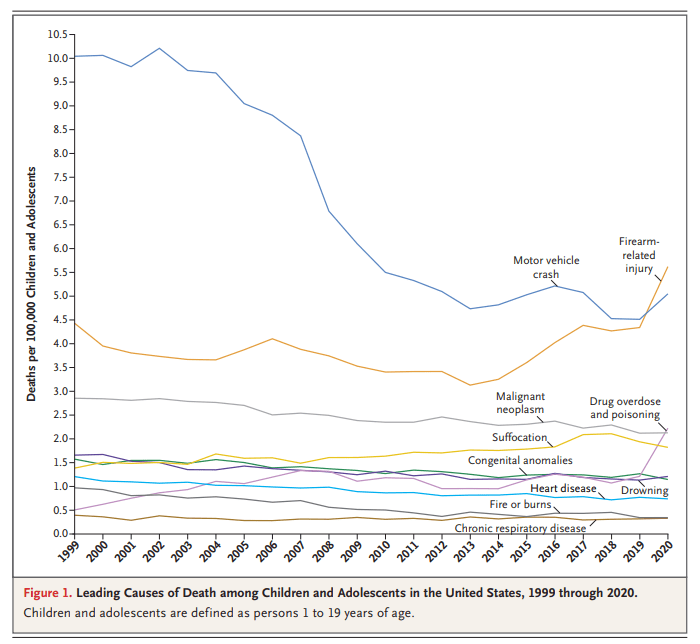
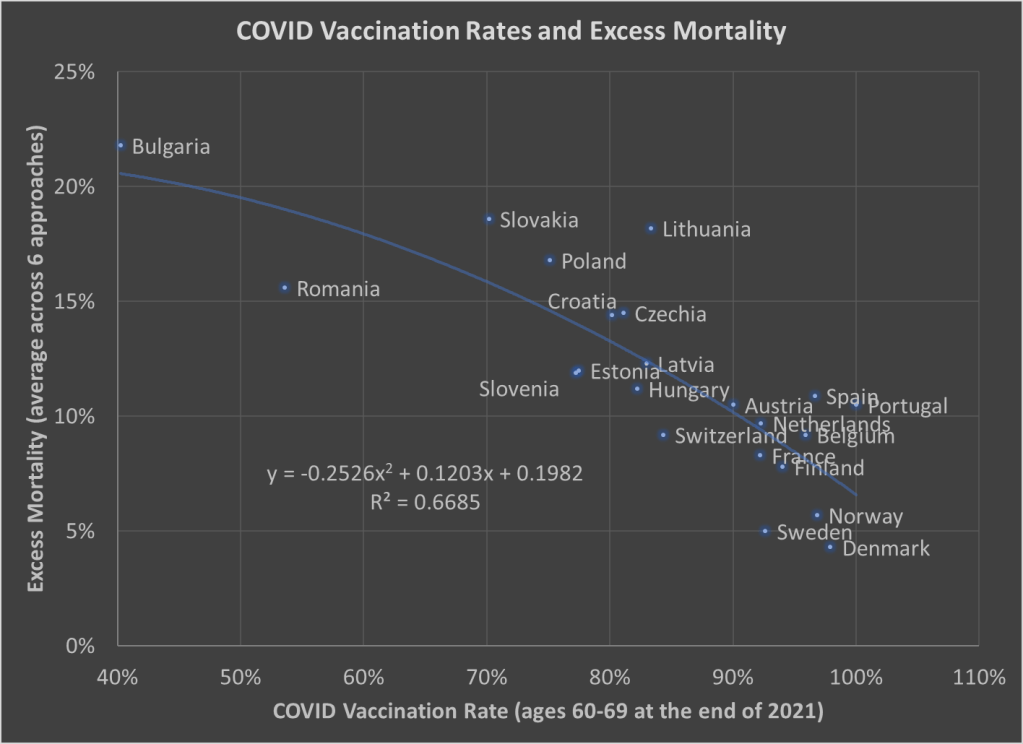
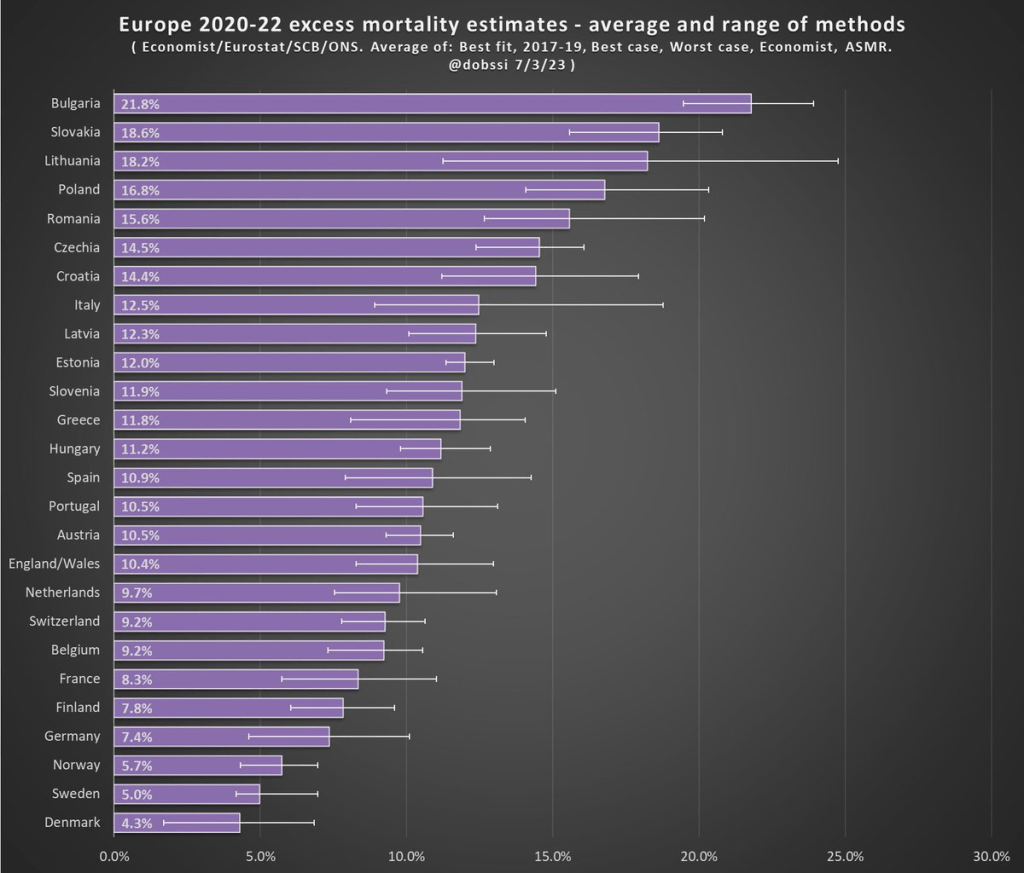
Most new businesses are funded with a combination of debt and the owners’ savings; equity funding has traditionally been relatively rare:

Partly this has been a regulatory issue. Raising equity adds all sorts of legal burdens. Traditionally businesses could only accept equity investments from accredited investors and a small number of friends and family unless they did a full IPO and became public (hard enough that there are less that 5000 public companies in the US out of millions of businesses). This changed with the JOBS Act of 2012, which allowed small businesses to raise money from large numbers of non-accredited investors without having to register with the SEC.
Following the JOBS Act, equity crowdfunding sites like WeFunder emerged to match new businesses with potential investors. But equity crowdfunding has taken off relatively slowly:

Its seen more success recently with some additional regulatory relief and the overall market boom of 2020-2021. But at ~$400 million/yr, its still well under 1% of all venture investment (~$300 billon/yr), which is itself tiny relative to the public stock market ($40 trillion market cap).
Why has equity crowdfunding been slow to take off? Partly its new and most people still don’t know about it. Partly early-stage companies aren’t a good way for most people to invest a significant fraction of their money; you probably want to be at least close to accredited investor levels (~$300k/yr income or $1 million liquid wealth) for it to make sense, and those at the accredited investor level already have other options. WeFunder is up front about the risks:

The other issue here is with asymmetric information and adverse selection. Its hard to find out much information about early-stage companies to know if they are a good investment; part of the point of the JOBS Act is that the companies don’t need to tell you much. The companies themselves have a better idea of how well they are doing, and the best ones might not bother with equity crowdfunding; they could probably raise more money with less hassle by going to venture funds or accredited angel investors.
I’ve long thought this adverse selection would be the killer issue, but my impression (not particularly well-informed and definitely not investment advice) is that there are now quality companies raising money this way, or at least companies that could easily raise money elsewhere. WeFunder has a whole page of Y-Combinator-backed companies raising money there. This week Substack, an established company that has already raised lots of venture funding, offered crowd equity and reached the $5 million limit of how much they could legally accept in a single day.
Overall I think this model is working well enough that I’m no longer in a hurry to become an accredited investor. Accredited investors have many more options for companies they can invest in and aren’t subject to the $2,200/yr limit on how much they can invest in early-stage companies. But even if I completed the backdoor process of getting accredited without being rich, I wouldn’t want to put more than $2,200/yr into early-stage companies until I was a millionaire, at which point I’d be accredited the usual way. And while most companies aren’t raising crowd equity, enough are that there seem to me to be no shortage of choices.