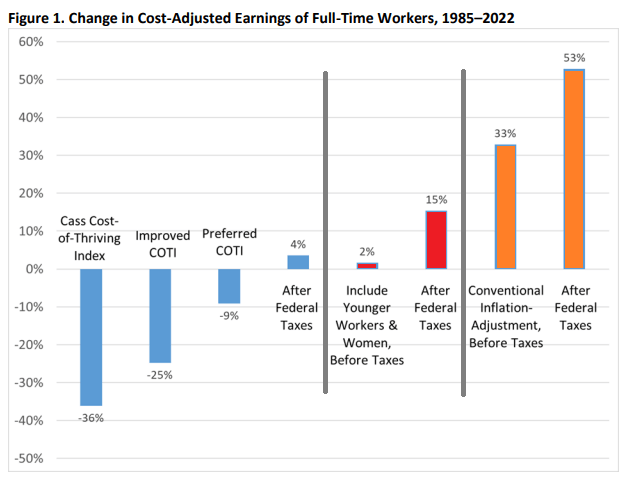
Last week my post was about a new article I have with Scott Winship on the “cost of thriving” today versus 1985. That paper has gotten quite a bit of coverage, including in the Wall Street Journal, which is great but also means you are going to get some pushback. Much of it comes in the form of “it just doesn’t feel like the numbers are right” (see Alex Tabarrok on this point), and that was the conclusion to the WSJ piece too.
Here’s a response of that nature from Mish Talk: “There’s no way a single person is better off today, especially a single parent with two kids based on child tax credits that will not come close to meeting daycare needs.”
He mentions daycare costs, but never comes back to it in the post (it’s mostly about housing costs). Daycare costs are undoubtedly an important cost for families with young children (though since Cass’ COTI is about married couples with one earner, they may not be as relevant). And in the CPI-U, daycare and preschool costs only getting a weight of 0.5%. Surely that’s not reality for the families that actually do pay daycare costs! If only there was an index that applied to the costs of raising children.
In fact, there already is. Since 1960, the USDA has been keeping track of the cost of raising a child. Daycare costs are definitely given much more weight: 16% of the expenditures on children got to child care and education. And much of that USDA index (recently updated by Brookings) looks similar to what COTI includes: housing, food, transportation, health care, education, but also clothing and daycare. I wrote about it in a post last year and compared that cost to various measures of income (including single-earner families and median weekly earnings). But what if we compared it to Oren Cass’ preferred measure of income, males 25 and older working full-time? Here’s the chart.