It’s the time of the year when we share ideas for things to buy, possibly as Christmas or other holiday gifts. But I’m going to share with you not a specific thing to buy, but instead a method for buying things. And probably not the kind of thing you might think of sticking in a wrapped present: food.
We’ve all heard about and felt inflation lately. But food prices have been especially noticeable to consumer, and not just because it’s a product you frequently buy and probably know the price of many food items. Food prices, both at home and restaurants, have increased much more than the average price levels.
On average, prices are up about 20 percent in the US over the past 4 years. But food prices are up about 25 percent, on average.
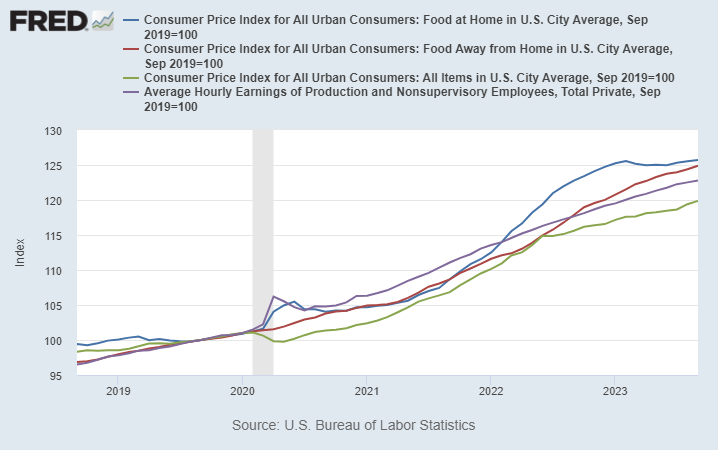
Wages (the purple line) actually have increase faster than the general price level over the past 4 years — that may shock you given what we constantly hear in the traditional and social media about “price increases outpacing wage gains” — but it is true when we are talking about food. Your dollar doesn’t go quite as far as it used to for food.
In some sense these costs are hard to avoid: food is a necessity. But there are ways to reduce your costs, and you probably know the general tips. Eat less at restaurants. Buy generic. Buy in bulk. Etc. These are good tips, but they all involve some sacrifice or annoyance. Is there anything else a consumer can do?
Yes. Here’s a few tips that can save you money, without the sacrifice. There is some thought involved, and perhaps a slight annoyance, but I’ve found that once you get in these habits, the mental and time cost is pretty low.
1. RESTAURANT APPS
You should always be ordering your food through restaurant apps when possible, especially for fast food. I try to track limited good deals on Twitter, but most restaurants offer on-going good deals. For example, McDonalds usually has a 20% off coupon, just for using the app. Taco Bell has a $6 box you can build, which would cost around $10 to order as a combo or à la carte at the restaurant. That’s a 40% discount for using the app.
Using apps also means you are using the restaurant’s rewards programs. Valuations vary, but McDonald’s rewards are roughly worth 10% cash back.
2. CHASE THE SALES AT GROCERY STORES
Clipping coupons is the classic way of saving money at the grocery store (we even have reality shows about it), but in the modern world grocery stores have expanded the ways to effectively save the same amount of money. The clearest example is, once again, the rise of apps. Stores will often have “digital only” coupons that you need to access through their app (which is also tied to your rewards account, just like restaurants).
While I’m a strong advocate of coupon clipping (and the virtual equivalent), it can be time consuming. Another strategy that can save you is thinking ahead about seasonal and other cyclical prices. For example, my kids like M&M’s. We usually buy a bulk 62-ounce container at Sam’s Club (already a savings), but today I took the additional saving step of buying the Halloween-themed bulk container. It was 36 percent less than the identical Christmas-themed M&M’s container right next to it. And I was replacing the Easter-themed bulk container that we purchased back in April, and they just finished.
Of course, I had to be planning ahead and know that November 1st was a great day to buy M&M’s. That takes some mental effort, sure. And you might think these kinds of deals are fairly limited in nature. But holidays aren’t the only kind of seasonal deals. For example, even though most fruit is generally available year-round now, there are still predictable price cycles of when things are “in season” and when they have to be imported from expensive locations. Even if you are only able to find these cyclical deals for 10 percent of your purchases, saving 30-50% on cyclical goods will shave another 3-5% off your grocery bill — bringing it closer in line to the average increase in prices (and wages).
3. CASH BACK CREDIT CARDS
I could write an entire post about credit card rewards. But let me focus here on credit cards that are especially good for buying food. At a minimum you should be getting 2 percent back on all of your purchases, as there are several no-annual-fee cards that give you 2 percent: the Citi Double Cash and Wells Fargo Active Cash are good examples.
But on food purchases, you should be able to beat 2 percent. For example, the Citi Custom Cash card gives you 5 percent back on your top spending category each month, up to $500 of spending. This can be on either groceries or restaurants. And since a family in the median quintile spends $250 at restaurants and $460 on groceries per month, you should be getting 5 percent back on basically all of your purchases in one of these two categories. (Personally I stick to restaurants for this card, because I buy most of my groceries at Walmart and Sams Club, which don’t count towards the grocery cash back.) Or if you want a simple card that gives you 3 percent back on both groceries and restaurants, check out the Capital One SavorOne card (again, no annual fee).
There are also several cards that have rotating 5 percent cash back categories each quarter, and they often include either restaurants or groceries. How do I keep track of which card to use for what kind of purchase? Simple: put a strip of masking tape on the card with a label. This will get some chuckles from your friends or the server at the restaurant, but that’s just an opportunity to tell them how to save money too!
Is There Really a Free Lunch?
Some of my economist friends are probably skeptical at this point. Aren’t I say there is a free lunch here? Isn’t the extra hassle of the steps I suggested going to outweigh any discount you get?
The answer is No. And while economists are quick to bring up the concept of opportunity cost, I find that most people tend to overestimate their opportunity cost. But even if you don’t overestimate your opportunity cost, you can bring in another useful economic concept: price discrimination.
Restaurants are very much in the business of price discrimination, and always have been. Tuesday Night specials, happy hours, etc. Every consumer has a different willingness to pay, and since it’s hard to resell a restaurant meal, restaurants can potentially use this technique to their advantage (and yours, if you are willing to look for discrimination). Grocery stores don’t have as much of an opportunity to discriminate, but they still find ways.
Don’t be afraid of price discrimination: use it to your advantage!