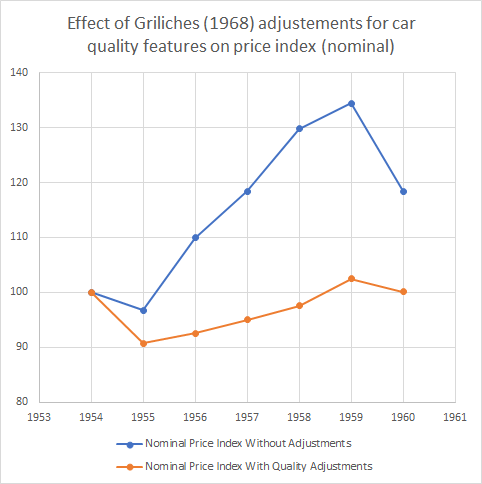
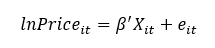In our eternal quest to never let go of any effective rhetorical device that can double as a headline, the last 12-18 months have been dubbed The Great Resignation. Within voluntary job separations, a sizable chunk of which appear to be early retirements, many are young people transitioning from low-paying jobs to those that have seen fit to adapt to the labor shortage faster, offering some combination of higher wages, better benefits, or a higher quality of life, often through the channel of relaxed educational or experience prerequisites.
Some, generally from the political left, are framing this as a shift in power from management to labor, particularly for those who hope this can be the moment that pushes unionization back to the forefront. Others, mostly from the political right, are framing this as a catastrophic undercutting of the incentive to work induced by the expanded welfare state. I tend to see these positions as frantic over-optimism or pessimism from those desperate for a sexy political narrative to sell.
I think the closer parallel, in terms of mechanism (not scale), isn’t the Great Depression or the New Deal era that followed, but rather the World War II draft-accelerated entry of women into the workforce. I think what we’re seeing is a massive reorganization of the US labor market. If this half-baked generalization were true, what would it look like?
- Education, Training, and Experience reconsidered
My guess is that managers in a range of fields have long had a itch in the back of their minds that they weren’t always hiring the right people. Specifically, they were eliminating large swaths of applicants from the pool of consideration because they lacked the minimum formal education or years of narrowly defined experience. A lot of these requirements, I suspect, existed not as tried and true markers of the subset of optimal candidates, but because they could be routinized through online job applications and human resources triage, largely in an effort to conserve on managerial and administrative time. Combined CYA incentives and other sources of herding behavior both within and across firms (i.e. no one gets fired for only hiring college graduates), these are exactly that kind of sub-optimal practices that can widely embed themselves when an economy is growing, but the labor market is relatively loose, so any suboptimality is lost in the wash.
A negative labor shock, be it a military draft or global pandemic, is exactly the kind of thing that rewards firms that begin hiring from whole strata of previously unconsidered job candidates. Not for nothing, that’s how you end learning all kinds of new things: the relative value of various degrees and training, the cross-applicability of job experience previously treated as irrelevant to an open position, and the marginal products of a firms employment portfolio.
2. Compensation bundles rebalanced
There’s plenty of fuss (rightly so) over the shift towards working from home. Yes, it saves on fixed costs, particularly in cities with sky-high commercial real estate costs, but I suspect the greater impact in the long run will be on the composition of wages+benefits+flexibility in employee compensation bundles, where flexibility is largely a catch-all for the quality of life component associated with any job. Maybe we already knew that health insurance and paid leave were valuable, but I think a lot of employees have discovered they were previously undervaluing the costs of commuting, schedule uncertainty, and existing “on call” for co-workers and superiors. Whether its working from home or as an independent contractor, many people are discovering that recapturing 10 hours a week of the rest of your life is worth a lot more than the wages being foregone. We already know that women are the future, but we also know that women value flexibility in work schedules more than men. A shift towards quality of life in compensation bundles was likely already in the cards, the pandemic just accelerated it.
For firms that have spent the last 20 years burning out the handful of key employees, rewarding their exceptional productivity by turning them into productivity bottlenecks, they are either going to have to find a way to spread the work thinner or recapture those key employees by finding other means of maintaining the quality of their employee lives.
3. The service industry is dead. Long live the service industry?
We’ve been eating on borrowed time. Through the combination of over-priced and over-valued higher education, a gratuitous over-stigmatization of non-violent criminal records, and the employment trap of limited human capital building, but lots of cash in hand, the service industry has been feeding us all on the cheap for a very long time now.
Turns out, though, that the relative frugality of diners has squeezed margins in restaurants razor thin, and has largely come at the expense of servers and kitchen staff. Came at the expense, I should say. I think we’re all going to have find a new normal where outsourcing meal preparation is, at the margin, slightly less of a staple and slightly more of a luxury. I still see Help Needed signs in lots of restaurants, and owners complaining in news stories that “No one wants to work“, but I’m also seeing new employees bring home higher salaries at McDonald’s after 90 days than fine dining cooks in their 3rd year working sauté. Eventually the new equilibrium will be reached, and I predict it’s going to involve higher salaries and better benefits for line cooks, but it’s also going to mean customers are going to have to get over there perceived $28 ceiling on entrees. Also, don’t expect your favorite restaurants to be open on Monday’s and Tuesdays, because it turns out everyone wants to have weekend.
4. The same, but different
What will the labor market look like in 5 years? Forecasting is a fool’s errand, but I never promised anyone I wasn’t a fool. Here’s my best guess:
I don’t expect a revival of unionization, but I do expect that employment will start taking on a lot of the attributes that pro-union people are currently agitating for. There will be more people with 3 and 4-day work weeks, though I suspect those people will be working 10 and 12 hour shifts. I think there will be a lot of flexible office-home work schedules, where firms coordinate their employees around days when everyone is in the office, the rest floating between the office and home as the work dictates. I expect there will be more independent contractors, but unlike previously self-employed people who bounced from contract to contract, they will instead be people who balance a portfolio of employment, with what amounts a small number of long term contracts. Rather than work for one person at a time 40 hours a week, they’ll work for 2 or 3, 8-10 hours each, building up enough firm-specific capital that contracts will last years, even decades, at a time.
I expect kitchens will remain hot, crowded, and loud. I expect chef’s will remain angry and owner’s tight-fisted with every penny. I expect that servers will still finish every shift with sore feet and stories of annoying customers. Maybe even more annoying than before, because those customer’s will be paying 15% more than the prices they already manage to complain about. But it’ll be okay, because everyone in that restaurant is going to be earning a much better living. They’ll have to, because otherwise they’re not coming back.