We know WAY more about Covid-19 than we used to. But there is plenty of appropriate and inappropriate incredulity concerning the data meaning, validity, and implication. I want to take a minute and give it the good ol’ Stat – 201 college try. Here’s the level-headed and appropriately humble Covid statistics conversation.
A: “The US has more cases of Covid than Portugal.”
B: “Yes, but that’s not important. They are very different countries. After all, 65% of people in Portugal live in urban centers. For the US, that number is 80%. Obviously, people being close together, such as in urban places, will contribute to more Covid cases.”
A: “OK. Fine. They may be incomparable. But the US has more cases than the UK, which has a similarly urban population of 83%.”
B: “Yes, but the US is larger. The UK has a smaller population – Of course the US has more cases.”
A: “Ah! And the US also has a Covid positivity rate well in excess of the UK.”
B: “Hmm… That is something. The problem is that the testing is not administered in the same fashion in both places (or across time). That is, neither set of tests is a simple random sample of people and neither is biased in sampling in the same sort of relevant ways.”
A: “But how do you know that the samples aren’t collected in the same sort of ways? Someone feels poorly, then they go and get tested. Isn’t that how is works everywhere?”
B: “Not necessarily at all. Some countries and municipalities offer free testing. Other places have more or less scarcity of tests and surely that affects whom they decide to test. Not only that, different people are differently willing to get tested (maybe they’d have to involuntarily stop working, for example). My point is that the testing samples are not both biased in favor or against positives in the same way and we have little way of telling either the direction or magnitudes. The fact that both countries test a similar proportion of the population doesn’t address the sampling method.”
A: “OK. Well, I suppose that we ought not try at all then, according to you? Isn’t some problematic data better than none?”
B: “Problematic data is not better than none at all if we have good reason to think that there isn’t enough in common between sample collection methods to make valid comparisons.”
A: “Right, so you’re saying that we have to be agnostic.”
B: “In some sense, yes. But rather than Covid cases, we can track relevant variables whose sampling is more comparable. Hospitalizations are better, but we still have the issue of selection bias among those being admitted and a bias due to different hospital capacities between localities. The best measure is the number of deaths due to Covid. People can’t elect out of that sample.”
A: “Hm… Ok. But while total deaths is a more dependable statistic, it is less relevant. Of course deaths matter a great deal, but Covid makes people feel terrible and may even have long term effects.”
B: “You’re right. Covid deaths Vs cases has the trade-off of relevance Vs dependability. Arguably, deaths are the most important possible symptom – although I take your point that it’s not the only relevant symptom. Ultimately, however, the death numbers are more dependable and we should use them if we want a high degree of certainty.”
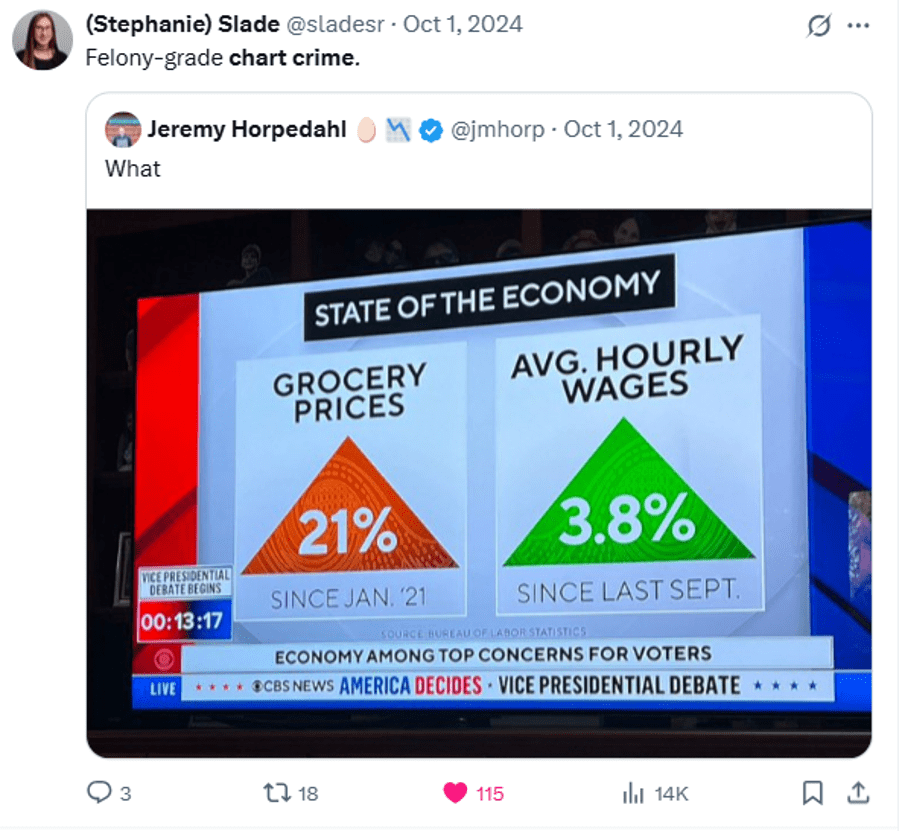
A: “Fine. The US has more Covid deaths than does the UK, both in level and in deaths per thousand of population.”
B: “Yep. You are right. But the US has more Covid cases, so of course it has more Covid deaths than the UK. The correct statistic is, given a Covid diagnosis, how likely are you to die of Covid? In the UK, a much higher proportion of people with a Covid diagnosis die. In other words, Covid is more dangerous in the UK than it is in the US.”
A: “Time out. Two things: 1) Didn’t you say just a moment ago that the testing data wasn’t reliable enough? Now you’re using it as if it’s reliable. 2) If we are making a cross country comparison, then can’t we just say that a person, randomly drawn from the population, is more likely to die from the Covid in the US than in the UK?”
B: “Mea culpa. You’re right on both points. At the end of the day, a US person is more likely to die of Covid. But, in the UK a person with Covid may be more likely to die. So what do we do about that?”
A: “Good question…”