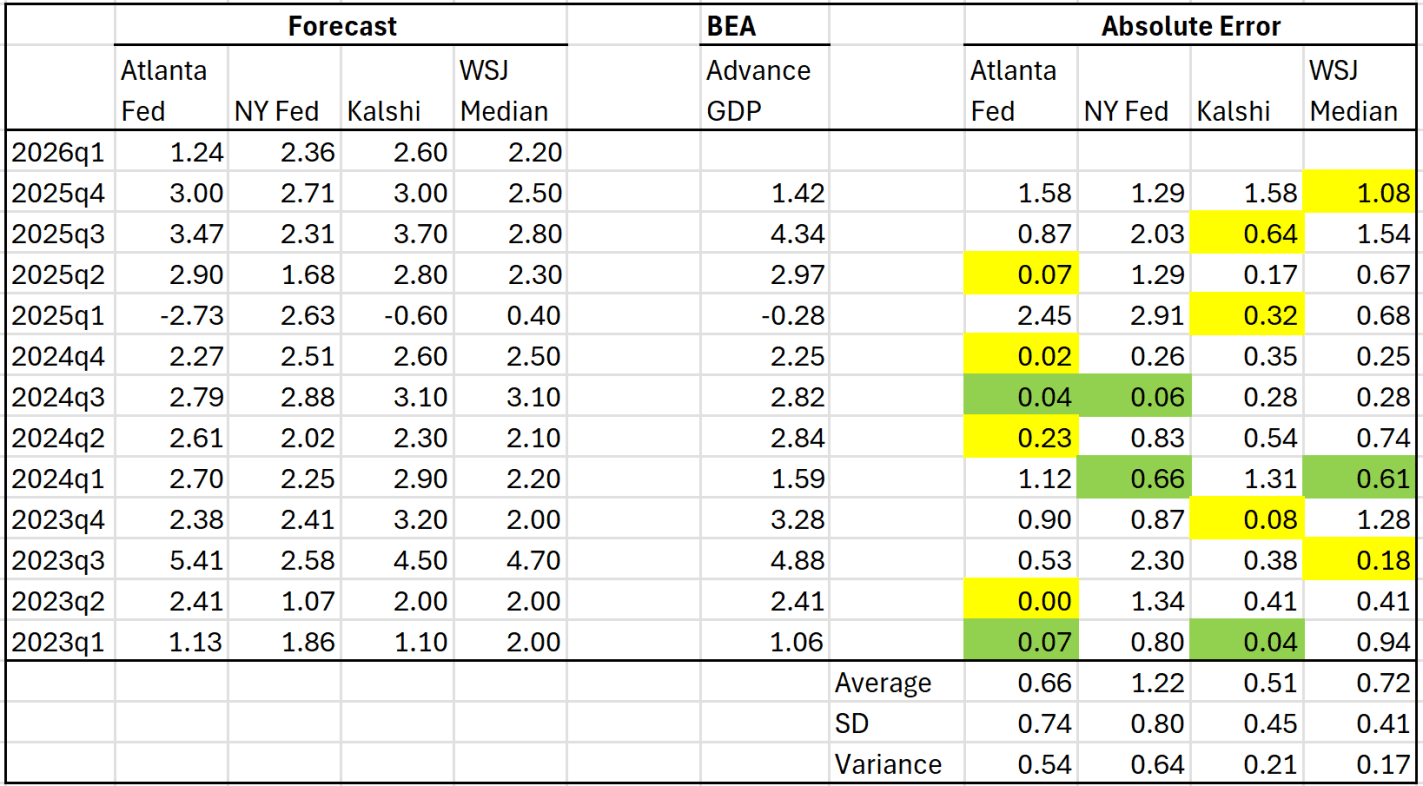
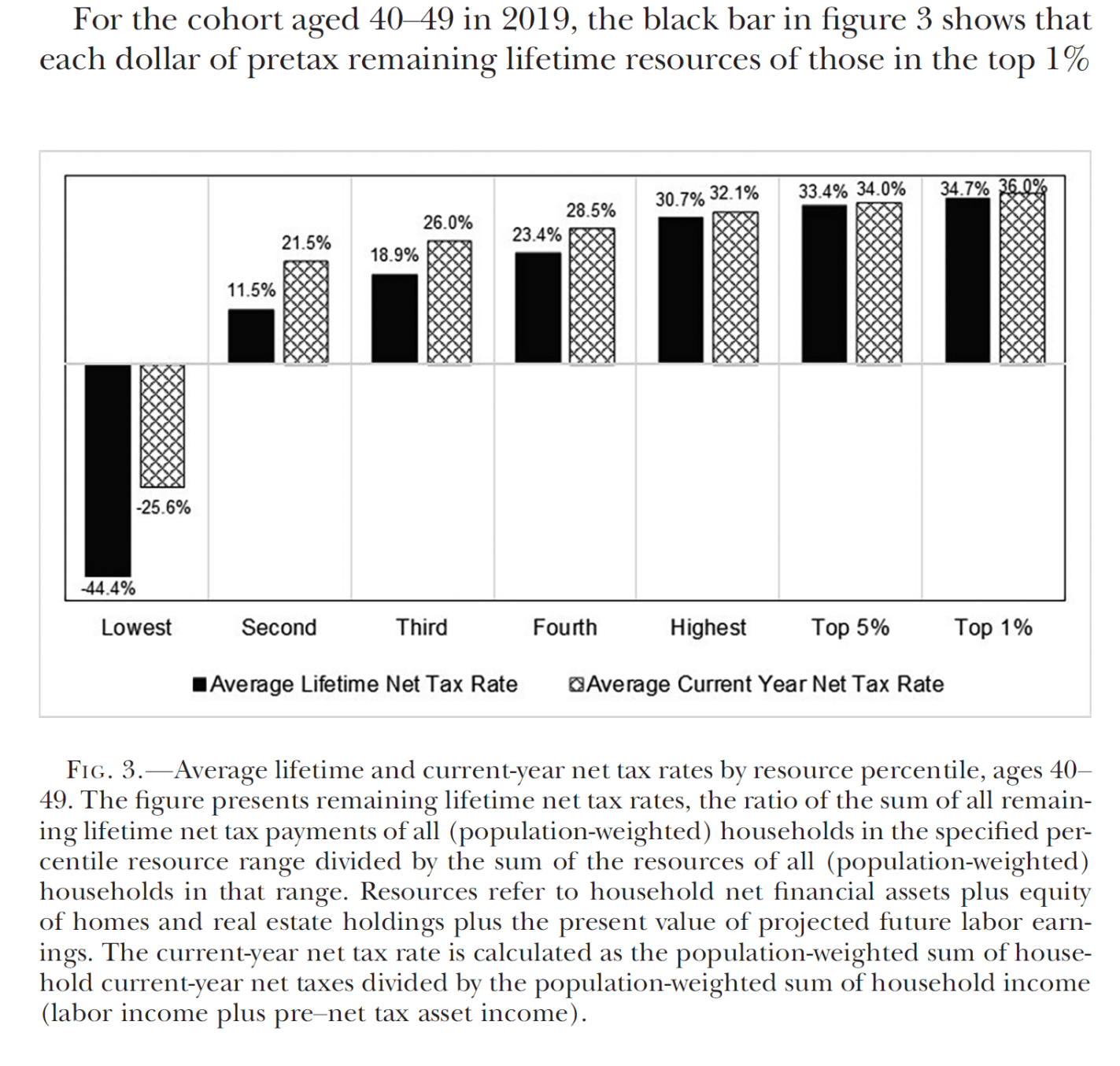
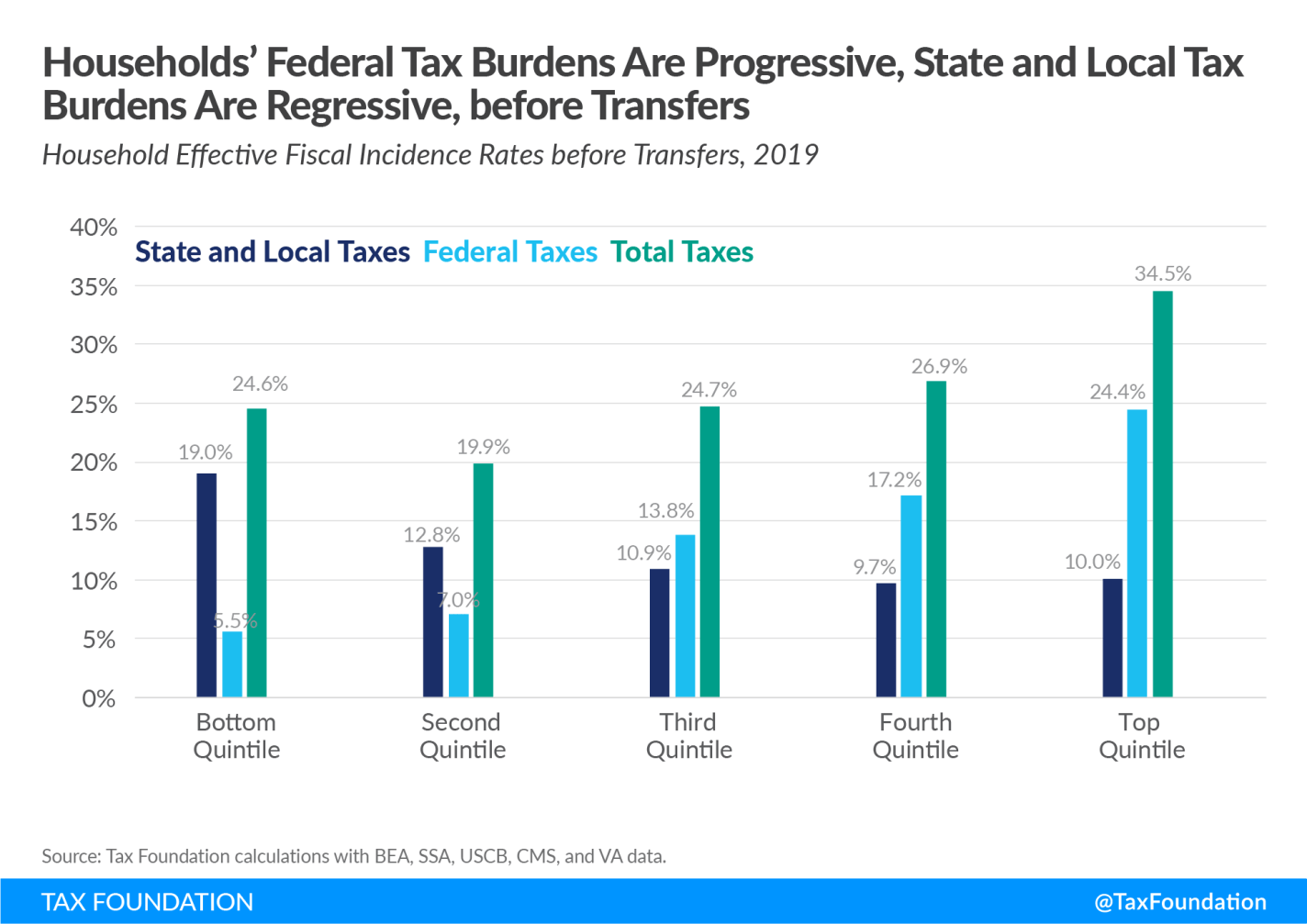
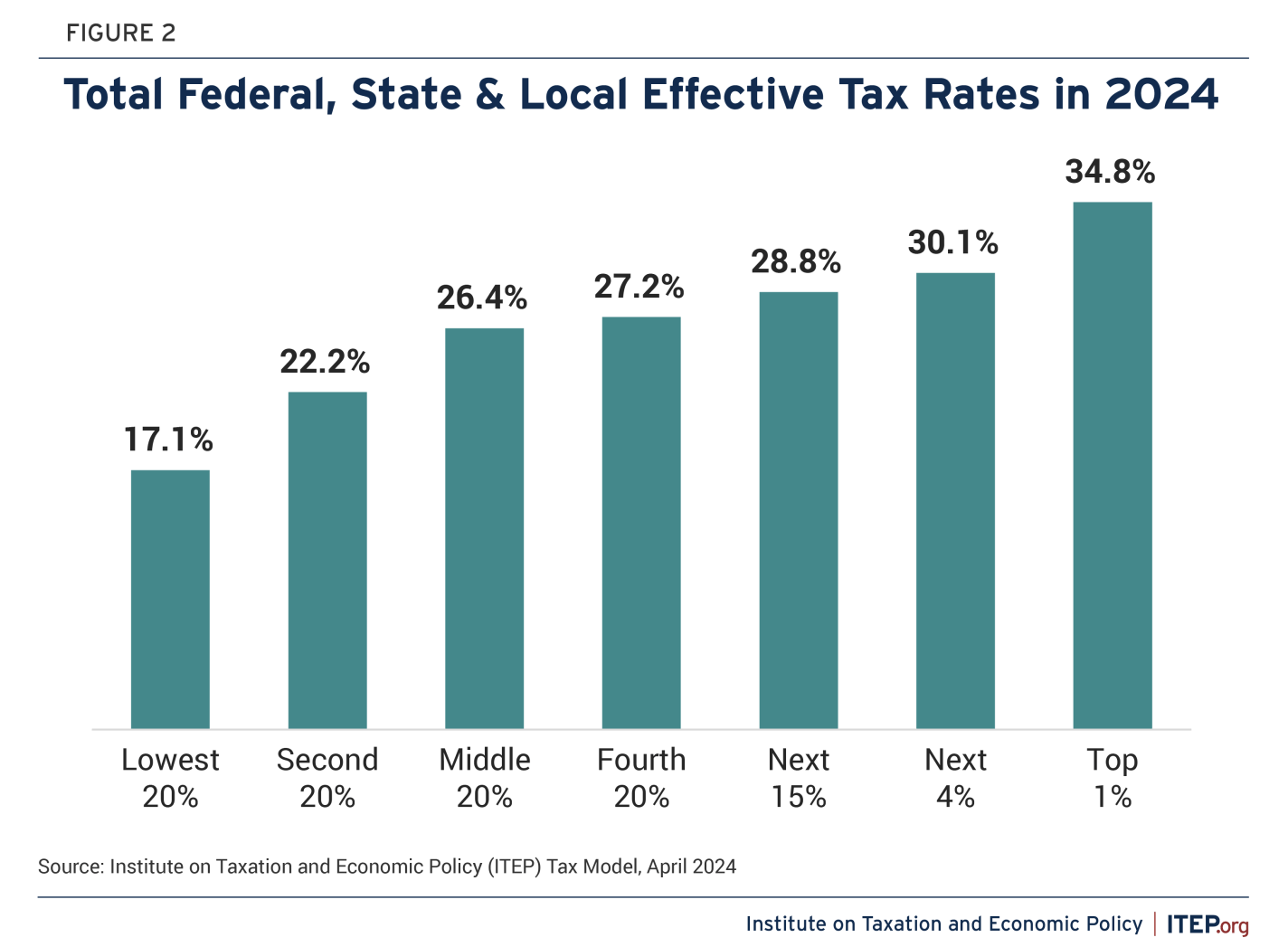
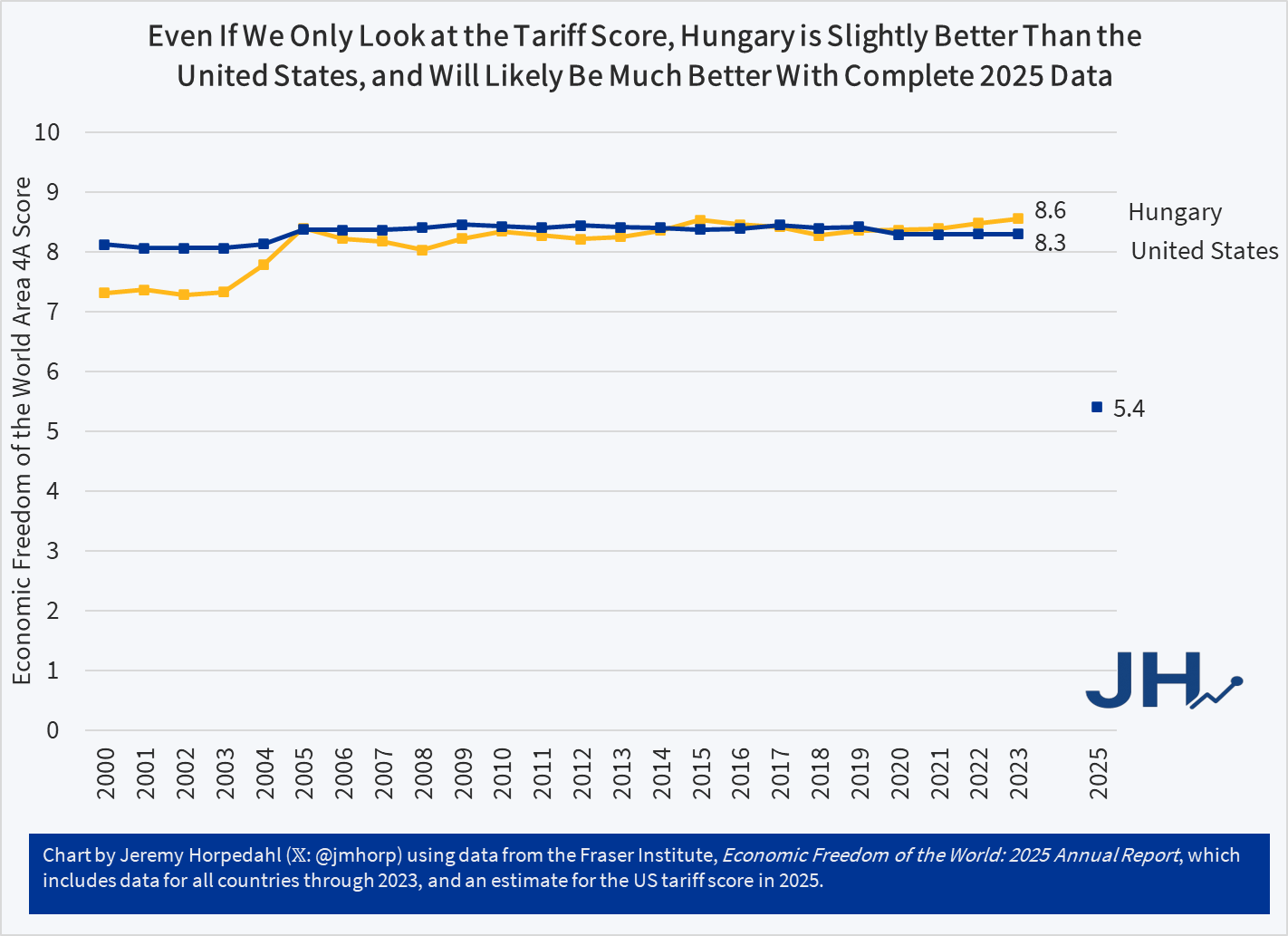
I was listening to an episode of The Deduction, a podcast by the Tax Foundation. As if that first sentence isn’t evident enough, I was reminded of how confusing taxes are – period. Even experts disagree and see grey areas. As I was listening, I thought “man, they need a graph”. So, here we are.
Income Tax Vocabulary
The money that you are paid by your employer is your gross income. Not all of it is taxable. You can deduct money from your gross income to get your taxable income. Most people subtract the ‘standard deduction’ from their gross income, which is how I’ll proceed in this post. Since the standard deduction for 2026 is $16,100 for a single earner, that means that your taxable income is $16,100 less than your gross income. By following a formula, one can calculate the amount of money that they must pay the government. These payments can be all at once, throughout the year, or even directly from your paycheck. The total that’s due to the government by April 15 is called the total tax liability. Finally, the money that the government doesn’t take, and that you get to keep, is called your net income. It’s your income net of taxes.
If you’ve had a job, then you are probably most familiar with your gross income, what your employer pays you, and your net income, what you get to take home. The steps in between might include some hand-waving.
Marginal Tax Rates
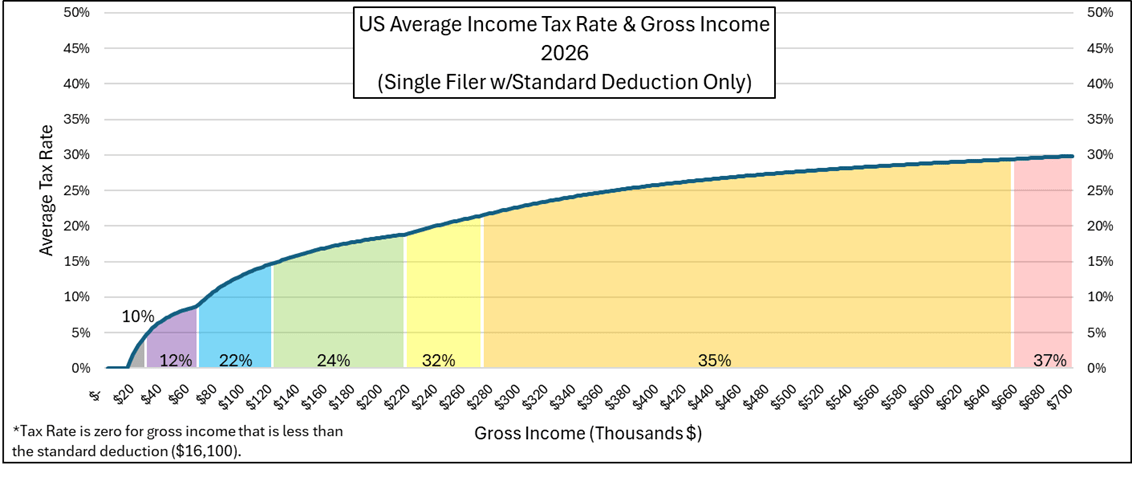
One of the most confusing pieces of the income tax code is marginal income taxes. Below are the brackets for 2026.
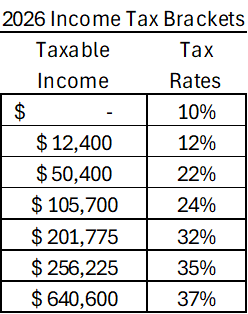
Marginal Tax rates work like this: Every dollar that you earn faces a tax rate. If your taxable income would be below zero, then you pay zero in taxes. But if your taxable income is $5k, then it gets taxed at a rate of 10%. That part should be pretty straightforward. But what if your taxable income is $15k? According to the table, you face a tax rate of 10% for dollars earned up to $12,400. That would be a tax liability of $1,240. But the remainder of your $15k in taxable income exists in the next tax bracket. That portion of your taxable income faces a tax rate of 12%. Sticking with the example, $2,600 is in the 12% tax bracket, so the tax liability for that portion of your taxable income is $312 (=$2.6k*0.12). Therefore, your total tax liability would be the sum of your tax liabilities across all applicable tax brackets: $1,552 (=$1,240+$312).
There are some features of marginal tax rates that are worth mentioning. Since the tax rates on the lower taxable income brackets don’t change, earning more gross income never reduces your net income unless the tax rate exceeds 100% (which it doesn’t here). So, when someone says that their taxable income is in the 35% tax rate bracket, they probably just mean that their last dollar earned is there. They’re only paying 35% on the taxable income that’s above $256,225. They’re not paying 35% of all earned dollars to the Internal Revenue Service (IRS).
Below is a graph that details the different marginal tax rates with shaded areas. The blue line is the average tax rate. It’s calculated by dividing the tax liability by the gross income. Even though one might earn an income that’s greater than $257k where the marginal tax rate is 35% or greater, the average tax rate remains lower, topping out at about 30% in this figure. The average tax rate is lower than an earner’s top marginal tax rate because the income in those lower brackets never disappears or get taxed at a higher rate.