I have previously wrote about living standards in Ireland, and how GDP per capita overstates typical incomes because of a lot of foreign investment.
This is not to say that foreign investment is bad — to the contrary! But standard income statistics, such as GDP, aren’t particularly useful for a country like Ireland.
Norway has a similar challenge with national income statistics, but a different reason: Oil. Norway has a very large supply of oil revenues relative to the size of the rest of its economy, and oil revenues are counted in GDP. But those oil revenues don’t necessarily translate into higher household income or consumption.
Using World Bank data, Norway appears to be very rich: GDP per capita in nominal terms was about $90,000 in 2021. Compare that with $70,000 in the US, which is a very rich country itself. Sounds extremely wealthy!
Of course, by that same statistic, average income in Ireland is $100,000. But after making all the proper adjustments, as we saw in my prior post, Ireland is right around the EU average in terms of what individuals and households actually consume.
I am pleased to announce that my paper “Willingness to be Paid: Who Trains for Tech Jobs?” has been accepted at Labour Economics.
Having a larger high-skill workforce increases productivity, so it is useful to understand how workers self-select into high-paying technology (tech) jobs. This study examines how workers decide whether or not to pursue tech, through an experiment in which subjects are offered a short programming job. I will highlight some results on gender and preferences in this post.
Most of the subjects in the experiment are college students. They started by filling out a survey that took less than 15 minutes. They could indicate whether or not they would like an invitation for returning again to do computer programming.
Subjects indicate whether they would like an invitation to return to do a one-hour computer programming job for $15, $25, $35, …, or $85.[1]This is presented as 9 discrete options, such as:
“I would like an invitation to do the programming task if I will be paid $15, $25, $35, $45, $55, $65, $75 or $85.”,
or,
“I would like an invitation to do the programming task if I will be paid $85. If I draw a $15, $25, $35, $45, $55, $65 or $75 then I will not receive an invitation.”,
and the last choice is
“I would not like to receive an invitation for the programming task.”
Ex-ante, would you expect a gender gap in the results? In 2021, there was only 1 female employee working in a tech role at Google for every 3 male tech employees. Many technical or IT roles exhibit a gender gap.
To find a gender gap in this experiment would mean female subjects reject the programming follow-up job or at least they would have a different reservation wage. In economics, the reservation wage is the lowest wage an employee would accept to continue doing their job. I might have observed that women were willing to program but would reject the low wage levels. If that had occurred, then the implication would be that there are more men available to do the programming job for any given wage level.
However, the male and female participants behaved in very similar ways. There was no significant difference in reservation wages or in the choice to reject the follow-up invitation to program. The average reservation wage for the initial experiment was very close to $25 for both males and females. A small number of male subjects said they did not want to be invited back at even the highest wage level. In the initial experiment, 5% of males and 6% of females refused the programming job.
The experiment was run in 3 different ways, partly to test the robustness of this (lack of) gender effect. About 100 more subjects were recruited online through Prolific to observe a non-traditional subject pool. Details are in the paper.
Ex-ante, given the obvious gender gap in tech companies, there were several reasons to expect a gender gap in the experiment, even on a college campus. Ex-post, readers might decide that I left something out of the design that would have generated a gender gap. This experiment involves a short-term individual task. Maybe the team culture or the length of the commitment is what deters women from tech jobs. I hope that my experiment is a template that researchers can build on. Maybe even a small change in the format would cause us to observe a gender gap. If that can be established, then that would be a major contribution to an important puzzle.
For the decisions that involved financial incentives, I observed no significant gender gaps in the study. However, subjects answered other questions and there are gender gaps for some of the self-reported answers. It was much more likely that women would answer “Yes” to the question
If you were to take a job in a tech field, do you expect that you would face discrimination or harassment?
I observed that women said they were less confident if you just asked them if they are “confident”. However, when I did an incentivized belief elicitation about performance on a programming quiz, women appear quite similar to men.
Since wages are high for tech jobs, why aren’t more people pursing them? The answer to that question is complex. It does not all boil down to subjective preferences for technical tasks, however in my results enjoyment is one of the few variables that was significant.
People who say they enjoy programming are significantly more likely to do it at any given wage level, in this experiment.
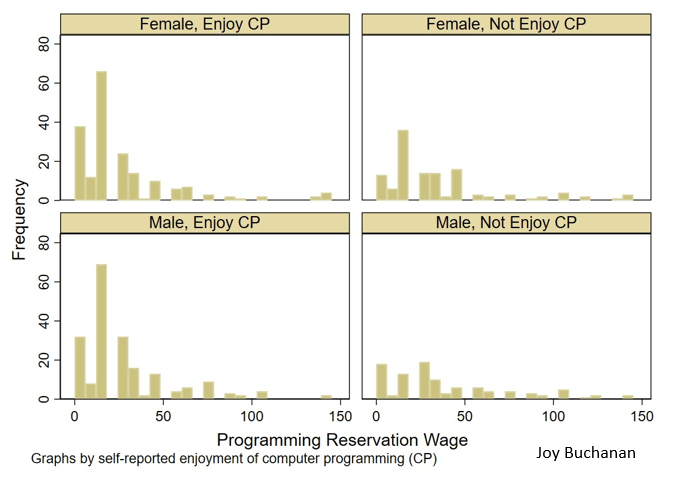
Fig. 3 Histogram of reservation wage for programming job, by reported enjoyment of computer programming (CP) and gender, pooling all treatments and samples
Figure 3 from the paper shows the reservation wage of participates from all three waves. Subjects who say that they enjoy programming usually pick a reservation wage at or near the lowest possible level. This pattern is quite similar whether you are considering males or females.
Interestingly, enjoyment mattered more than some of the other factors that I though would predict willingness to participate. About half of subjects said they had taken a class that taught them some coding, but that factor did not predict their behavior in the experiment. Enjoyment or subjective preferences seemed to matter more than training. To my knowledge, policy makers talk a lot about training and very little about these subjective factors. I hope my experiment helps us understand what is happening when people self-select into tech. Later, I will write another blog about the treatment manipulation and results, and perhaps I will have the official link to the article by then.
Buchanan, Joy. “Willingness to be Paid: Who Trains for Tech Jobs.” Labour Economics.
[1] We use a quasi-BDM to obtain a view of the labor supply curve at many different wages. The data is not as granulated as that which a traditional Becker-DeGroot-Marschak (BDM) mechanism obtains, but it is easy for subjects to understand. The BDM, while being theoretically appropriate for this purpose, has come under suspicion for being difficult for inexperienced subjects to understand (Cason and Plott, 2014). We follow Bartling et al. (2015) and use a discrete version.
Last week I wrote about wealth growth during the pandemic, but my favorite way to look at wealth data is comparing different generations. Last September I wrote a post comparing Boomers, Gen Xers, and Millennials in wealth per capita at roughly the same age. At the time, Millennials were basically equal to Gen X at the same age, and we were a year short of having comparable data with Boomers.
What does it look like if we update the chart through the second quarter of this year?
I won’t explain all of the data in detail — for that see my post from last September. I’ll just note a few changes. We now have single-year population estimates for 2020 and 2021, so I’ve updated those to the most recent Census estimates for each cohort. Inflation adjustments are to June 2022, to match the end of the most recent quarter of data from the Fed DFA. We still have to use average wealth rather than median wealth for now, but the Fed SCF is currently in progress so at some point we’ll have 2022 median data (most recent currently is 2019, and there’s been a lot of wealth growth since then).
What do we notice in the chart? First, we now have one year of overlap between Boomers and Millennials. And it turns out… they are pretty much at the same level per capita! Millennials have also now fallen slightly behind Gen X at the same time, since they’ve had no wealth growth (in real, per capita terms) since the end of 2021 to the present.
But Millennials have fared much better in 2022 with the massive drop in wealth: about $6.6 trillion in total wealth in the US was lost (in nominal terms) from the first to the second quarter of 2022. None of that wealth loss was among Millennials, instead it was roughly evenly shared among the three older generations (Boomers hid hardest). This difference is largely because Millennials hold more assets in real estate (which went up) than in equities (which went way down). The other generations have much more exposure to the stock market at this point in their life.
You can clearly see that affect of the 2022 wealth decline if you look at the end of the line for Gen X. You can’t see the effect on Boomers, since I cut off the chart after the last Gen X comparable data, but they saw a big decline since 2021 as well: about 6% per capita, along with 7% for Gen X. Even so, Gen X is still about 18% wealthier on average than Boomers were at the same age.
Of course, even since the end of the second quarter of 2022, we’ve seen further declines in the stock market, with the S&P 500 down about 4%. And who knows what the next few months and quarters will bring. But as of right now, Millennials don’t seem to be doing much worse than their counterparts in other generations at the same age.
Yesterday Federal Reserve researcher Nathan Blascak presented a paper at my Economics Seminar Series that was a surprise hit, with the audience staying over 40 minutes past the end to keep asking questions. So today I’ll share some highlights from the paper, “Decomposing Gender Differences in Bankcard Credit Limits”.
The challenge here is that its hard to get data that includes both gender and credit card limits (its illegal to use gender as a basis for allocating credit, so credit card companies don’t keep data on it, as they don’t want to be suspected of using it). The paper is original for managing to do so, by merging three different datasets. But even this merged data only lets them do this for a fairly specific subgroup- Americans who hold a mortgage solely in their name (not jointly with a spouse). Even this limited data, though, is quite illuminating.
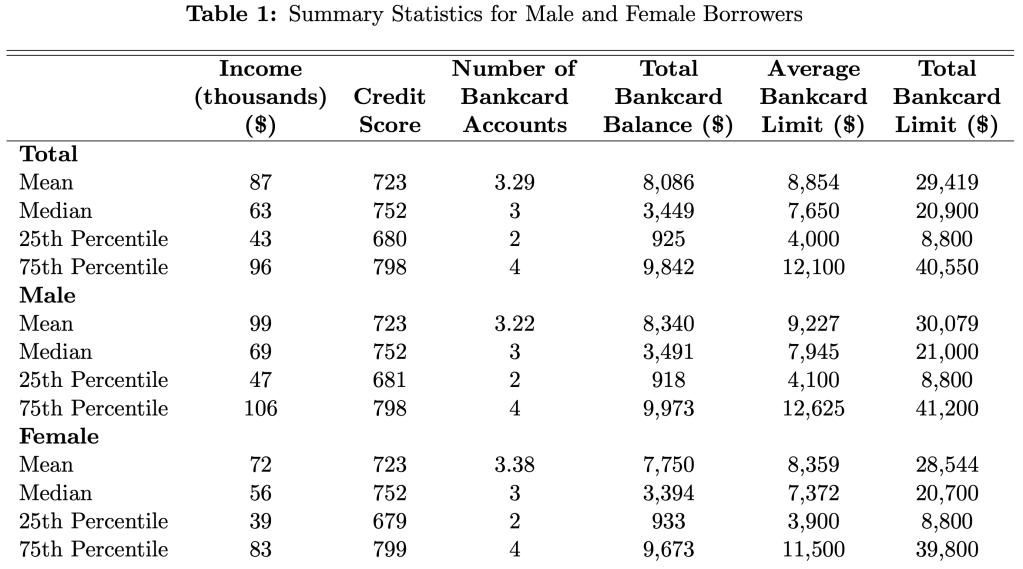
Their headline result is that men have 4.5% higher credit limits than women. Women actually have slightly more credit cards (3.38 vs 3.22), but have lower limits on each card; summing up their total credit limit across all cards yields an average of $28,544 for women vs $30,079 for men.
Two of the big factors that determine limits, and so could cause this difference, are credit scores and income. The table above shows that men and women have remarkably similar credit scores, while men have higher incomes. Still, when the paper tries to predict credit limits, controlling for credit scores, incomes, and other observables explains only about 13% of the gender gap.
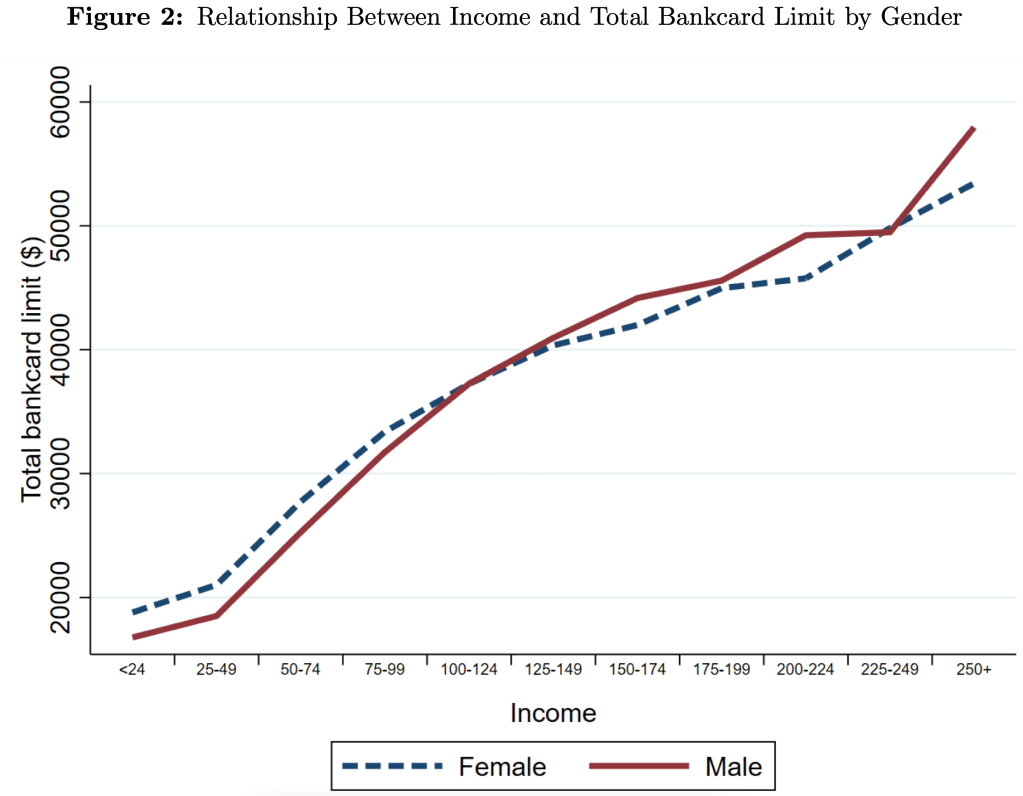
Men have 4.5% higher credit limits on average, but this difference varies a lot across the distribution. For credit scores, the gap is narrow in the middle but bigger at the extremes. For income, we see that men get higher limits at higher incomes, but women actually get higher limits at lower incomes- and not just “low incomes”, women do better all the way up to $100,000/yr:
The papers data covers 2006-2018, so they also show all sorts of interesting trends. The average number of credit cards held by men and women plunged after the 2008 recession and remains well below the peak. Total credit limits plunged too, though they were almost totally recovered by 2018.
There’s lots more in the paper, which is a great example of the value of descriptive work with new data. If anything I’d like to see the authors push even harder on the distribution angle. Its nice to see how limits vary across all incomes and credit scores, but why not show the full distribution of credit card limits by gender? My guess is that the 1st and 99th percentiles are very interesting places, because there’s all sorts of crazy behavior at the extremes. Finally, I wonder if higher limits are actually a good thing once you get beyond a relatively low amount- do you know of anyone who ever had a good reason to get their personal credit card balances over $20,000?
In the US wealth distribution, which group has seen the largest increase in wealth during the pandemic? A recent working paper by Blanchet, Saez, and Zucman attempts to answer that question with very up-to-date data, which they also regularly update at RealTimeInequality.org. As they say on TV, the answer may shock you: it’s the bottom 50%. At least if we are looking at the change in percentage terms, the bottom 50% are clearly the winners of the wealth race during the pandemic.
Average wealth of the bottom 50% increased by over 200 percent since January 2020, while for the entire distribution it was only 20 percent, with all the other groups somewhere between 15% and 20%. That result is jaw-dropping on its own. Of course, it needs some context.
Part of what’s going on here is that average wealth at the bottom was only about $4,000 pre-pandemic (inflation adjusted), while today it’s somewhere around $12,000. In percentage terms, that’s a huge increase. In dollar terms? Not so much. Contrast this with the Top 0.01%. In percentage terms, their growth was the lowest among these slices of the distribution: only 15.8%. But that amounts to an additional $64 million of wealth per adult in the Top 0.01%. Keeping percentage changes and level changes separate in your mind is always useful.
Still, I think it’s useful to drill down into the wealth gains of the bottom 50% to see where all this new wealth is coming from. In total, there was about $2 trillion of nominal wealth gains for the bottom 50% from the first quarter of 2020 to the first quarter of 2022. Where did it come from?
No matter how you feel about intelligent machines, you’ll be talking to them soon.
Talking to voice assistants right now feels stilted because it's slow, inaccurate, and you can't interrupt.
Widely-available high-quality fast ASR and TTS, paired with LLMs, is coming soon and will enable much more natural conversations. https://t.co/8UQP5YRZ5l
This restaurant has several robots delivering food and drinks to tables. It’s strange at first but easy to get used to. The robots can tolerate people walking in front of them and mild harassment from children. pic.twitter.com/F47IcPqruU
From the recent CPI inflation report, one of the biggest challenges for most households is the continuing increase in the price of food, especially “food at home” or what we usually call groceries. Prices of Groceries are up 13.5% in the past 12 months, an eye-popping number that we haven’t seen since briefly in 1979 was only clearly worse in 1973-74. Grocery prices are now over 20% greater than at the beginning of the pandemic in 2020. Any relief consumers feel at the pump from lower gas prices is being offset in other areas, notably grocery inflation.
The very steep recent increase in grocery prices is especially challenging for consumers because, not only are they basic necessities, if we look over the past 10 years we clearly see that consumer had gotten used to stable grocery prices.
The chart above shows the CPI component for groceries. Notice that from January 2015 to January 2020, there was no increase in grocery prices on average. Even going back to January 2012, the increase over the following 8 years was minimal. Keep in mind these nominal prices. I haven’t made any adjustment for wages or income! (If you know me, you know that’s coming next.) Almost a decade of flat grocery prices, and then boom!, double digit inflation.
But what if we compare grocery prices to wages? That trend becomes even more stark. I use the average wage for non-supervisory workers, as well as an annual grocery cost from the Consumer Expenditure Survey (for the middle quintile of income), to estimate how many hours a typical worker would need to work to purchase a family’s annual groceries. (I’ve truncated the y-axis to show more detail, not to trick you: it doesn’t start at zero.)
Raising kids is expensive. As an economist, we’re used to thinking about cost very broadly, including the opportunity cost of your time. Indeed, a post I wrote a few weeks ago focused on the fact that parents are spending more time with their kids than in decades past. But I want to focus on one aspect of the cost, which is what most “normal” people mean by “cost”: the financial cost.
Conveniently, the USDA has periodically put out reports that estimate the cost of raising a child. Their headline measure is for a middle-income, married couple with two children. Unfortunately the last report was issued in 2017, for a child born in 2015. And in the past 2 years, we know that the inflation picture has changed dramatically, so those old estimates may not necessarily reflect reality anymore. In fact, researchers at the Brookings Institution recently tried to update that 2015 data with the higher inflation we’ve experienced since 2020. In short, they assumed that from 2021 forward inflation will average 4% per year for the next decade (USDA assumed just over 2%).
Doing so, of course, will raise the nominal cost of raising a child. And that’s what their report shows: in nominal terms, the cost of raising a child born in 2015 will now be $310,605 through age 17, rather than $284,594 as the original report estimated. The original report also has a lower figure: $233,610. That’s the cost of raising that child in 2015 inflation-adjusted dollars.
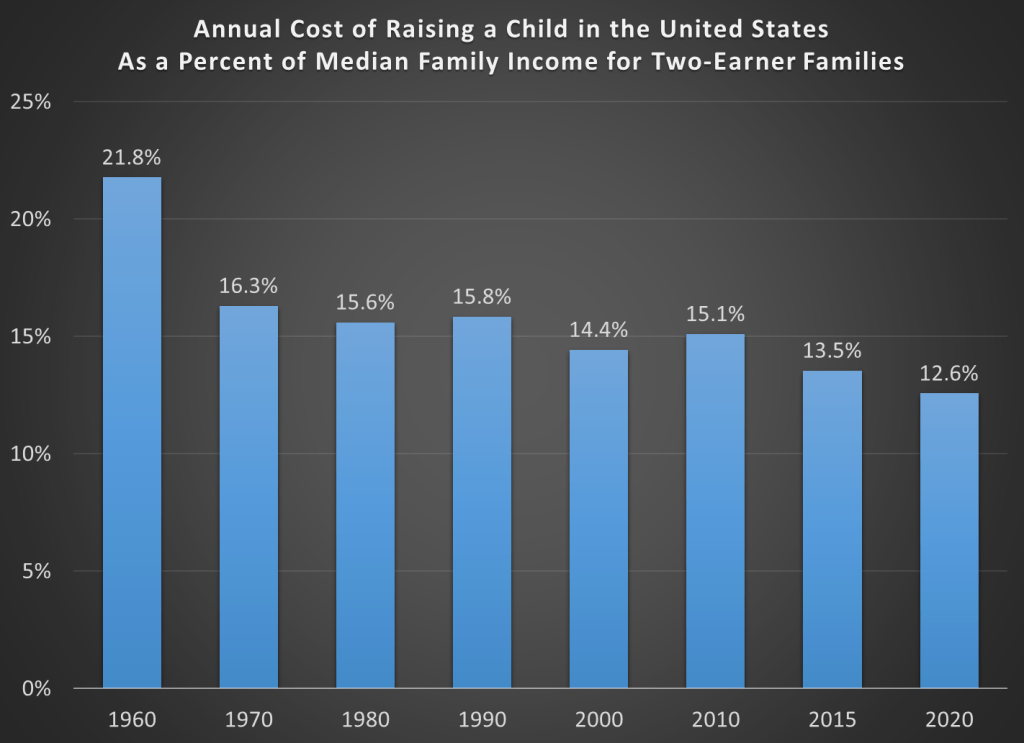
As I’ve written several times before on this blog, adjusting for inflation can be tricky. In fact, sometimes we don’t actually need to do it! To see if it is more or less expensive to raise a child than in the past, what we can do instead is compare to the cost to some measure of income. I will look at several measures of income and wages in this post, but let me start with the one I think is the best: median family income for a family with two earners. Why do I think this is best? Because the USDA and Brookings cost estimates are for married couples who are also paying for childcare. To me, this suggests a two-earner family is ideal (you may disagree, but please read on).
Here’s the data. Income figures come from Census. Child costs are from USDA reports in 1960-2015, and the Brookings update in 2020.
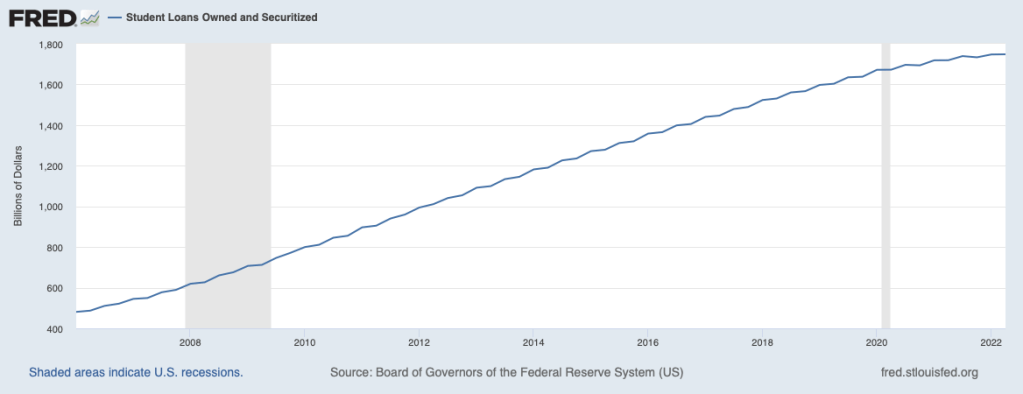
Yesterday the Biden administration announced that is forgiving up to $20k per person in student debt. So far we’ve seen lots of debate over whether this was a good/fair idea; as an economist who paid back his own debt early, you can probably guess what I have to say about that, so I’ll move on to the more interesting question of what happens now.
…after sharing one tweetOK one more, but I promise its relevant
The above is a quote from Thomas Sowell as a political commentator, but he was also a great economist. His book Applied Economics says that the essence of the economic approach to policy analysis is to not just consider the immediate effect, but instead to keep asking “and then what?” So let’s try that here.
We’ll start with the immediate effects. Those whose debt just fell will be happy, and will have more money to spend or save in other ways. The federal government is on the other side of this, they’ll receive less in debt payments and so will have to fund themselves in other ways like borrowing money or raising taxes. People are still trying to estimate how big this transfer from the government to student debtors is, but let’s take the Penn Wharton Budget Model estimate of $330 billion (the actual cost is likely higher, since that estimate is for $10k of loan forgiveness, but the actual program forgives up to $20k for those who had Pell grants). Dividing by US population tells you the cost is roughly $1000 per American; dividing by $10,000 tells you that roughly 33 million debtors benefit.
OK, what happens next? The big question is: is this a one-time thing, or does it make future loan forgiveness more or less likely? Later I’ll make the argument for why the answer could be “less”. But right now most people seem to think the answer is “more”, and that belief is what will be driving decisions.
If current and future students think loan forgiveness is likely, they have an incentive to take out more loans than they otherwise would, and to pay them off more slowly (particularly since income-based repayment was just cut from 10% to 5% of income). This higher willingness to pay from students gives colleges an incentive to raise tuition; historically about 60% of subsidized loans to students end up captured by colleges in the form of higher prices:
We find a pass-through effect on tuition of changes in subsidized loan maximums of about 60 cents on the dollar, and smaller but positive effects for unsubsidized federal loans. The subsidized loan effect is most pronounced for more expensive degrees, those offered by private institutions, and for two-year or vocational programs.
To the extent that you think student debt is a national problem, this action didn’t solve the problem so much as push it back 6 years; wiping out roughly 20% of all student debt brings us back to 2016 levels. So we could end up right back here in 2028, possibly faster to the extent that students borrow more as a result.
That, together with the “normalization” of student loan forgiveness, is why people think a similar action in the future is likely. But I’ll give two reasons it might not happen.
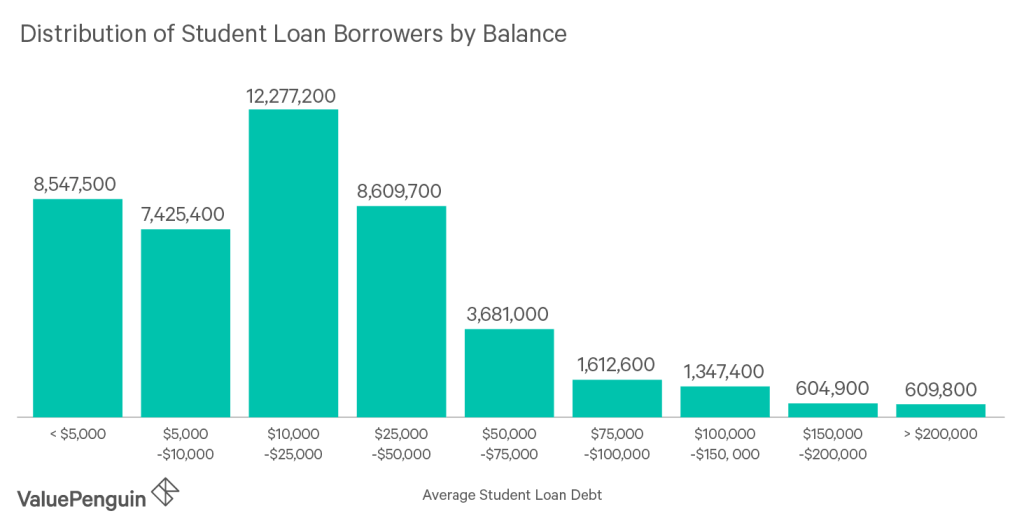
First, this action may have only reduced student debt by about 20%, but it reduced the number of student debtors much more (at least 36%), because most debtors owed relatively small amounts. It will take more than 6 years for the number of voters who’d benefit from loan forgiveness to get back to what it was in 2022, reducing support for forgiveness in the mean time.
That also gives Congress plenty of time to do something, even by their lethargic standards. Part of what bothers many people about this loan forgiveness is that it not only doesn’t solve the underlying issue of the Department of Education signing kids up for decades of debt, it will likely worsen the underlying issue through the moral hazard effect I describe above. Forgiveness would be much more popular if it were paired with reforms to solve the underlying issue. While we aren’t getting real reform now, I do think forgiveness makes it more likely that we’ll see reform in the next few years. What could that look like?
Let’s start with the libertarian solution, which of course won’t happen:
More realistic will be limits on where Federal loan money can be spent, and shared responsibility for colleges. Colleges and the government have spent decades pushing 18 year olds to sign up for huge amounts of debt. While I’d certainly like to see 18-year-olds act more responsibly and “just say no” to the pushers, the institutions bear most of the blame here. The Department of Education should raise its standards and stop offering loans to programs with high default rates or bad student outcomes. This should include not just fly-by-night colleges, but sketchy masters degree programs at prestigious schools.
Colleges should also share responsibility when they consistently saddle students with debt but don’t actually improve students’ prospects enough to be able to pay it back. Economists have put a lot of thought into how to do this in a manner that doesn’t penalize colleges simply for trying to teach less-prepared students.
I’d bet that some reform along these lines happens in the 2020’s, just like the bank bailouts of 2008 led to the Dodd-Frank reform of 2010 to try to prevent future bailouts. The big question is, will this be a pragmatic bipartisan reform to curb the worst offenders, or a Republican effort to substantially reduce the amount of money flowing to a higher ed sector they increasingly dislike?
In the past 20 years in the US, per pupil spending in K-12 schools has increased by about 20%. That’s in CPI-U inflation-adjusted dollars. What’s the cause of this increase? Higher teacher salaries? Administrative bloat? Something else?
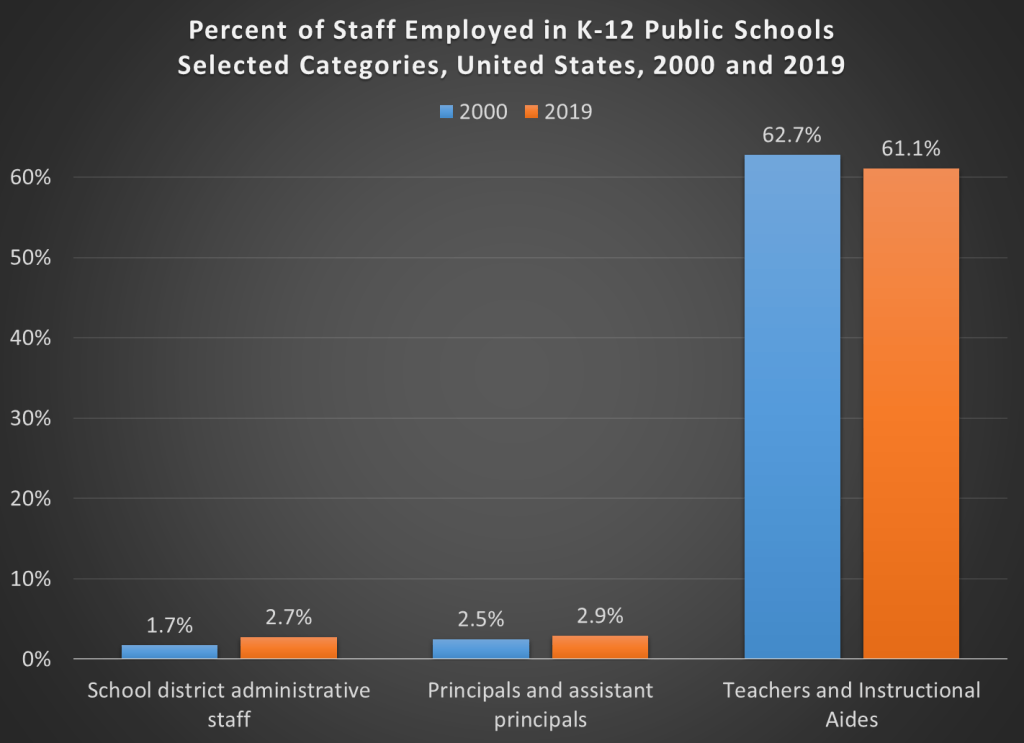
Here’s a chart you may have seen floating around the internet. It shows the growth in the number of employees at K-12 public schools.
But hold on, here’s another chart, showing the percent of employees in each of these same categories.
The numbers don’t add up to 100% because I’ve left off a few categories (the biggest one is “support staff,” which was 30-31% of the total throughout the time period). But overall, this chart appears to show much less bloat. Instructional staff (including aides) were by far the biggest category of employees in both categories in both time periods. Administrative staff at the district level did grow, but only by 1 percentage point of the total.
What’s the source of this data? Well, it’s a little trick I played. The source is the National Center for Education Statistic’s Digest of Education Statistics, Table 213.10. It’s the exact same data.