Kevin Erdmann has written a detailed and thoughtful response to my post from last week on housing spending as a percent of income. My goal in that post was to look at consumer spending as a percent of income for a variety of different sub-groups (my primary interest was by age group, but I tried to get into more detail for other sub-groups).
As Erdmann emphasizes in his post, I left out one set of sub-groups that the CEX data allows us to use: renters vs. homeowners. And these are very important groups to look at, since for homeowners (as he points out) many of the costs are implicit (such as the opportunity cost of those that don’t have a mortgage). Lumping all of these households together may obscure some of the different trends.
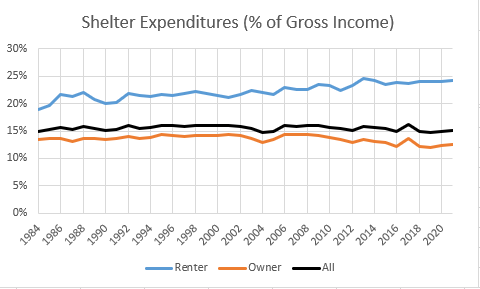
Be sure to read Erdmann’s post in full (he says many smart and correct things), but the key result is in his Figure 2 (reproduced here). Renters have seen the share of their income spent on shelter rise from 19% in 1984 to 24% in 2021. This is not a trivial increase. Owners, by contrast, have seen their share of spending fall, which is how it all gets washed out in the average.
I will concede that Erdmann is probably right on many of his many points. Still, I wanted to see this at a much finer level of detail, since national aggregates might be giving us confusing results. The micro-data in the CEX is probably not detailed enough to give us good breakdowns by MSA.
One of the oldest theories in economics is the idea of compensating differentials. A job represents not just a certain amount of money per hour, but a whole package of positive and negative things. Jobs have more or less stability, flexibility, fun, room to grow, danger… and non-cash benefits like health insurance. The idea of compensating differentials is that, all else equal, jobs that are good on these other margins can pay lower cash wages and still attract workers (thus, the danger of doing what you love). On the other hand, jobs that are bad on these other margins need high wages if they want to hire anyone (thus, the deadliest catch)
I think this theory makes perfect sense, and we see evidence for it in many places. But when it comes to health insurance, everything looks backwards. A job that offers employer-provided health insurance is better to most employees than one that doesn’t, so by compensating differentials it should be able to offer lower wages. There’s just one problem: US data shows that jobs offering health insurance also offer significantly higher wages. The 2018 Current Population Survey shows that workers with employer-provided health insurance had average wages of $33/hr, compared to $24/hr for those without employer insurance.
All the economists are thinking now: that’s not a problem, compensating differentials is an “all else equal” claim, but not all else is equal here. The jobs with health insurance pay higher wages because they are trying to attract higher-skilled workers than the jobs that don’t offer insurance.
That’s what I thought too. It is true that jobs with insurance hire quite different workers on average:
The problem is, once we control for all the observable ways that insured workers differ, we still find that their wages are significantly higher than workers who don’t get employer-provided insurance. Like, 10-20% higher. That’s after controlling for: year, sex, education, age, race, marital status, state of residence, health, union membership, firm size, whether the firm offers a pension, whether the employee is paid hourly, and usual hours worked. I’ve thrown in every possibly-relevant control variable I can think of and employer-provided health insurance always still predicts significantly higher wages. Of course, there are limits to what we get to observe about people using surveys; I don’t get any direct measures of worker productivity. Possibly the workers who get insurance are more skilled in ways I don’t observe.
We can try to account for these unobserved differences by following the same person from one job to another. When someone switches jobs, they could have health insurance in both jobs, neither, only the new, or only the old. What happens to the wages of people in each of these situations? It turns out that gaining health insurance in a new job on average brings the biggest increase in wages:
What could be going on here? One possibility is that health insurance makes people healthier, which improves their productivity, which improves their wages. But we control for health status and still find this effect. The real mystery is that papers that study mandatory expansions of health insurance (like the ACA employer mandate and prior state-level mandates) tend to find that they lower wages. Why would employer-provided health insurance lower wages when it is broadly mandated, but raise wages for individuals who choose to switch to a job that offers it?
My current theory is that “efficiency benefits” are offered alongside “efficiency wages”. The idea of efficiency wages is that some firms pay above-market wages as a way of reducing turnover. Workers won’t want to leave if they know their current job pays above-market, and so the company saves money on hiring and training. But this only works if other firms aren’t doing it. The positive correlation of wages and insurance could be because the same firms that pay “efficiency wages” are more likely to pay “efficiency benefits”- offering unusually good benefits as a way to hold on to employees.
I still feel like these results are puzzling and that I haven’t fully solved the puzzle. This post summarizes a currently-unpublished paper that Anna Chorniy and I have been working on for a long time and that I’ll be presenting at WVU tomorrow. We welcome comments that could help solve this puzzle either on the empirical side (“just control for X”) or the theoretical side (“compensating differentials are being overwhelmed here by X”).
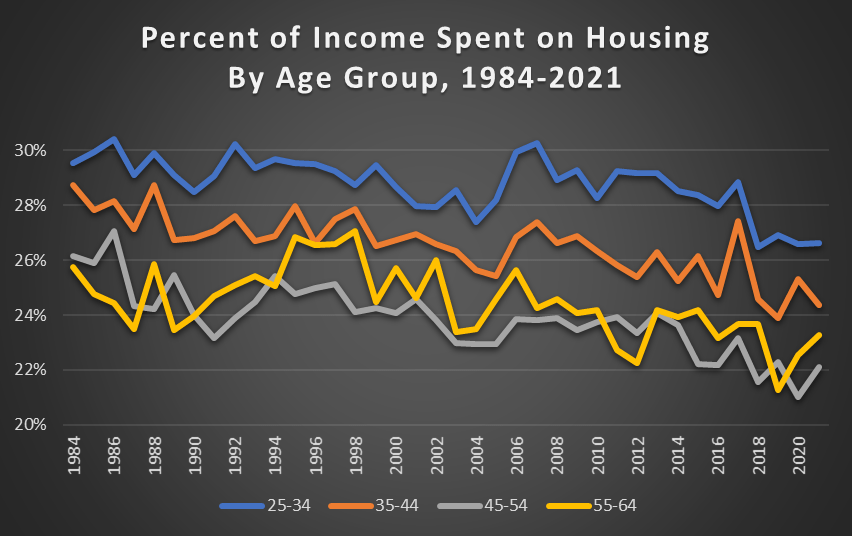
Are Americans spending more of their income on housing than in the past? Using data from the Consumer Expenditure Survey back to 1984, the answer is pretty clear: no. In fact, it has declined mildly.
This concern is usually raised on the context of young people. Are young people spending more of their income on housing than in the past? No.
For working-age Americans, the percent of their income spent on housing has declined mildly since 1984, but I think it’s accurate to say it’s pretty stable (I have truncated the y-axis so you can see the detail). It’s true that young people spend more of their income on housing than older people, but this has always been true, and the gap is pretty constant.
I have a list of economics topics that I like to teach about because they conflict with the biases of my average student. The list includes fiat currency, inflation, deficits, net exports, and immigration. The list also includes the importance – or lack thereof – of the federal government’s debt. This post walks through a few graphs to do a gut-check of what we think is true and how it compares to reality. For example, do you have a sense of when the debt grew historically and when it was constant? Do you have a sense for when it shrank?
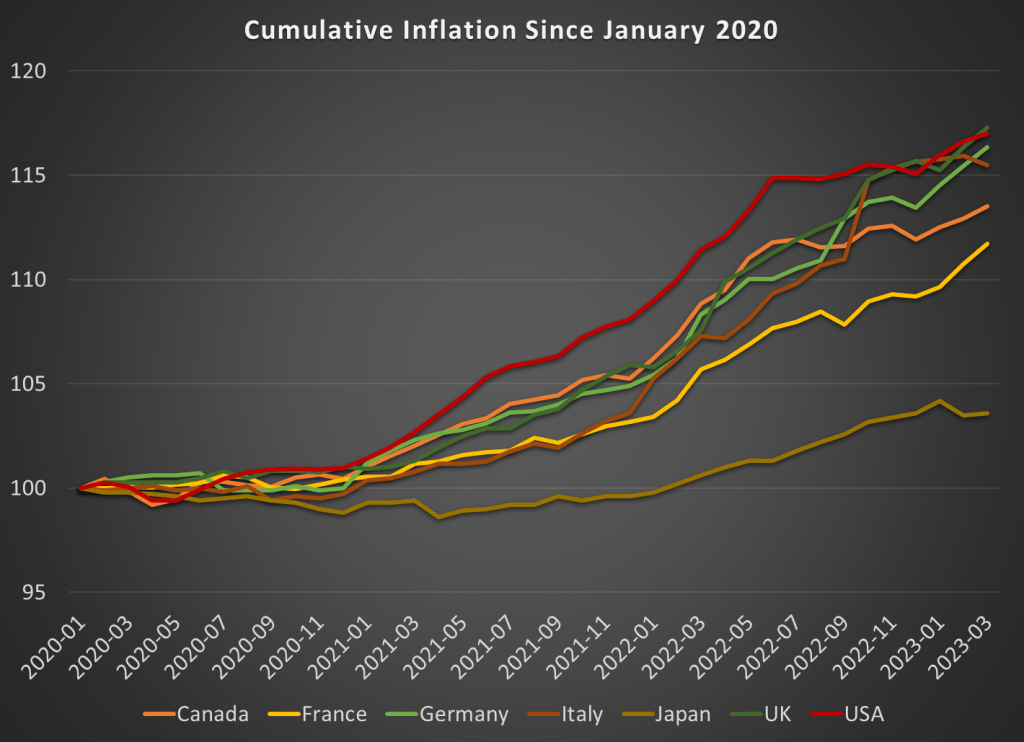
In August 2022, I wrote a post showing that among G7 nations, the US had the highest inflation during the pandemic, but also the highest rate of real economic growth. But since the economic situation is evolving rapidly, I wanted to update that data from mid-2022 (I also use core inflation, but I’ll use total inflation in this post).
Here’s how inflation has looked during the pandemic:
While the US had the most cumulative inflation for much of the pandemic, the cooling of inflation in the US and the acceleration in Europe has changed things a bit. By late 2022, the UK and Italy had caught up to the US, and Germany is closing in too. These countries have cumulative inflation of between 15 and 17 percent since January 2020.
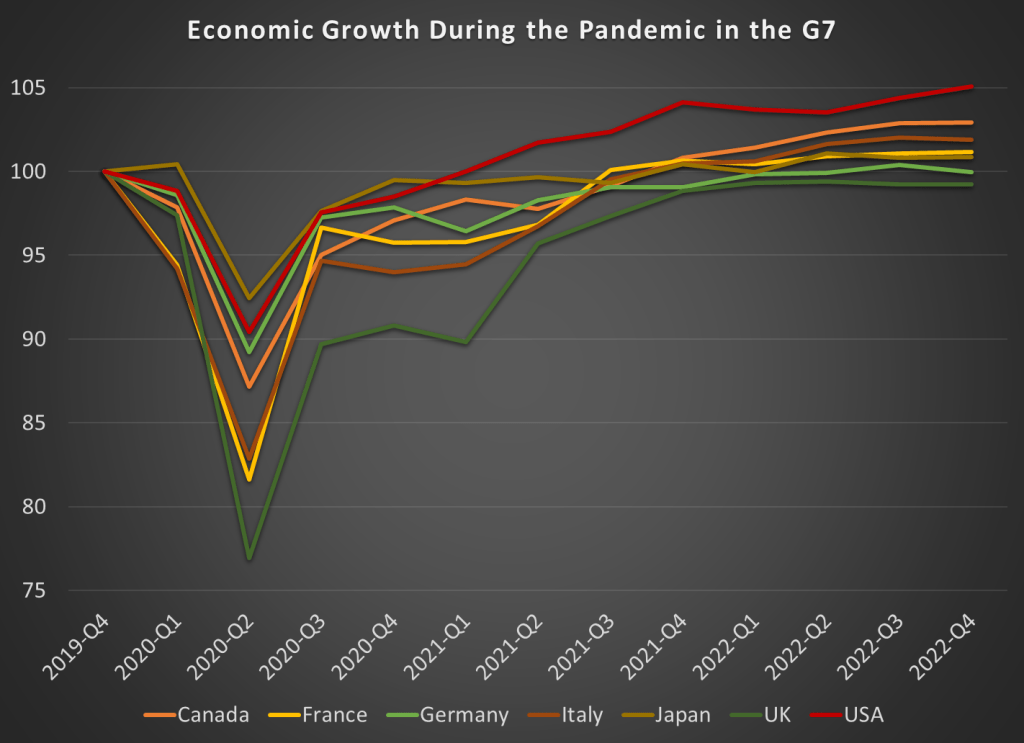
Japan looks to be the winner here. But wait, we don’t only care about low and stable inflation. We also want economic growth. Here’s the data through the 4th quarter of 2022 (we’ll start to get 2023q1 data from countries next week):
By this measure, the US comes out as the clear winner, with real GDP being about 5 percent higher than the end of 2019. That might not sound impressive for 3 years of growth, until you realize that 5 of the 7 nations had growth below 2 percent, with Germany and the UK actually still smaller than the end of 2019! And this doesn’t take account of the cumulative losses. Notice that the US had the second smallest dip in 2020q2 as well.
It’s hard to know exactly what the right non-COVID counterfactual would be, since these countries all had different rates of growth before the pandemic. But adding up the GDP scaled to 100 before the pandemic, the US is the only G7 country where these 12 quarters of data add up to more than 1,200. The other countries haven’t even had enough growth since the 2020 recession to make up for the losses during the recession, to say nothing of what their potential growth would have been. Japan comes the closest to making up the losses, while the UK stands out as the worst.
Here’s the figures for all the G7 countries, with 100% meaning they have had enough growth to offset the losses from the 2020 recession:
Is the federal government spending at a faster rate? Your answer probably has more to do with your biases than with anything else. Most people don’t know the numbers or they imagine some more appropriate past. Below is logged current federal expenditures (this does not include government fixed investment, only consumption. Yes, we can argue about measures. This doesn’t include transfers).
The line of best fit is about 1.6% per quarter or 6.4% per year. Golly! Our spending is rising so fast! But, US federal spending grew relatively slowly in the 90s – maybe due to that fiscal conservative, Bill Clinton. And our federal spending grew even more slowly between 2010 and 2016 – maybe due to that other fiscal conservative, Barack Obama.
But, inflation varied over this period. What about real, inflation adjusted federal spending? See Below.
Medicaid is a health insurance program for those with low incomes, funded largely by states. Overall it accounts for less than 20% of US medical spending. But there is one area where it is the dominant payer: nursing homes. Nursing homes are expensive, and Medicare (the typical insurance for those over 65) won’t cover them after the first hundred days, so most nursing home residents end up paying out of pocket until they burn through all their savings and wind up on Medicaid. At which point, Medicaid pays about $100,000 per year to the nursing home for the rest of their life.
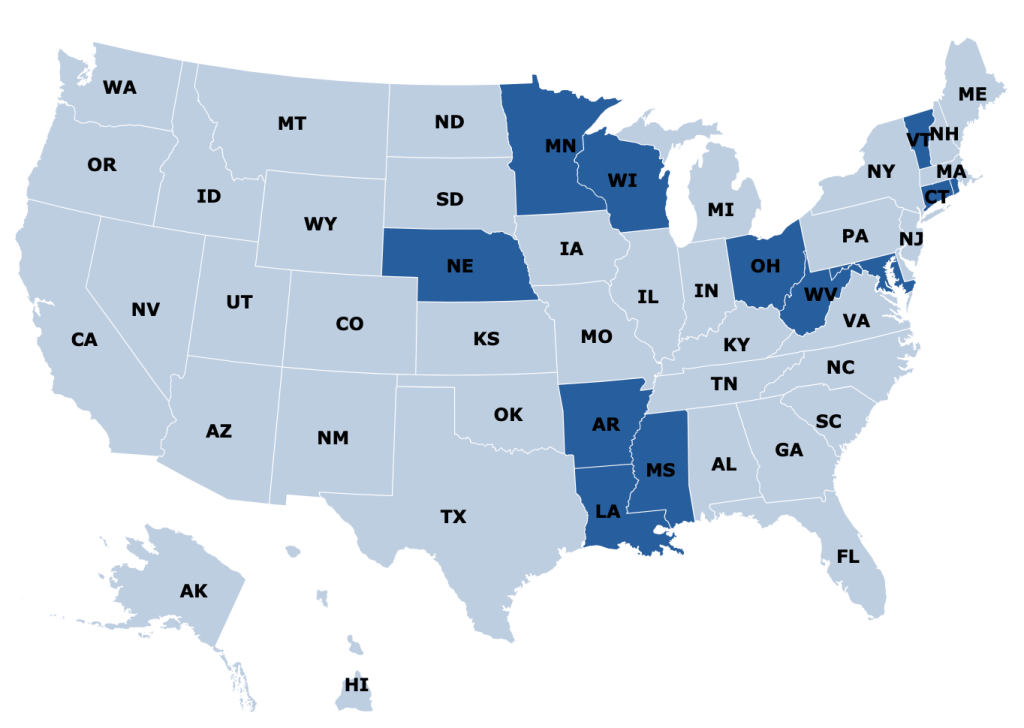
States are responsible for up to half of that cost, and so start looking for ways to save money. One idea they have is to make it harder to build nursing homes: if there aren’t beds available, potential nursing home patients will have to stay home instead, where they can’t rack up Medicaid spending the same way. In fact, some states go all the way to a complete moratorium on new nursing homes:
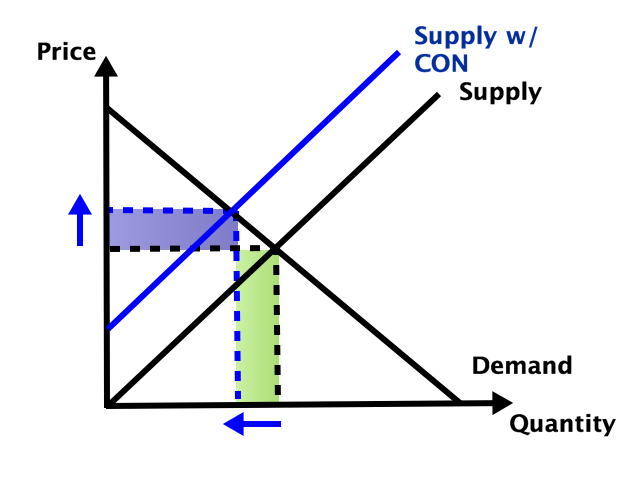
Some other states allow new nursing homes, but only with a special permission slip called a Certificate of Need (CON). CON is often required for other types of health facilities as well, like hospitals or dialysis centers. Research by me and others has generally found that CON doesn’t work as a way to reduce spending, and in fact actually increases it. CON might reduce the number of facilities, but that reduction of supply and competition gives the remaining facilities more power to raise prices.
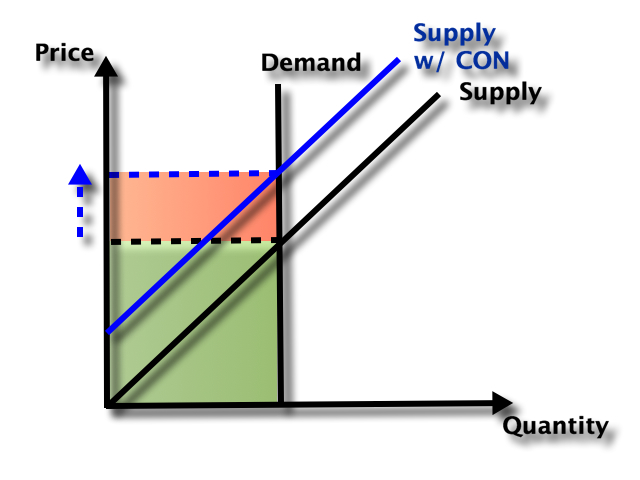
So which effect dominates- does the smaller number of facilities reduce total spending, or do the higher prices increase it? It depends on the elasticity of demand:
In health care demand is typically quite inelastic, so the price effect dominates, and spending goes up:
But nursing homes could be an exception here. Elasticity of demand could be relatively high because of the number of potential substitutes- home care or assisted living for those with relatively low medical needs, hospitals for those with relatively high medical needs. Plus this is the one type of health care where Medicaid is the dominant payer. They could be especially resistant to price increases here, both due to their market power and their willingness to keep prices so low that facilities won’t take Medicaid patients (another way to save money!).
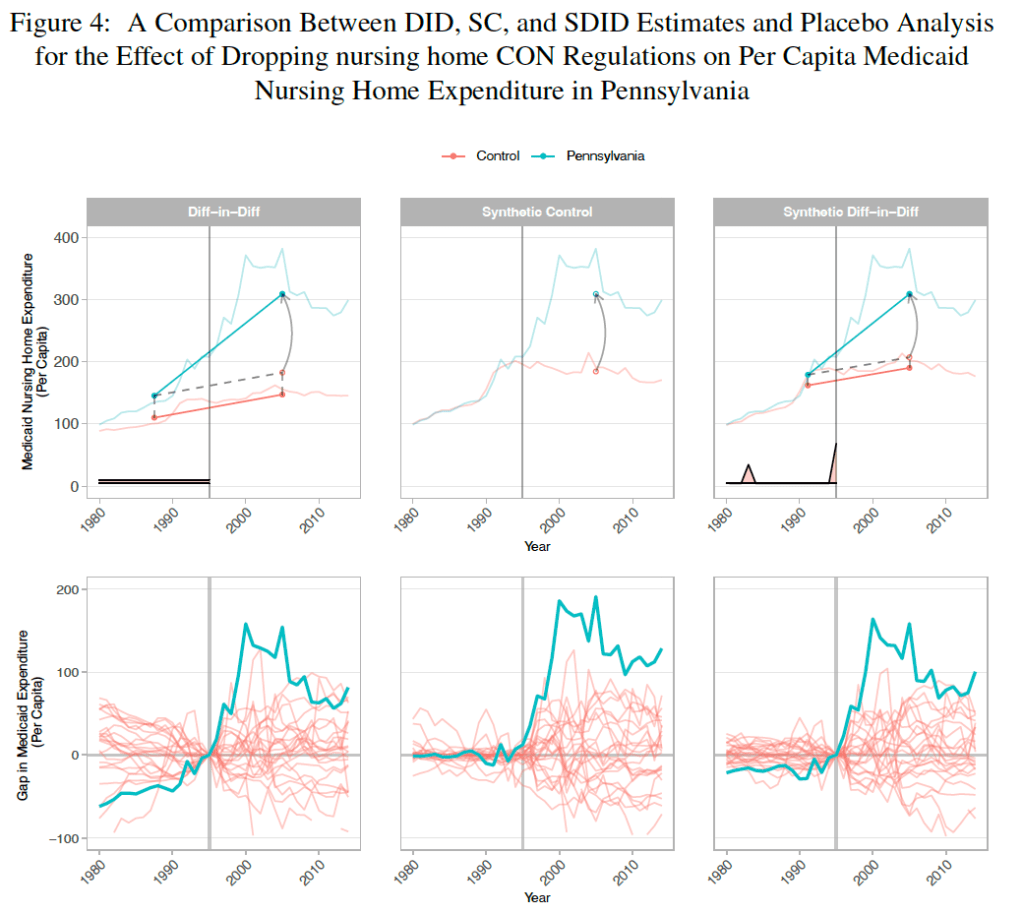
A new paper by Vitor Melo and Elijah Neilson finds that this is indeed the case. Indiana, Pennsylvania, and North Dakota repealed their nursing home CON requirements in the ’90s, and at least for IN and PA their Medicaid spending went way up. The paper uses a new “synthetic difference in difference” technique that seems appropriate, and creates figures that seem confusing at first but get a ton of information across:
They correctly note that they don’t evaluate the welfare effects of the policy; it’s possible that the extra nursing home beds following CON repeal bring huge benefits to seniors that are worth the higher spending. But nursing homes could be the exception to the general rule that CON fails to achieve the goals, like reduced spending, that advocates set for it.
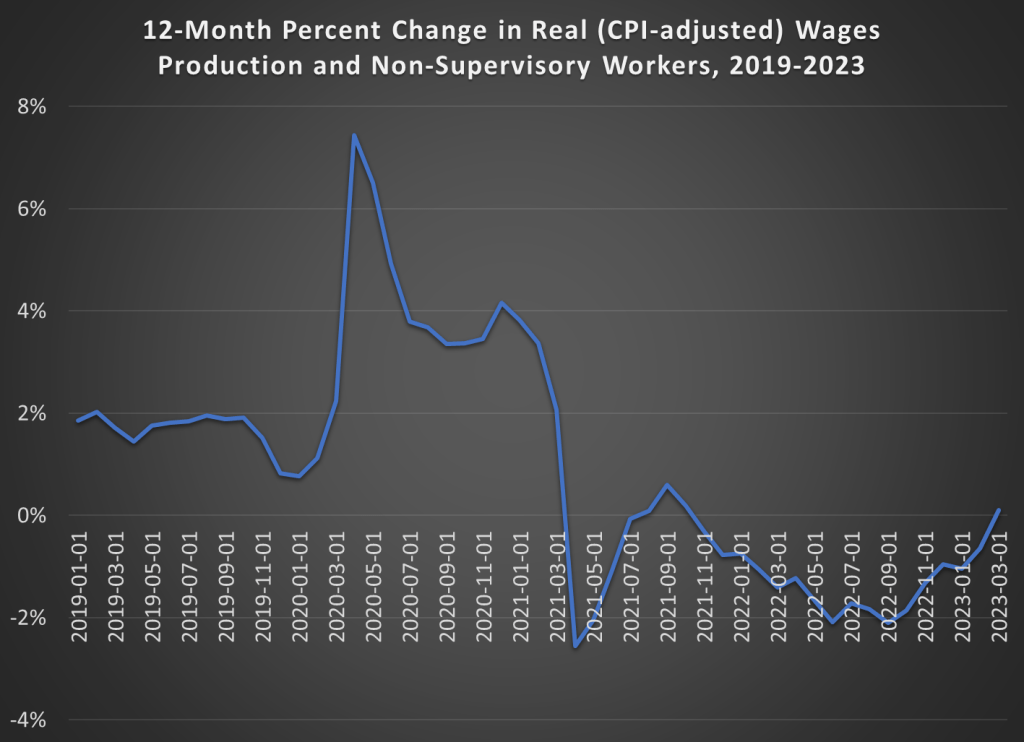
Back in December I pointed out that, thanks to slowing inflation, real wages had been rising since June 2022 (using either the CPI or the PCEPI for inflation adjustments).
With the latest monthly data, we can now report more good news for wage earners: CPI-adjusted wages have increased over the past 12 months. That had happened since 2021. In the past 12 months, wages of production and non-supervisory workers are up 5.1%, just a hair more than the annual increase in the CPI of 5.0%. It’s not much, and we’re not back to our pre-pandemic norm of 2% real wage growth. But it is more good news that we may finally getting past our post-COVID inflationary hangover.
Since posting it in January of 2023, our post on a failure of ChatGPT has been one of the most popular articles of the year in terms of web traffic. Read ChatGPT Cites Economics Papers That Do Not Exist
LLMs will make up nonsense lies, but it might sound sophisticated and serious. As human editors, we are not used to detecting that kind of problem, because usually if something sounds serious that means it has been written by a serious thoughtful person (usually).
That’s a problem, but ChatGPT is really good at some tasks.
Instead of pointing out the fact that ChatGPT is not perfect, Tyler Cowen wants people to see the potential. He has done an entire podcast interview with ChatGPT, asking it to take on the voice and role of deceased writer Jonathan Swift.
I’ll share part of the transcript:
COWEN: In 1709, you, Jonathan Swift, still were calling yourself a Whig. What exactly induced you to switch to the Tory side of the ledger?
SWIFT: My shift from the Whigs to the Tories was a gradual and complex process, influenced by several factors, including personal connections, political developments, and ideological disagreements.
During my early years in politics, I was indeed more aligned with the Whigs, who championed principles such as constitutional government, religious toleration, and the supremacy of Parliament over the monarchy. However, over time, I became increasingly disillusioned with the Whigs, particularly as their internal factions and power struggles intensified.
The Whigs’ support for the war with France, which began in 1702, was a point of contention for me. I believed that the war was costly…
The replies seem nuanced and insightful. Nothing made me suspect that they were factually inaccurate, although I do not know enough about Irish history to judge.
Is there any human who could have produced this script? I think so, although it would have required a lot of work. If one of these replies is better than anything a human Swift scholar would produce, how would we know?
GPT4 can write good summaries for the work of a prolific author like Swift, because the model can train on lots of examples.
GPT4 could probably write a good biography of a modern figure by pulling together all of the writing by them and about them. Maybe GPT4 could efficiently scrape up all mentions of this figure online and synthesize them faster than a human scholar. However, we observed GPT3 completely making up citations when we tried to get it to do economics summaries.
I’m concerned that humans will use GPT4 to write but not do the requisite fact-checking. That could introduce a new corpus of work that the next LLMs will train on, which might be full of lies. Humans might not admit to using GPT, and therefore we wouldn’t have a mechanism for using extra scrutiny on AI-generated writing from 2023. Humans can make mistakes too… so the ultimate solution could be an all-powerful AI that somehow does begin with a fairly accurate map of the world and goes around fact-checking everything faster than human editors ever could.
Partly this has been a regulatory issue. Raising equity adds all sorts of legal burdens. Traditionally businesses could only accept equity investments from accredited investors and a small number of friends and family unless they did a full IPO and became public (hard enough that there are less that 5000 public companies in the US out of millions of businesses). This changed with the JOBS Act of 2012, which allowed small businesses to raise money from large numbers of non-accredited investors without having to register with the SEC.
Following the JOBS Act, equity crowdfunding sites like WeFunder emerged to match new businesses with potential investors. But equity crowdfunding has taken off relatively slowly:
Its seen more success recently with some additional regulatory relief and the overall market boom of 2020-2021. But at ~$400 million/yr, its still well under 1% of all venture investment (~$300 billon/yr), which is itself tiny relative to the public stock market ($40 trillion market cap).
Why has equity crowdfunding been slow to take off? Partly its new and most people still don’t know about it. Partly early-stage companies aren’t a good way for most people to invest a significant fraction of their money; you probably want to be at least close to accredited investor levels (~$300k/yr income or $1 million liquid wealth) for it to make sense, and those at the accredited investor level already have other options. WeFunder is up front about the risks:
The other issue here is with asymmetric information and adverse selection. Its hard to find out much information about early-stage companies to know if they are a good investment; part of the point of the JOBS Act is that the companies don’t need to tell you much. The companies themselves have a better idea of how well they are doing, and the best ones might not bother with equity crowdfunding; they could probably raise more money with less hassle by going to venture funds or accredited angel investors.
I’ve long thought this adverse selection would be the killer issue, but my impression (not particularly well-informed and definitely not investment advice) is that there are now quality companies raising money this way, or at least companies that could easily raise money elsewhere. WeFunder has a whole page of Y-Combinator-backed companies raising money there. This week Substack, an established company that has already raised lots of venture funding, offered crowd equity and reached the $5 million limit of how much they could legally accept in a single day.
Overall I think this model is working well enough that I’m no longer in a hurry to become an accredited investor. Accredited investors have many more options for companies they can invest in and aren’t subject to the $2,200/yr limit on how much they can invest in early-stage companies. But even if I completed the backdoor process of getting accredited without being rich, I wouldn’t want to put more than $2,200/yr into early-stage companies until I was a millionaire, at which point I’d be accredited the usual way. And while most companies aren’t raising crowd equity, enough are that there seem to me to be no shortage of choices.