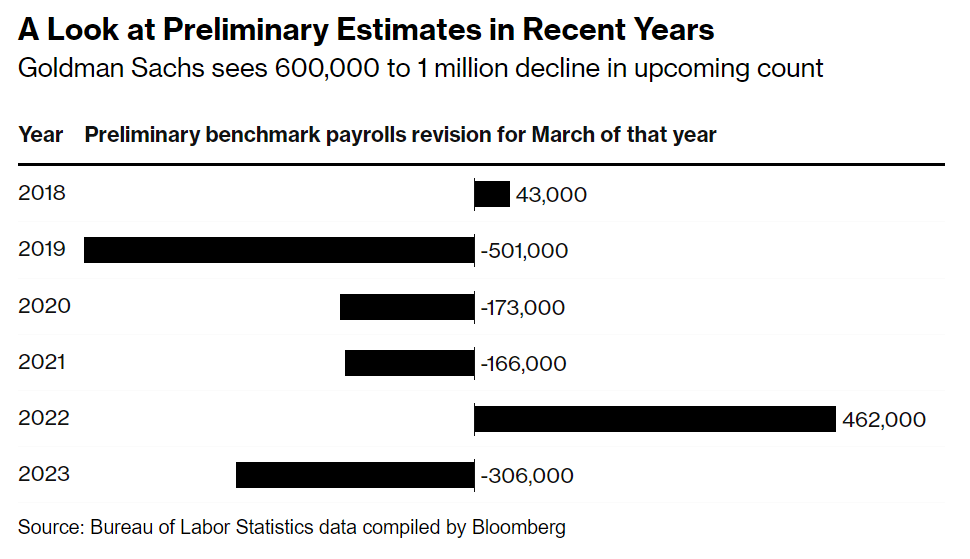
I’ve covered this topic before, such as an April 2024 post where I noted that as of September 2023, there was an 880,000 gap in job growth between the CES and QCEW over the prior year. So this was not unexpected, and in the days leading up to the report, close followers of the data were forecasting that the revision could be up to 1 million jobs.
Continue reading